 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperphantasia: A Benchmark for Evaluating the Mental Visualization Capabilities of Multimodal LLMs
Jul 16, 2025



Mental visualization, the ability to construct and manipulate visual representations internally, is a core component of human cognition and plays a vital role in tasks involving reasoning, prediction, and abstraction. Despite the rapid progress of Multimodal Large Language Models (MLLMs), current benchmarks primarily assess passive visual perception, offering limited insight into the more active capability of internally constructing visual patterns to support problem solving. Yet mental visualization is a critical cognitive skill in humans, supporting abilities such as spatial navigation, predicting physical trajectories, and solving complex visual problems through imaginative simulation. To bridge this gap, we introduce Hyperphantasia, a synthetic benchmark designed to evaluate the mental visualization abilities of MLLMs through four carefully constructed puzzles. Each task is procedurally generated and presented at three difficulty levels, enabling controlled analysis of model performance across increasing complexity. Our comprehensive evaluation of state-of-the-art models reveals a substantial gap between the performance of humans and MLLMs. Additionally, we explore the potential of reinforcement learning to improve visual simulation capabilities. Our findings suggest that while some models exhibit partial competence in recognizing visual patterns, robust mental visualization remains an open challenge for current MLLMs.
Emergence and Evolution of Interpretable Concepts in Diffusion Models
Apr 21, 2025Diffusion models have become the go-to method for text-to-image generation, producing high-quality images from noise through a process called reverse diffusion. Understanding the dynamics of the reverse diffusion process is crucial in steering the generation and achieving high sample quality. However, the inner workings of diffusion models is still largely a mystery due to their black-box nature and complex, multi-step generation process. Mechanistic Interpretability (MI) techniques, such as Sparse Autoencoders (SAEs), aim at uncovering the operating principles of models through granular analysis of their internal representations. These MI techniques have been successful in understanding and steering the behavior of large language models at scale. However, the great potential of SAEs has not yet been applied toward gaining insight into the intricate generative process of diffusion models. In this work, we leverage the SAE framework to probe the inner workings of a popular text-to-image diffusion model, and uncover a variety of human-interpretable concepts in its activations. Interestingly, we find that even before the first reverse diffusion step is completed, the final composition of the scene can be predicted surprisingly well by looking at the spatial distribution of activated concepts. Moreover, going beyond correlational analysis, we show that the discovered concepts have a causal effect on the model output and can be leveraged to steer the generative process. We design intervention techniques aimed at manipulating image composition and style, and demonstrate that (1) in early stages of diffusion image composition can be effectively controlled, (2) in the middle stages of diffusion image composition is finalized, however stylistic interventions are effective, and (3) in the final stages of diffusion only minor textural details are subject to change.
Serpent: Scalable and Efficient Image Restoration via Multi-scale Structured State Space Models
Mar 26, 2024
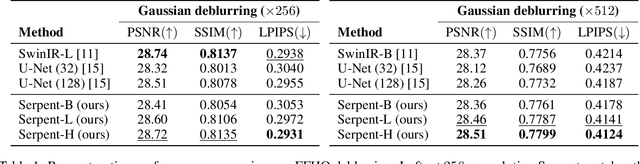
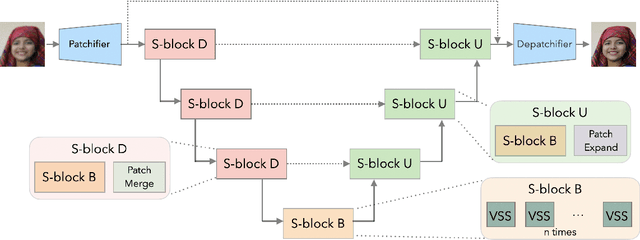

The landscape of computational building blocks of efficient image restoration architectures is dominated by a combination of convolutional processing and various attention mechanisms. However, convolutional filters are inherently local and therefore struggle at modeling long-range dependencies in images. On the other hand, attention excels at capturing global interactions between arbitrary image regions, however at a quadratic cost in image dimension. In this work, we propose Serpent, an architecture that leverages recent advances in state space models (SSMs) in its core computational block. SSMs, originally introduced for sequence modeling, can maintain a global receptive field with a favorable linear scaling in input size. Our preliminary results demonstrate that Serpent can achieve reconstruction quality on par with state-of-the-art techniques, while requiring orders of magnitude less compute (up to $150$ fold reduction in FLOPS) and a factor of up to $5\times$ less GPU memory while maintaining a compact model size.
