 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Latent Reasoning for Sequential Recommendation
Jan 06, 2026Capturing complex user preferences from sparse behavioral sequences remains a fundamental challenge in sequential recommendation. Recent latent reasoning methods have shown promise by extending test-time computation through multi-step reasoning, yet they exclusively rely on depth-level scaling along a single trajectory, suffering from diminishing returns as reasoning depth increases. To address this limitation, we propose \textbf{Parallel Latent Reasoning (PLR)}, a novel framework that pioneers width-level computational scaling by exploring multiple diverse reasoning trajectories simultaneously. PLR constructs parallel reasoning streams through learnable trigger tokens in continuous latent space, preserves diversity across streams via global reasoning regularization, and adaptively synthesizes multi-stream outputs through mixture-of-reasoning-streams aggregation. Extensive experiments on three real-world datasets demonstrate that PLR substantially outperforms state-of-the-art baselines while maintaining real-time inference efficiency. Theoretical analysis further validates the effectiveness of parallel reasoning in improving generalization capability. Our work opens new avenues for enhancing reasoning capacity in sequential recommendation beyond existing depth scaling.
ReaSeq: Unleashing World Knowledge via Reasoning for Sequential Modeling
Dec 24, 2025Industrial recommender systems face two fundamental limitations under the log-driven paradigm: (1) knowledge poverty in ID-based item representations that causes brittle interest modeling under data sparsity, and (2) systemic blindness to beyond-log user interests that constrains model performance within platform boundaries. These limitations stem from an over-reliance on shallow interaction statistics and close-looped feedback while neglecting the rich world knowledge about product semantics and cross-domain behavioral patterns that Large Language Models have learned from vast corpora. To address these challenges, we introduce ReaSeq, a reasoning-enhanced framework that leverages world knowledge in Large Language Models to address both limitations through explicit and implicit reasoning. Specifically, ReaSeq employs explicit Chain-of-Thought reasoning via multi-agent collaboration to distill structured product knowledge into semantically enriched item representations, and latent reasoning via Diffusion Large Language Models to infer plausible beyond-log behaviors. Deployed on Taobao's ranking system serving hundreds of millions of users, ReaSeq achieves substantial gains: >6.0% in IPV and CTR, >2.9% in Orders, and >2.5% in GMV, validating the effectiveness of world-knowledge-enhanced reasoning over purely log-driven approaches.
RecGPT-V2 Technical Report
Dec 16, 2025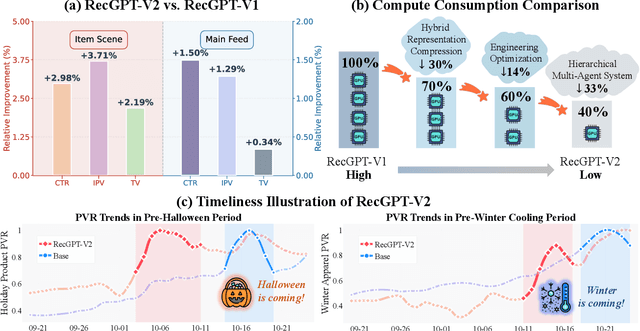
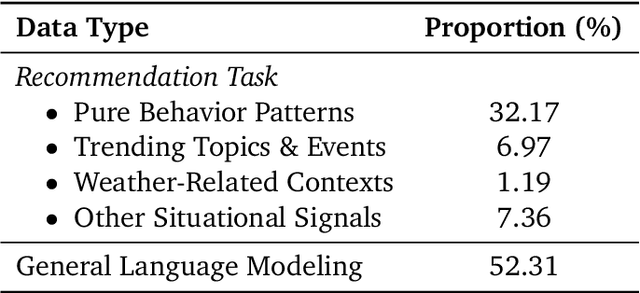
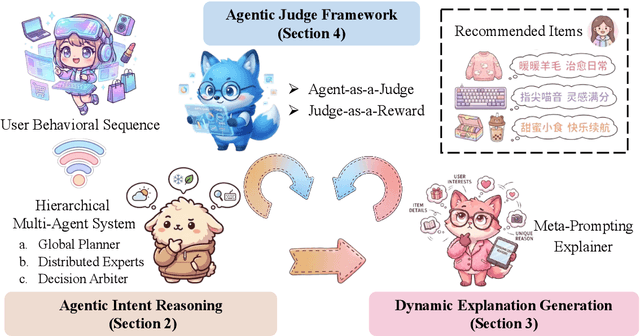

Large language models (LLMs) have demonstrated remarkable potential in transforming recommender systems from implicit behavioral pattern matching to explicit intent reasoning. While RecGPT-V1 successfully pioneered this paradigm by integrating LLM-based reasoning into user interest mining and item tag prediction, it suffers from four fundamental limitations: (1) computational inefficiency and cognitive redundancy across multiple reasoning routes; (2) insufficient explanation diversity in fixed-template generation; (3) limited generalization under supervised learning paradigms; and (4) simplistic outcome-focused evaluation that fails to match human standards. To address these challenges, we present RecGPT-V2 with four key innovations. First, a Hierarchical Multi-Agent System restructures intent reasoning through coordinated collaboration, eliminating cognitive duplication while enabling diverse intent coverage. Combined with Hybrid Representation Inference that compresses user-behavior contexts, our framework reduces GPU consumption by 60% and improves exclusive recall from 9.39% to 10.99%. Second, a Meta-Prompting