 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Combinatorial Reasoning of GNNs via Graph Concept Bottleneck Layer
Mar 02, 2026Despite their success in various domains, the growing dependence on GNNs raises a critical concern about the nature of the combinatorial reasoning underlying their predictions, which is often hidden within their black-box architectures. Addressing this challenge requires understanding how GNNs translate topological patterns into logical rules. However, current works only uncover the hard logical rules over graph concepts, which cannot quantify the contribution of each concept to prediction. Moreover, they are post-hoc interpretable methods that generate explanations after model training and may not accurately reflect the true combinatorial reasoning of GNNs, since they approximate it with a surrogate. In this work, we develop a graph concept bottleneck layer that can be integrated into any GNN architectures to guide them to predict the selected discriminative global graph concepts. The predicted concept scores are further projected to class labels by a sparse linear layer. It enforces the combinatorial reasoning of GNNs' predictions to fit the soft logical rule over graph concepts and thus can quantify the contribution of each concept. To further improve the quality of the concept bottleneck, we treat concepts as "graph words" and graphs as "graph sentences", and leverage language models to learn graph concept embeddings. Extensive experiments on multiple datasets show that our method GCBMs achieve state-of-the-art performance both in classification and interpretability.
YOLO-DS: Fine-Grained Feature Decoupling via Dual-Statistic Synergy Operator for Object Detection
Jan 26, 2026One-stage object detection, particularly the YOLO series, strikes a favorable balance between accuracy and efficiency. However, existing YOLO detectors lack explicit modeling of heterogeneous object responses within shared feature channels, which limits further performance gains. To address this, we propose YOLO-DS, a framework built around a novel Dual-Statistic Synergy Operator (DSO). The DSO decouples object features by jointly modeling the channel-wise mean and the peak-to-mean difference. Building upon the DSO, we design two lightweight gating modules: the Dual-Statistic Synergy Gating (DSG) module for adaptive channel-wise feature selection, and the Multi-Path Segmented Gating (MSG) module for depth-wise feature weighting. On the MS-COCO benchmark, YOLO-DS consistently outperforms YOLOv8 across five model scales (N, S, M, L, X), achieving AP gains of 1.1% to 1.7% with only a minimal increase in inference latency. Extensive visualization, ablation, and comparative studies validate the effectiveness of our approach, demonstrating its superior capability in discriminating heterogeneous objects with high efficiency.
Supervised Learning for Analog and RF Circuit Design: Benchmarks and Comparative Insights
Jan 21, 2025Automating analog and radio-frequency (RF) circuit design using machine learning (ML) significantly reduces the time and effort required for parameter optimization. This study explores supervised ML-based approaches for designing circuit parameters from performance specifications across various circuit types, including homogeneous and heterogeneous designs. By evaluating diverse ML models, from neural networks like transformers to traditional methods like random forests, we identify the best-performing models for each circuit. Our results show that simpler circuits, such as low-noise amplifiers, achieve exceptional accuracy with mean relative errors as low as 0.3% due to their linear parameter-performance relationships. In contrast, complex circuits, like power amplifiers and voltage-controlled oscillators, present challenges due to their non-linear interactions and larger design spaces. For heterogeneous circuits, our approach achieves an 88% reduction in errors with increased training data, with the receiver achieving a mean relative error as low as 0.23%, showcasing the scalability and accuracy of the proposed methodology. Additionally, we provide insights into model strengths, with transformers excelling in capturing non-linear mappings and k-nearest neighbors performing robustly in moderately linear parameter spaces, especially in heterogeneous circuits with larger datasets. This work establishes a foundation for extending ML-driven design automation, enabling more efficient and scalable circuit design workflows.