A Data-Free Approach to Mitigate Catastrophic Forgetting in Federated Class Incremental Learning for Vision Tasks
Nov 21, 2023



Deep learning models often suffer from forgetting previously learned information when trained on new data. This problem is exacerbated in federated learning (FL), where the data is distributed and can change independently for each user. Many solutions are proposed to resolve this catastrophic forgetting in a centralized setting. However, they do not apply directly to FL because of its unique complexities, such as privacy concerns and resource limitations. To overcome these challenges, this paper presents a framework for $\textbf{federated class incremental learning}$ that utilizes a generative model to synthesize samples from past distributions. This data can be later exploited alongside the training data to mitigate catastrophic forgetting. To preserve privacy, the generative model is trained on the server using data-free methods at the end of each task without requesting data from clients. Moreover, our solution does not demand the users to store old data or models, which gives them the freedom to join/leave the training at any time. Additionally, we introduce SuperImageNet, a new regrouping of the ImageNet dataset specifically tailored for federated continual learning. We demonstrate significant improvements compared to existing baselines through extensive experiments on multiple datasets.
Multimodal Foundation Models for Zero-shot Animal Species Recognition in Camera Trap Images
Nov 02, 2023



Due to deteriorating environmental conditions and increasing human activity, conservation efforts directed towards wildlife is crucial. Motion-activated camera traps constitute an efficient tool for tracking and monitoring wildlife populations across the globe. Supervised learning techniques have been successfully deployed to analyze such imagery, however training such techniques requires annotations from experts. Reducing the reliance on costly labelled data therefore has immense potential in developing large-scale wildlife tracking solutions with markedly less human labor. In this work we propose WildMatch, a novel zero-shot species classification framework that leverages multimodal foundation models. In particular, we instruction tune vision-language models to generate detailed visual descriptions of camera trap images using similar terminology to experts. Then, we match the generated caption to an external knowledge base of descriptions in order to determine the species in a zero-shot manner. We investigate techniques to build instruction tuning datasets for detailed animal description generation and propose a novel knowledge augmentation technique to enhance caption quality. We demonstrate the performance of WildMatch on a new camera trap dataset collected in the Magdalena Medio region of Colombia.
Adapt and Diffuse: Sample-adaptive Reconstruction via Latent Diffusion Models
Sep 12, 2023Inverse problems arise in a multitude of applications, where the goal is to recover a clean signal from noisy and possibly (non)linear observations. The difficulty of a reconstruction problem depends on multiple factors, such as the structure of the ground truth signal, the severity of the degradation, the implicit bias of the reconstruction model and the complex interactions between the above factors. This results in natural sample-by-sample variation in the difficulty of a reconstruction task, which is often overlooked by contemporary techniques. Recently, diffusion-based inverse problem solvers have established new state-of-the-art in various reconstruction tasks. However, they have the drawback of being computationally prohibitive. Our key observation in this paper is that most existing solvers lack the ability to adapt their compute power to the difficulty of the reconstruction task, resulting in long inference times, subpar performance and wasteful resource allocation. We propose a novel method that we call severity encoding, to estimate the degradation severity of noisy, degraded signals in the latent space of an autoencoder. We show that the estimated severity has strong correlation with the true corruption level and can give useful hints at the difficulty of reconstruction problems on a sample-by-sample basis. Furthermore, we propose a reconstruction method based on latent diffusion models that leverages the predicted degradation severities to fine-tune the reverse diffusion sampling trajectory and thus achieve sample-adaptive inference times. We utilize latent diffusion posterior sampling to maintain data consistency with observations. We perform experiments on both linear and nonlinear inverse problems and demonstrate that our technique achieves performance comparable to state-of-the-art diffusion-based techniques, with significant improvements in computational efficiency.
