 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Single-Point Judgment: Distribution Alignment for LLM-as-a-Judge
May 18, 2025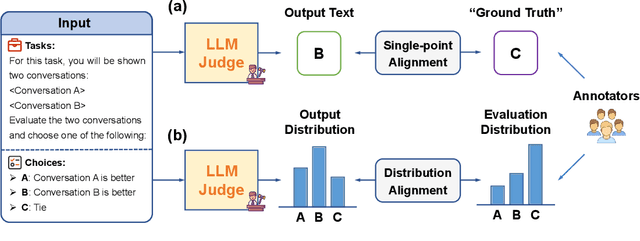
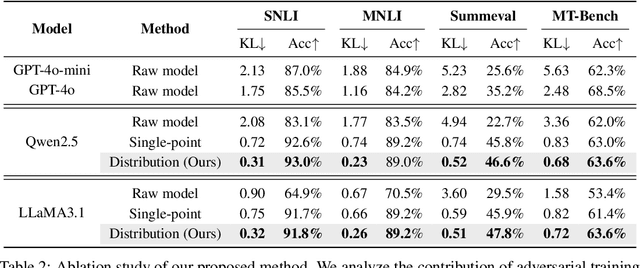
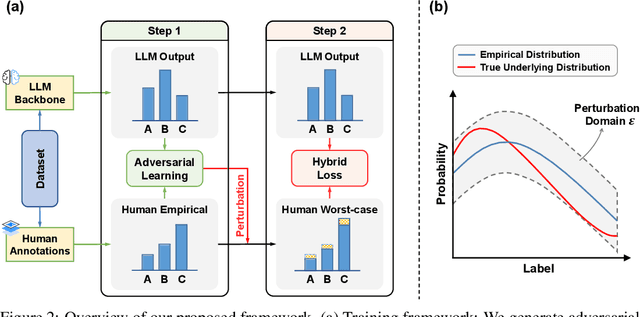
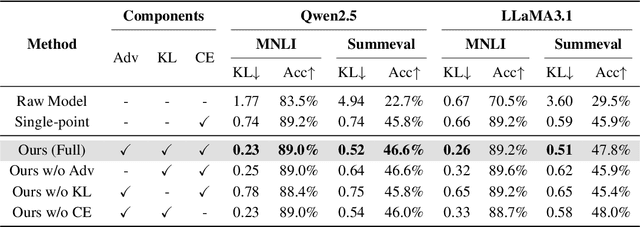
LLMs have emerged as powerful evaluators in the LLM-as-a-Judge paradigm, offering significant efficiency and flexibility compared to human judgments. However, previous methods primarily rely on single-point evaluations, overlooking the inherent diversity and uncertainty in human evaluations. This approach leads to information loss and decreases the reliability of evaluations. To address this limitation, we propose a novel training framework that explicitly aligns the LLM-generated judgment distribution with empirical human distributions. Specifically, we propose a distributional alignment objective based on KL divergence, combined with an auxiliary cross-entropy regularization to stabilize the training process. Furthermore, considering that empirical distributions may derive from limited human annotations, we incorporate adversarial training to enhance model robustness against distribution perturbations. Extensive experiments across various LLM backbones and evaluation tasks demonstrate that our framework significantly outperforms existing closed-source LLMs and conventional single-point alignment methods, with improved alignment quality, evaluation accuracy, and robustness.
GenSim: A General Social Simulation Platform with Large Language Model based Agents
Oct 06, 2024