AICircuit: A Multi-Level Dataset and Benchmark for AI-Driven Analog Integrated Circuit Design
Jul 22, 2024Analog and radio-frequency circuit design requires extensive exploration of both circuit topology and parameters to meet specific design criteria like power consumption and bandwidth. Designers must review state-of-the-art topology configurations in the literature and sweep various circuit parameters within each configuration. This design process is highly specialized and time-intensive, particularly as the number of circuit parameters increases and the circuit becomes more complex. Prior research has explored the potential of machine learning to enhance circuit design procedures. However, these studies primarily focus on simple circuits, overlooking the more practical and complex analog and radio-frequency systems. A major obstacle for bearing the power of machine learning in circuit design is the availability of a generic and diverse dataset, along with robust metrics, which are essential for thoroughly evaluating and improving machine learning algorithms in the analog and radio-frequency circuit domain. We present AICircuit, a comprehensive multi-level dataset and benchmark for developing and evaluating ML algorithms in analog and radio-frequency circuit design. AICircuit comprises seven commonly used basic circuits and two complex wireless transceiver systems composed of multiple circuit blocks, encompassing a wide array of design scenarios encountered in real-world applications. We extensively evaluate various ML algorithms on the dataset, revealing the potential of ML algorithms in learning the mapping from the design specifications to the desired circuit parameters.
Embracing Federated Learning: Enabling Weak Client Participation via Partial Model Training
Jun 21, 2024



In Federated Learning (FL), clients may have weak devices that cannot train the full model or even hold it in their memory space. To implement large-scale FL applications, thus, it is crucial to develop a distributed learning method that enables the participation of such weak clients. We propose EmbracingFL, a general FL framework that allows all available clients to join the distributed training regardless of their system resource capacity. The