mL-BFGS: A Momentum-based L-BFGS for Distributed Large-Scale Neural Network Optimization
Jul 25, 2023Quasi-Newton methods still face significant challenges in training large-scale neural networks due to additional compute costs in the Hessian related computations and instability issues in stochastic training. A well-known method, L-BFGS that efficiently approximates the Hessian using history parameter and gradient changes, suffers convergence instability in stochastic training. So far, attempts that adapt L-BFGS to large-scale stochastic training incur considerable extra overhead, which offsets its convergence benefits in wall-clock time. In this paper, we propose mL-BFGS, a lightweight momentum-based L-BFGS algorithm that paves the way for quasi-Newton (QN) methods in large-scale distributed deep neural network (DNN) optimization. mL-BFGS introduces a nearly cost-free momentum scheme into L-BFGS update and greatly reduces stochastic noise in the Hessian, therefore stabilizing convergence during stochastic optimization. For model training at a large scale, mL-BFGS approximates a block-wise Hessian, thus enabling distributing compute and memory costs across all computing nodes. We provide a supporting convergence analysis for mL-BFGS in stochastic settings. To investigate mL-BFGS potential in large-scale DNN training, we train benchmark neural models using mL-BFGS and compare performance with baselines (SGD, Adam, and other quasi-Newton methods). Results show that mL-BFGS achieves both noticeable iteration-wise and wall-clock speedup.
Don't Memorize; Mimic The Past: Federated Class Incremental Learning Without Episodic Memory
Jul 17, 2023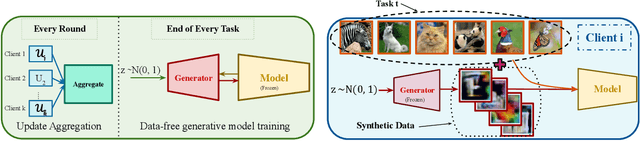



Deep learning models are prone to forgetting information learned in the past when trained on new data. This problem becomes even more pronounced in the context of federated learning (FL), where data is decentralized and subject to independent changes for each user. Continual Learning (CL) studies this so-called \textit{catastrophic forgetting} phenomenon primarily in centralized settings, where the learner has direct access to the complete training dataset. However, applying CL techniques to FL is not straightforward due to privacy concerns and resource limitations. This paper presents a framework for federated class incremental learning that utilizes a generative model to synthesize samples from past distributions instead of storing part of past data. Then, clients can leverage the generative model to mitigate catastrophic forgetting locally. The generative model is trained on the server using data-free methods at the end of each task without requesting data from clients. Therefore, it reduces the risk of data leakage as opposed to training it on the client's private data. We demonstrate significant improvements for the CIFAR-100 dataset compared to existing baselines.
DiracDiffusion: Denoising and Incremental Reconstruction with Assured Data-Consistency
Mar 25, 2023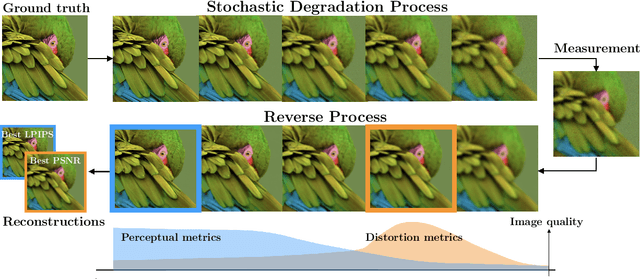
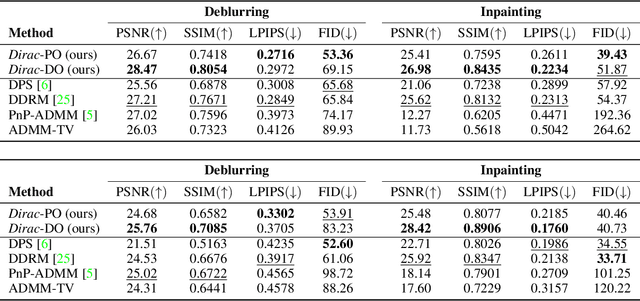
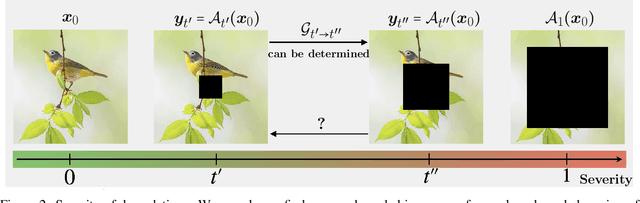
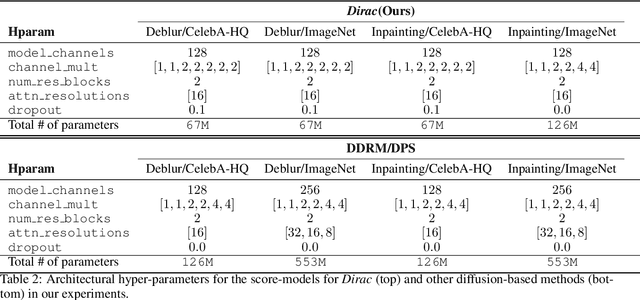
Diffusion models have established new state of the art in a multitude of computer vision tasks, including image restoration. Diffusion-based inverse problem solvers generate reconstructions of exceptional visual quality from heavily corrupted measurements. However, in what is widely known as the perception-distortion trade-off, the price of perceptually appealing reconstructions is often paid in declined distortion metrics, such as PSNR. Distortion metrics measure faithfulness to the observation, a crucial requirement in inverse problems. In this work, we propose a novel framework for inverse problem solving, namely we assume that the observation comes from a stochastic degradation process that gradually degrades and noises the original clean image. We learn to reverse the degradation process in order to recover the clean image. Our technique maintains consistency with the original measurement throughout the reverse process, and allows for great flexibility in trading off perceptual quality for improved distortion metrics and sampling speedup via early-stopping. We demonstrate the efficiency of our method on different high-resolution datasets and inverse problems, achieving great improvements over other state-of-the-art diffusion-based methods with respect to both perceptual and distortion metrics. Source code and pre-trained models will be released soon.
