 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Mar 27, 2025Video generation has advanced significantly, evolving from producing unrealistic outputs to generating videos that appear visually convincing and temporally coherent. To evaluate these video generative models, benchmarks such as VBench have been developed to assess their faithfulness, measuring factors like per-frame aesthetics, temporal consistency, and basic prompt adherence. However, these aspects mainly represent superficial faithfulness, which focus on whether the video appears visually convincing rather than whether it adheres to real-world principles. While recent models perform increasingly well on these metrics, they still struggle to generate videos that are not just visually plausible but fundamentally realistic. To achieve real "world models" through video generation, the next frontier lies in intrinsic faithfulness to ensure that generated videos adhere to physical laws, commonsense reasoning, anatomical correctness, and compositional integrity. Achieving this level of realism is essential for applications such as AI-assisted filmmaking and simulated world modeling. To bridge this gap, we introduce VBench-2.0, a next-generation benchmark designed to automatically evaluate video generative models for their intrinsic faithfulness. VBench-2.0 assesses five key dimensions: Human Fidelity, Controllability, Creativity, Physics, and Commonsense, each further broken down into fine-grained capabilities. Tailored for individual dimensions, our evaluation framework integrates generalists such as state-of-the-art VLMs and LLMs, and specialists, including anomaly detection methods proposed for video generation. We conduct extensive annotations to ensure alignment with human judgment. By pushing beyond superficial faithfulness toward intrinsic faithfulness, VBench-2.0 aims to set a new standard for the next generation of video generative models in pursuit of intrinsic faithfulness.
EgoLife: Towards Egocentric Life Assistant
Mar 05, 2025We introduce EgoLife, a project to develop an egocentric life assistant that accompanies and enhances personal efficiency through AI-powered wearable glasses. To lay the foundation for this assistant, we conducted a comprehensive data collection study where six participants lived together for one week, continuously recording their daily activities - including discussions, shopping, cooking, socializing, and entertainment - using AI glasses for multimodal egocentric video capture, along with synchronized third-person-view video references. This effort resulted in the EgoLife Dataset, a comprehensive 300-hour egocentric, interpersonal, multiview, and multimodal daily life dataset with intensive annotation. Leveraging this dataset, we introduce EgoLifeQA, a suite of long-context, life-oriented question-answering tasks designed to provide meaningful assistance in daily life by addressing practical questions such as recalling past relevant events, monitoring health habits, and offering personalized recommendations. To address the key technical challenges of (1) developing robust visual-audio models for egocentric data, (2) enabling identity recognition, and (3) facilitating long-context question answering over extensive temporal information, we introduce EgoButler, an integrated system comprising EgoGPT and EgoRAG. EgoGPT is an omni-modal model trained on egocentric datasets, achieving state-of-the-art performance on egocentric video understanding. EgoRAG is a retrieval-based component that supports answering ultra-long-context questions. Our experimental studies verify their working mechanisms and reveal critical factors and bottlenecks, guiding future improvements. By releasing our datasets, models, and benchmarks, we aim to stimulate further research in egocentric AI assistants.
Video-MMMU: Evaluating Knowledge Acquisition from Multi-Discipline Professional Videos
Jan 23, 2025



Humans acquire knowledge through three cognitive stages: perceiving information, comprehending knowledge, and adapting knowledge to solve novel problems. Videos serve as an effective medium for this learning process, facilitating a progression through these cognitive stages. However, existing video benchmarks fail to systematically evaluate the knowledge acquisition capabilities in Large Multimodal Models (LMMs). To address this gap, we introduce Video-MMMU, a multi-modal, multi-disciplinary benchmark designed to assess LMMs' ability to acquire and utilize knowledge from videos. Video-MMMU features a curated collection of 300 expert-level videos and 900 human-annotated questions across six disciplines, evaluating knowledge acquisition through stage-aligned question-answer pairs: Perception, Comprehension, and Adaptation. A proposed knowledge gain metric, {\Delta}knowledge, quantifies improvement in performance after video viewing. Evaluation of LMMs reveals a steep decline in performance as cognitive demands increase and highlights a significant gap between human and model knowledge acquisition, underscoring the need for methods to enhance LMMs' capability to learn and adapt from videos.
Video Instruction Tuning With Synthetic Data
Oct 03, 2024



The development of video large multimodal models (LMMs) has been hindered by the difficulty of curating large amounts of high-quality raw data from the web. To address this, we propose an alternative approach by creating a high-quality synthetic dataset specifically for video instruction-following, namely LLaVA-Video-178K. This dataset includes key tasks such as detailed captioning, open-ended question-answering (QA), and multiple-choice QA. By training on this dataset, in combination with existing visual instruction tuning data, we introduce LLaVA-Video, a new video LMM. Our experiments demonstrate that LLaVA-Video achieves strong performance across various video benchmarks, highlighting the effectiveness of our dataset. We plan to release the dataset, its generation pipeline, and the model checkpoints.
LLaVA-OneVision: Easy Visual Task Transfer
Aug 06, 2024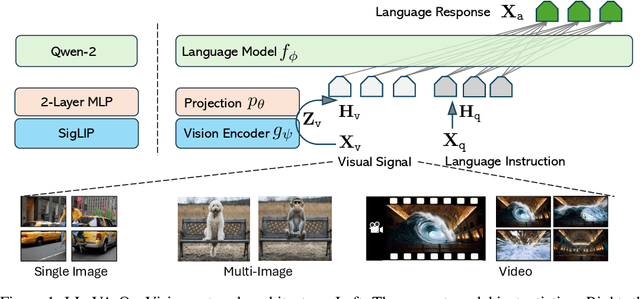