framework dynamically generates contextually adaptive prompts, improving explanation diversity by +7.3%. Third, constrained reinforcement learning mitigates multi-reward conflicts, achieving +24.1% improvement in tag prediction and +13.0% in explanation acceptance. Fourth, an Agent-as-a-Judge framework decomposes assessment into multi-step reasoning, improving human preference alignment. Online A/B tests on Taobao demonstrate significant improvements: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER. RecGPT-V2 establishes both the technical feasibility and commercial viability of deploying LLM-powered intent reasoning at scale, bridging the gap between cognitive exploration and industrial utility.
RecGPT Technical Report
Jul 30, 2025



Recommender systems are among the most impactful applications of artificial intelligence, serving as critical infrastructure connecting users, merchants, and platforms. However, most current industrial systems remain heavily reliant on historical co-occurrence patterns and log-fitting objectives, i.e., optimizing for past user interactions without explicitly modeling user intent. This log-fitting approach often leads to overfitting to narrow historical preferences, failing to capture users' evolving and latent interests. As a result, it reinforces filter bubbles and long-tail phenomena, ultimately harming user experience and threatening the sustainability of the whole recommendation ecosystem. To address these challenges, we rethink the overall design paradigm of recommender systems and propose RecGPT, a next-generation framework that places user intent at the center of the recommendation pipeline. By integrating large language models (LLMs) into key stages of user interest mining, item retrieval, and explanation generation, RecGPT transforms log-fitting recommendation into an intent-centric process. To effectively align general-purpose LLMs to the above domain-specific recommendation tasks at scale, RecGPT incorporates a multi-stage training paradigm, which integrates reasoning-enhanced pre-alignment and self-training evolution, guided by a Human-LLM cooperative judge system. Currently, RecGPT has been fully deployed on the Taobao App. Online experiments demonstrate that RecGPT achieves consistent performance gains across stakeholders: users benefit from increased content diversity and satisfaction, merchants and the platform gain greater exposure and conversions. These comprehensive improvement results across all stakeholders validates that LLM-driven, intent-centric design can foster a more sustainable and mutually beneficial recommendation ecosystem.
Expectation Confirmation Preference Optimization for Multi-Turn Conversational Recommendation Agent
Jun 17, 2025Recent advancements in Large Language Models (LLMs) have significantly propelled the development of Conversational Recommendation Agents (CRAs). However, these agents often generate short-sighted responses that fail to sustain user guidance and meet expectations. Although preference optimization has proven effective in aligning LLMs with user expectations, it remains costly and performs poorly in multi-turn dialogue. To address this challenge, we introduce a novel multi-turn preference optimization (MTPO) paradigm ECPO, which leverages Expectation Confirmation Theory to explicitly model the evolution of user satisfaction throughout multi-turn dialogues, uncovering the underlying causes of dissatisfaction. These causes can be utilized to support targeted optimization of unsatisfactory responses, thereby achieving turn-level preference optimization. ECPO ingeniously eliminates the significant sampling overhead of existing MTPO methods while ensuring the optimization process drives meaningful improvements. To support ECPO, we introduce an LLM-based user simulator, AILO, to simulate user feedback and perform expectation confirmation during conversational recommendations. Experimental results show that ECPO significantly enhances CRA's interaction capabilities, delivering notable improvements in both efficiency and effectiveness over existing MTPO methods.
