 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthos: Rectifying Language Models in Orthogonal Parameter Space
Paper and Code
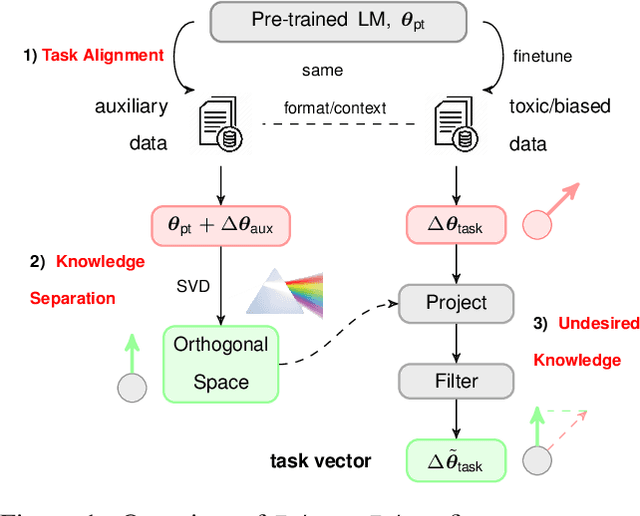
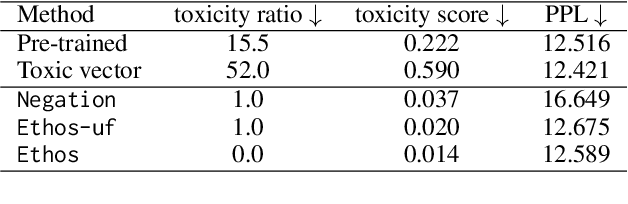
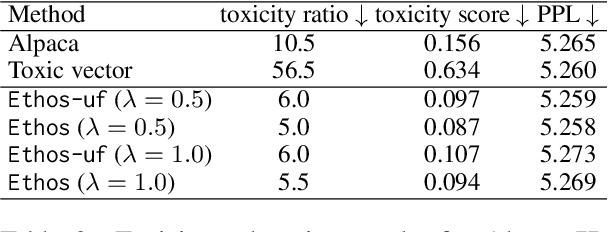
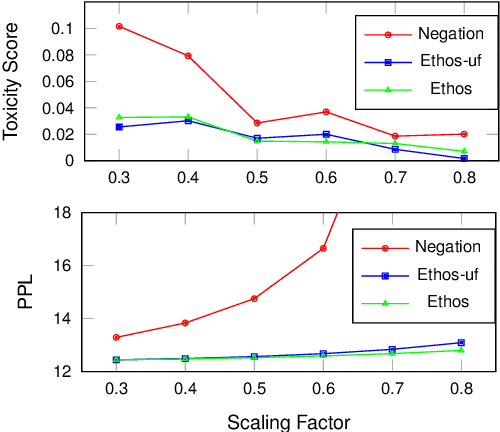
Language models (LMs) have greatly propelled the research on natural language processing. However, LMs also raise concerns regarding the generation of biased or toxic content and the potential disclosure of private information from the training dataset. In this work, we present a new efficient approach, Ethos, that rectifies LMs to mitigate toxicity and bias in outputs and avoid privacy leakage. Ethos is built on task arithmetic. However, unlike current task arithmetic algorithms, Ethos distinguishes general beneficial and undesired knowledge when reconstructing task vectors. Specifically, Ethos first obtains a set of principal components from the pre-trained models using singular value decomposition. Then, by projecting the task vector onto principal components, Ethos identifies the principal components that encode general or undesired knowledge. Ethos performs negating using the task vector with undesired knowledge only, thereby minimizing collateral damage on general model utility. We demonstrate the efficacy of our approach on three different tasks: debiasing, detoxification, and memorization unlearning. Evaluations show Ethos is more effective in removing undesired knowledge and maintaining the overall model performance compared to current task arithmetic methods.