We present LLaVA-OneVision, a family of open large multimodal models (LMMs) developed by consolidating our insights into data, models, and visual representations in the LLaVA-NeXT blog series. Our experimental results demonstrate that LLaVA-OneVision is the first single model that can simultaneously push the performance boundaries of open LMMs in three important computer vision scenarios: single-image, multi-image, and video scenarios. Importantly, the design of LLaVA-OneVision allows strong transfer learning across different modalities/scenarios, yielding new emerging capabilities. In particular, strong video understanding and cross-scenario capabilities are demonstrated through task transfer from images to videos.
LMMs-Eval: Reality Check on the Evaluation of Large Multimodal Models
Jul 17, 2024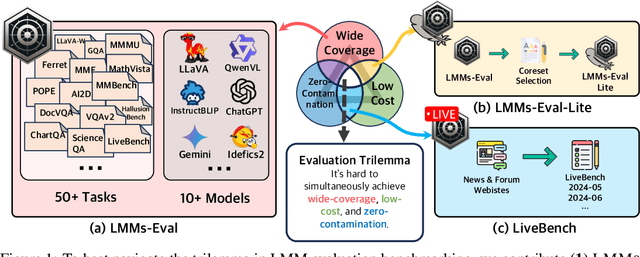
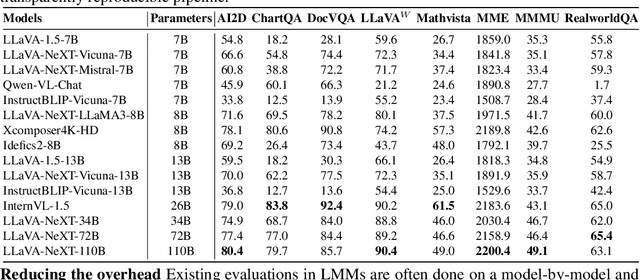
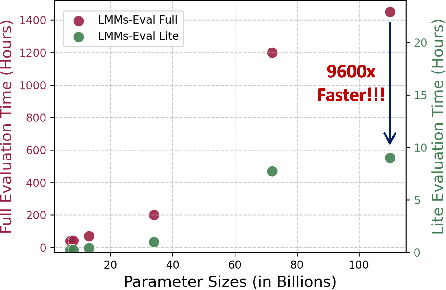
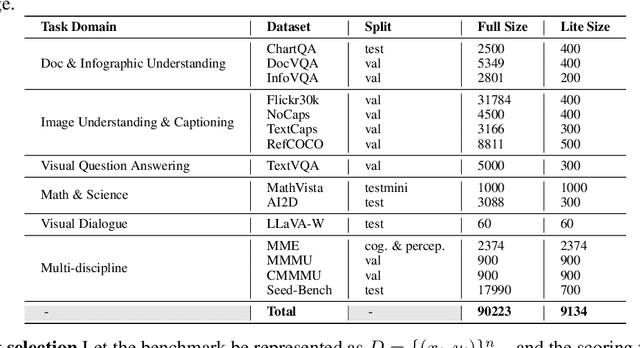
The advances of large foundation models necessitate wide-coverage, low-cost, and zero-contamination benchmarks. Despite continuous exploration of language model evaluations, comprehensive studies on the evaluation of Large Multi-modal Models (LMMs) remain limited. In this work, we introduce LMMS-EVAL, a unified and standardized multimodal benchmark framework with over 50 tasks and more than 10 models to promote transparent and reproducible evaluations. Although LMMS-EVAL offers comprehensive coverage, we find it still falls short in achieving low cost and zero contamination. To approach this evaluation trilemma, we further introduce LMMS-EVAL LITE, a pruned evaluation toolkit that emphasizes both coverage and efficiency. Additionally, we present Multimodal LIVEBENCH that utilizes continuously updating news and online forums to assess models' generalization abilities in the wild, featuring a low-cost and zero-contamination evaluation approach. In summary, our work highlights the importance of considering the evaluation trilemma and provides practical solutions to navigate the trade-offs in evaluating large multi-modal models, paving the way for more effective and reliable benchmarking of LMMs. We opensource our codebase and maintain leaderboard of LIVEBENCH at https://github.com/EvolvingLMMs-Lab/lmms-eval and https://huggingface.co/spaces/lmms-lab/LiveBench.
LLaVA-NeXT-Interleave: Tackling Multi-image, Video, and 3D in Large Multimodal Models
Jul 10, 2024