framework is built upon a novel form of partial model training method in which each client trains as many consecutive output-side layers as its system resources allow. Our study demonstrates that EmbracingFL encourages each layer to have similar data representations across clients, improving FL efficiency. The proposed partial model training method guarantees convergence to a neighbor of stationary points for non-convex and smooth problems. We evaluate the efficacy of EmbracingFL under a variety of settings with a mixed number of strong, moderate (~40% memory), and weak (~15% memory) clients, datasets (CIFAR-10, FEMNIST, and IMDB), and models (ResNet20, CNN, and LSTM). Our empirical study shows that EmbracingFL consistently achieves high accuracy as like all clients are strong, outperforming the state-of-the-art width reduction methods (i.e. HeteroFL and FjORD).
Ethos: Rectifying Language Models in Orthogonal Parameter Space
Apr 01, 2024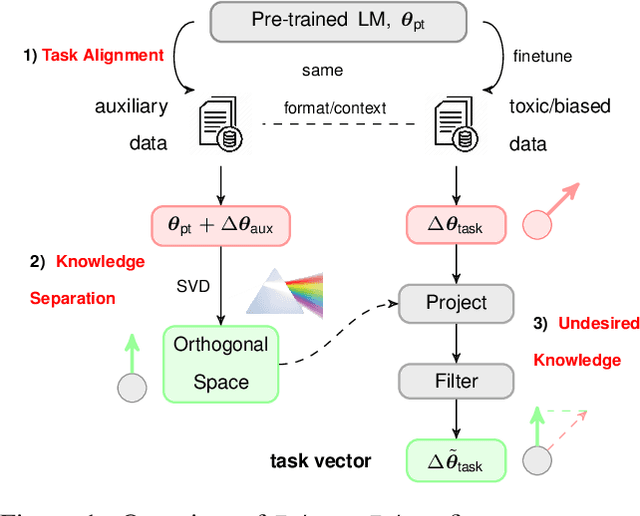
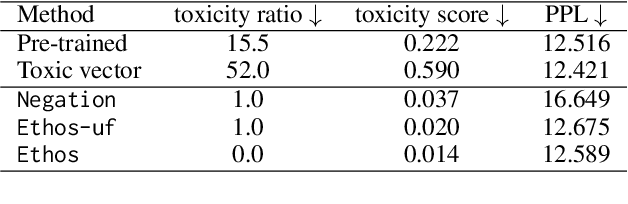
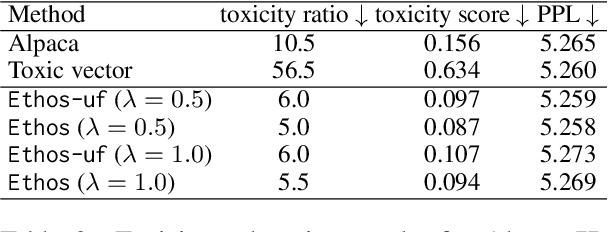
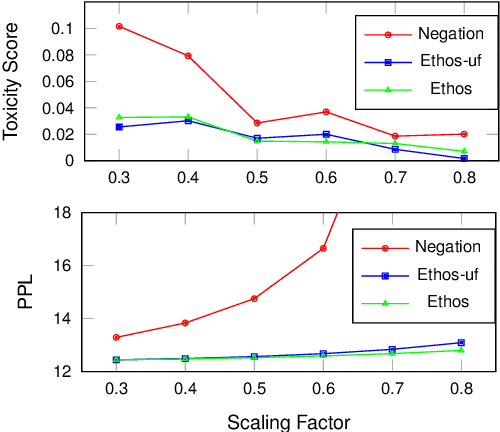
Language models (LMs) have greatly propelled the research on natural language processing. However, LMs also raise concerns regarding the generation of biased or toxic content and the potential disclosure of private information from the training dataset. In this work, we present a new efficient approach, Ethos, that rectifies LMs to mitigate toxicity and bias in outputs and avoid privacy leakage. Ethos is built on task arithmetic. However, unlike current task arithmetic algorithms, Ethos distinguishes general beneficial and undesired knowledge when reconstructing task vectors. Specifically, Ethos first obtains a set of principal components from the pre-trained models using singular value decomposition. Then, by projecting the task vector onto principal components, Ethos identifies the principal components that encode general or undesired knowledge. Ethos performs negating using the task vector with undesired knowledge only, thereby minimizing collateral damage on general model utility. We demonstrate the efficacy of our approach on three different tasks: debiasing, detoxification, and memorization unlearning. Evaluations show Ethos is more effective in removing undesired knowledge and maintaining the overall model performance compared to current task arithmetic methods.