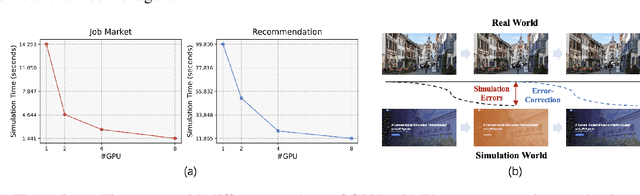

With the rapid advancement of large language models (LLMs), recent years have witnessed many promising studies on leveraging LLM-based agents to simulate human social behavior. While prior work has demonstrated significant potential across various domains, much of it has focused on specific scenarios involving a limited number of agents and has lacked the ability to adapt when errors occur during simulation. To overcome these limitations, we propose a novel LLM-agent-based simulation platform called \textit{GenSim}, which: (1) \textbf{Abstracts a set of general functions} to simplify the simulation of customized social scenarios; (2) \textbf{Supports one hundred thousand agents} to better simulate large-scale populations in real-world contexts; (3) \textbf{Incorporates error-correction mechanisms} to ensure more reliable and long-term simulations. To evaluate our platform, we assess both the efficiency of large-scale agent simulations and the effectiveness of the error-correction mechanisms. To our knowledge, GenSim represents an initial step toward a general, large-scale, and correctable social simulation platform based on LLM agents, promising to further advance the field of social science.
Long Context Transfer from Language to Vision
Jun 24, 2024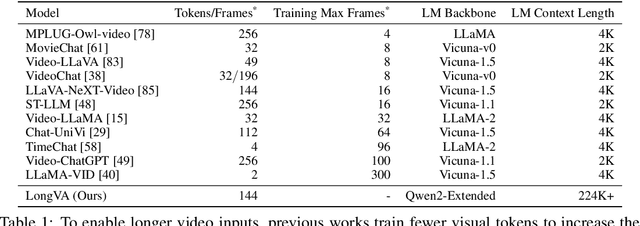
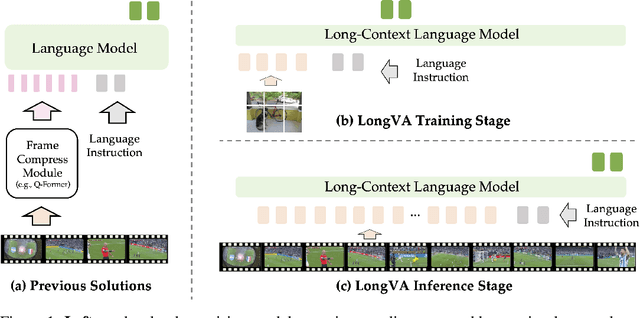


Video sequences offer valuable temporal information, but existing large multimodal models (LMMs) fall short in understanding extremely long videos. Many works address this by reducing the number of visual tokens using visual resamplers. Alternatively, in this paper, we approach this problem from the perspective of the language model. By simply extrapolating the context length of the language backbone, we enable LMMs to comprehend orders of magnitude more visual tokens without any video training. We call this phenomenon long context transfer and carefully ablate its properties. To effectively measure LMMs' ability to generalize to long contexts in the vision modality, we develop V-NIAH (Visual Needle-In-A-Haystack), a purely synthetic long vision benchmark inspired by the language model's NIAH test. Our proposed Long Video Assistant (LongVA) can process 2000 frames or over 200K visual tokens without additional complexities. With its extended context length, LongVA achieves state-of-the-art performance on Video-MME among 7B-scale models by densely sampling more input frames. Our work is open-sourced at https://github.com/EvolvingLMMs-Lab/LongVA.
Octopus: Embodied Vision-Language Programmer from Environmental Feedback
Oct 12, 2023Large vision-language models (VLMs) have achieved substantial progress in multimodal perception and reasoning. Furthermore, when seamlessly integrated into an embodied agent, it signifies a crucial stride towards the creation of autonomous and context-aware systems capable of formulating plans and executing commands with precision. In this paper, we introduce Octopus, a novel VLM designed to proficiently decipher an agent's vision and textual task objectives and to formulate intricate action sequences and generate executable code. Our design allows the agent to adeptly handle a wide spectrum of tasks, ranging from mundane daily chores in simulators to sophisticated interactions in complex video games. Octopus is trained by leveraging GPT-4 to control an explorative agent to generate training data, i.e., action blueprints and the corresponding executable code, within our experimental environment called OctoVerse. We also collect the feedback that allows the enhanced training scheme of Reinforcement Learning with Environmental Feedback (RLEF). Through a series of experiments, we illuminate Octopus's functionality and present compelling results, and the proposed RLEF turns out to refine the agent's decision-making. By open-sourcing our model architecture, simulator, and dataset, we aspire to ignite further innovation and foster collaborative applications within the broader embodied AI community.