Visual instruction tuning has made considerable strides in enhancing the capabilities of Large Multimodal Models (LMMs). However, existing open LMMs largely focus on single-image tasks, their applications to multi-image scenarios remains less explored. Additionally, prior LMM research separately tackles different scenarios, leaving it impossible to generalize cross scenarios with new emerging capabilities. To this end, we introduce LLaVA-NeXT-Interleave, which simultaneously tackles Multi-image, Multi-frame (video), Multi-view (3D), and Multi-patch (single-image) scenarios in LMMs. To enable these capabilities, we regard the interleaved data format as a general template and compile the M4-Instruct dataset with 1,177.6k samples, spanning 4 primary domains with 14 tasks and 41 datasets. We also curate the LLaVA-Interleave Bench to comprehensively evaluate the multi-image performance of LMMs. Through extensive experiments, LLaVA-NeXT-Interleave achieves leading results in multi-image, video, and 3D benchmarks, while maintaining the performance of single-image tasks. Besides, our model also exhibits several emerging capabilities, e.g., transferring tasks across different settings and modalities. Code is available at https://github.com/LLaVA-VL/LLaVA-NeXT
Long Context Transfer from Language to Vision
Jun 24, 2024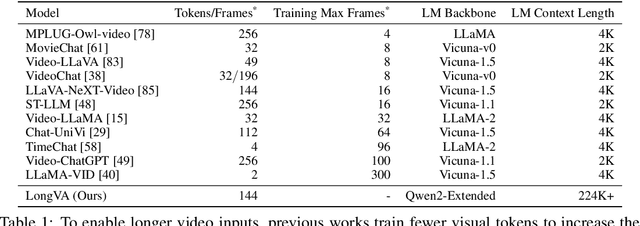
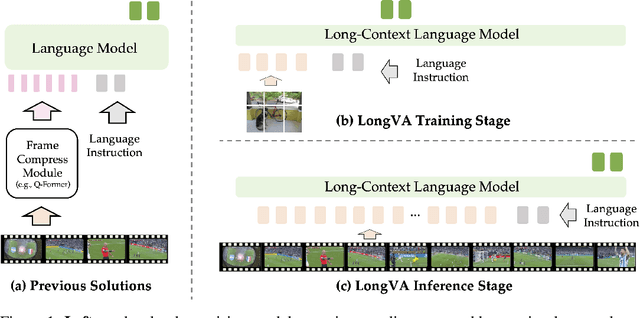


Video sequences offer valuable temporal information, but existing large multimodal models (LMMs) fall short in understanding extremely long videos. Many works address this by reducing the number of visual tokens using visual resamplers. Alternatively, in this paper, we approach this problem from the perspective of the language model. By simply extrapolating the context length of the language backbone, we enable LMMs to comprehend orders of magnitude more visual tokens without any video training. We call this phenomenon long context transfer and carefully ablate its properties. To effectively measure LMMs' ability to generalize to long contexts in the vision modality, we develop V-NIAH (Visual Needle-In-A-Haystack), a purely synthetic long vision benchmark inspired by the language model's NIAH test. Our proposed Long Video Assistant (LongVA) can process 2000 frames or over 200K visual tokens without additional complexities. With its extended context length, LongVA achieves state-of-the-art performance on Video-MME among 7B-scale models by densely sampling more input frames. Our work is open-sourced at https://github.com/EvolvingLMMs-Lab/LongVA.
WorldQA: Multimodal World Knowledge in Videos through Long-Chain Reasoning
May 06, 2024



Multimodal information, together with our knowledge, help us to understand the complex and dynamic world. Large language models (LLM) and large multimodal models (LMM), however, still struggle to emulate this capability. In this paper, we present WorldQA, a video understanding dataset designed to push the boundaries of multimodal world models with three appealing properties: (1) Multimodal Inputs: The dataset comprises 1007 question-answer pairs and 303 videos, necessitating the analysis of both auditory and visual data for successful interpretation. (2) World Knowledge: We identify five essential types of world knowledge for question formulation. This approach challenges models to extend their capabilities beyond mere perception. (3) Long-Chain Reasoning: Our dataset introduces an average reasoning step of 4.45, notably surpassing other videoQA datasets. Furthermore, we introduce WorldRetriever, an agent designed to synthesize expert knowledge into a coherent reasoning chain, thereby facilitating accurate responses to WorldQA queries. Extensive evaluations of 13 prominent LLMs and LMMs reveal that WorldRetriever, although being the most effective model, achieved only 70% of humanlevel performance in multiple-choice questions. This finding highlights the necessity for further advancement in the reasoning and comprehension abilities of models. Our experiments also yield several key insights. For instance, while humans tend to perform better with increased frames, current LMMs, including WorldRetriever, show diminished performance under similar conditions. We hope that WorldQA,our methodology, and these insights could contribute to the future development of multimodal world models.