Edge Private Graph Neural Networks with Singular Value Perturbation
Mar 16, 2024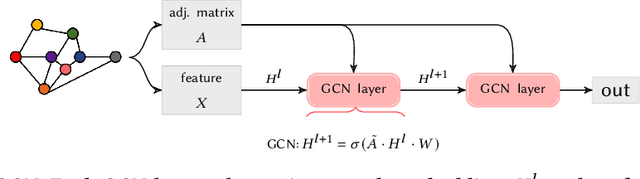
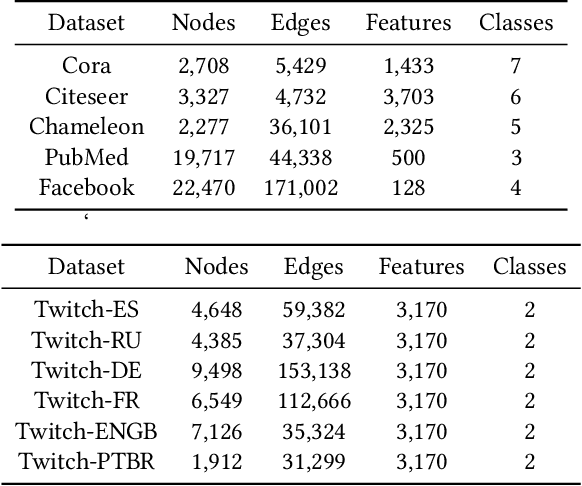
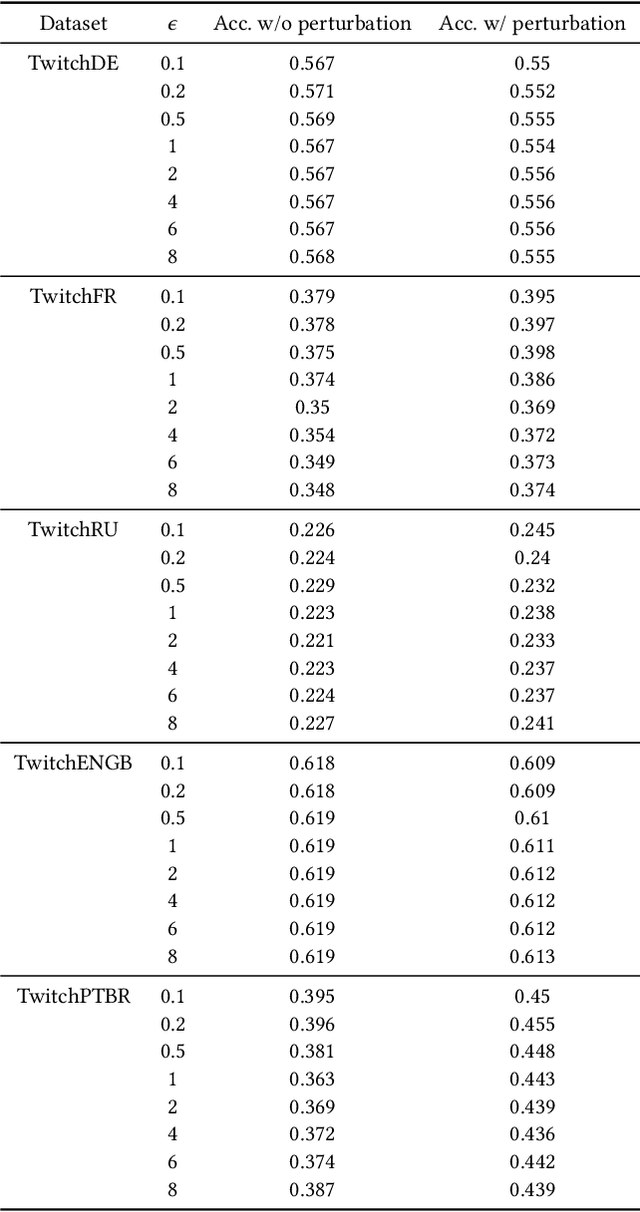
Graph neural networks (GNNs) play a key role in learning representations from graph-structured data and are demonstrated to be useful in many applications. However, the GNN training pipeline has been shown to be vulnerable to node feature leakage and edge extraction attacks. This paper investigates a scenario where an attacker aims to recover private edge information from a trained GNN model. Previous studies have employed differential privacy (DP) to add noise directly to the adjacency matrix or a compact graph representation. The added perturbations cause the graph structure to be substantially morphed, reducing the model utility. We propose a new privacy-preserving GNN training algorithm, Eclipse, that maintains good model utility while providing strong privacy protection on edges. Eclipse is based on two key observations. First, adjacency matrices in graph structures exhibit low-rank behavior. Thus, Eclipse trains GNNs with a low-rank format of the graph via singular values decomposition (SVD), rather than the original graph. Using the low-rank format, Eclipse preserves the primary graph topology and removes the remaining residual edges. Eclipse adds noise to the low-rank singular values instead of the entire graph, thereby preserving the graph privacy while still maintaining enough of the graph structure to maintain model utility. We theoretically show Eclipse provide formal DP guarantee on edges. Experiments on benchmark graph datasets show that Eclipse achieves significantly better privacy-utility tradeoff compared to existing privacy-preserving GNN training methods. In particular, under strong privacy constraints ($\epsilon$ < 4), Eclipse shows significant gains in the model utility by up to 46%. We further demonstrate that Eclipse also has better resilience against common edge attacks (e.g., LPA), lowering the attack AUC by up to 5% compared to other state-of-the-art baselines.