HUMUS-Net: Hybrid unrolled multi-scale network architecture for accelerated MRI reconstruction
Mar 15, 2022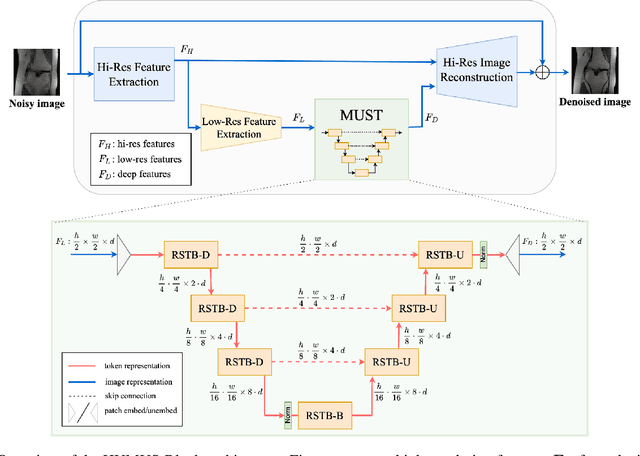


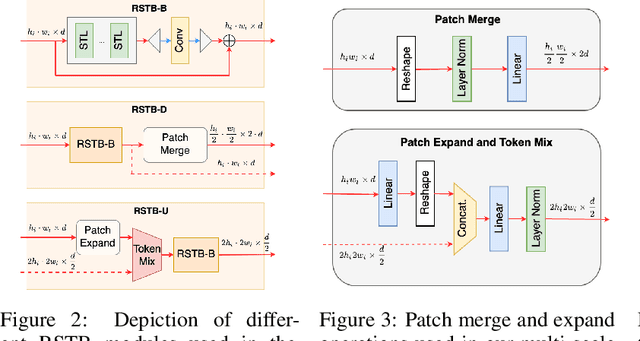
In accelerated MRI reconstruction, the anatomy of a patient is recovered from a set of under-sampled and noisy measurements. Deep learning approaches have been proven to be successful in solving this ill-posed inverse problem and are capable of producing very high quality reconstructions. However, current architectures heavily rely on convolutions, that are content-independent and have difficulties modeling long-range dependencies in images. Recently, Transformers, the workhorse of contemporary natural language processing, have emerged as powerful building blocks for a multitude of vision tasks. These models split input images into non-overlapping patches, embed the patches into lower-dimensional tokens and utilize a self-attention mechanism that does not suffer from the aforementioned weaknesses of convolutional architectures. However, Transformers incur extremely high compute and memory cost when 1) the input image resolution is high and 2) when the image needs to be split into a large number of patches to preserve fine detail information, both of which are typical in low-level vision problems such as MRI reconstruction, having a compounding effect. To tackle these challenges, we propose HUMUS-Net, a hybrid architecture that combines the beneficial implicit bias and efficiency of convolutions with the power of Transformer blocks in an unrolled and multi-scale network. HUMUS-Net extracts high-resolution features via convolutional blocks and refines low-resolution features via a novel Transformer-based multi-scale feature extractor. Features from both levels are then synthesized into a high-resolution output reconstruction. Our network establishes new state of the art on the largest publicly available MRI dataset, the fastMRI dataset. We further demonstrate the performance of HUMUS-Net on two other popular MRI datasets and perform fine-grained ablation studies to validate our design.