ATP: Enabling Fast LLM Serving via Attention on Top Principal Keys
Mar 01, 2024



We propose a new attention mechanism with linear complexity, ATP, that fixates \textbf{A}ttention on \textbf{T}op \textbf{P}rincipal keys, rather than on each individual token. Particularly, ATP is driven by an important observation that input sequences are typically low-rank, i.e., input sequences can be represented by a few principal bases. Therefore, instead of directly iterating over all the input tokens, ATP transforms inputs into an orthogonal space and computes attention only on the top principal bases (keys). Owing to the observed low-rank structure in input sequences, ATP is able to capture semantic relationships in input sequences with a few principal keys. Furthermore, the attention complexity is reduced from \emph{quadratic} to \emph{linear} without incurring a noticeable performance drop. ATP further reduces complexity for other linear layers with low-rank inputs, leading to more speedup compared to prior works that solely target the attention module. Our evaluations on various models (e.g., BERT and Llama) demonstrate that ATP achieves comparable accuracy with much lower computation and memory complexity than the standard attention mechanism. In particular, ATP barely loses accuracy with only $1/2$ principal keys, and only incurs around $2\%$ accuracy drops with $1/4$ principal keys.
All Rivers Run to the Sea: Private Learning with Asymmetric Flows
Dec 05, 2023



Data privacy is of great concern in cloud machine-learning service platforms, when sensitive data are exposed to service providers. While private computing environments (e.g., secure enclaves), and cryptographic approaches (e.g., homomorphic encryption) provide strong privacy protection, their computing performance still falls short compared to cloud GPUs. To achieve privacy protection with high computing performance, we propose Delta, a new private training and inference framework, with comparable model performance as non-private centralized training. Delta features two asymmetric data flows: the main information-sensitive flow and the residual flow. The main part flows into a small model while the residuals are offloaded to a large model. Specifically, Delta embeds the information-sensitive representations into a low-dimensional space while pushing the information-insensitive part into high-dimension residuals. To ensure privacy protection, the low-dimensional information-sensitive part is secured and fed to a small model in a private environment. On the other hand, the residual part is sent to fast cloud GPUs, and processed by a large model. To further enhance privacy and reduce the communication cost, Delta applies a random binary quantization technique along with a DP-based technique to the residuals before sharing them with the public platform. We theoretically show that Delta guarantees differential privacy in the public environment and greatly reduces the complexity in the private environment. We conduct empirical analyses on CIFAR-10, CIFAR-100 and ImageNet datasets and ResNet-18 and ResNet-34, showing that Delta achieves strong privacy protection, fast training, and inference without significantly compromising the model utility.
Reuse Kernels or Activations? A Flexible Dataflow for Low-latency Spectral CNN Acceleration
Oct 17, 2023Spectral-domain CNNs have been shown to be more efficient than traditional spatial CNNs in terms of reducing computation complexity. However they come with a `kernel explosion' problem that, even after compression (pruning), imposes a high memory burden and off-chip bandwidth requirement for kernel access. This creates a performance gap between the potential acceleration offered by compression and actual FPGA implementation performance, especially for low-latency CNN inference. In this paper, we develop a principled approach to overcoming this performance gap and designing a low-latency, low-bandwidth, spectral sparse CNN accelerator on FPGAs. First, we analyze the bandwidth-storage tradeoff of sparse convolutional layers and locate communication bottlenecks. We then develop a dataflow for flexibly optimizing data reuse in different layers to minimize off-chip communication. Finally, we propose a novel scheduling algorithm to optimally schedule the on-chip memory access of multiple sparse kernels and minimize read conflicts. On a state-of-the-art FPGA platform, our design reduces data transfers by 42\% with DSP utilization up to 90\% and achieves inference latency of 9 ms for VGG16, compared to the baseline state-of-the-art latency of 68 ms.