HF4Rec: Human-Like Feedback-Driven Optimization Framework for Explainable Recommendation
Apr 19, 2025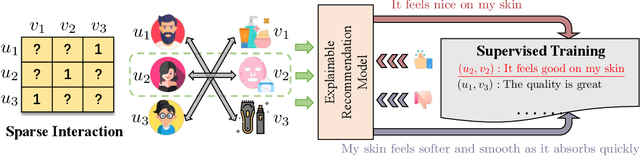

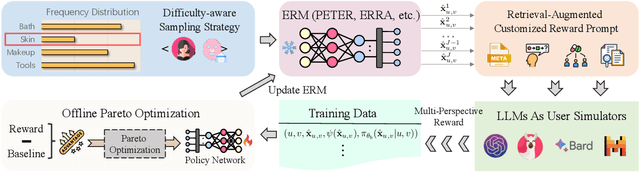
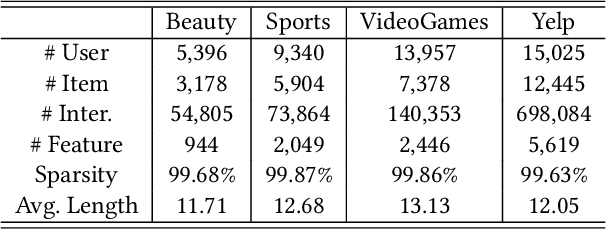
Recent advancements in explainable recommendation have greatly bolstered user experience by elucidating the decision-making rationale. However, the existing methods actually fail to provide effective feedback signals for potentially better or worse generated explanations due to their reliance on traditional supervised learning paradigms in sparse interaction data. To address these issues, we propose a novel human-like feedback-driven optimization framework. This framework employs a dynamic interactive optimization mechanism for achieving human-centered explainable requirements without incurring high labor costs. Specifically, we propose to utilize large language models (LLMs) as human simulators to predict human-like feedback for guiding the learning process. To enable the LLMs to deeply understand the task essence and meet user's diverse personalized requirements, we introduce a human-induced customized reward scoring method, which helps stimulate the language understanding and logical reasoning capabilities of LLMs. Furthermore, considering the potential conflicts between different perspectives of explanation quality, we introduce a principled Pareto optimization that transforms the multi-perspective quality enhancement task into a multi-objective optimization problem for improving explanation performance. At last, to achieve efficient model training, we design an off-policy optimization pipeline. By incorporating a replay buffer and addressing the data distribution biases, we can effectively improve data utilization and enhance model generality. Extensive experiments on four datasets demonstrate the superiority of our approach.
Think Before Recommend: Unleashing the Latent Reasoning Power for Sequential Recommendation
Mar 28, 2025Sequential Recommendation (SeqRec) aims to predict the next item by capturing sequential patterns from users' historical interactions, playing a crucial role in many real-world recommender systems. However, existing approaches predominantly adopt a direct forward computation paradigm, where the final hidden state of the sequence encoder serves as the user representation. We argue that this inference paradigm, due to its limited computational depth, struggles to model the complex evolving nature of user preferences and lacks a nuanced understanding of long-tail items, leading to suboptimal performance. To address this issue, we propose \textbf{ReaRec}, the first inference-time computing framework for recommender systems, which enhances user representations through implicit multi-step reasoning. Specifically, ReaRec autoregressively feeds the sequence's last hidden state into the sequential recommender while incorporating special reasoning position embeddings to decouple the original item encoding space from the multi-step reasoning space. Moreover, we introduce two lightweight reasoning-based learning methods, Ensemble Reasoning Learning (ERL) and Progressive Reasoning Learning (PRL), to further effectively exploit ReaRec's reasoning potential. Extensive experiments on five public real-world datasets and different SeqRec architectures demonstrate the generality and effectiveness of our proposed ReaRec. Remarkably, post-hoc analyses reveal that ReaRec significantly elevates the performance ceiling of multiple sequential recommendation backbones by approximately 30\%-50\%. Thus, we believe this work can open a new and promising avenue for future research in inference-time computing for sequential recommendation.
Improving Retrospective Language Agents via Joint Policy Gradient Optimization
Mar 03, 2025In recent research advancements within the community, large language models (LLMs) have sparked great interest in creating autonomous agents. However, current prompt-based agents often heavily rely on large-scale LLMs. Meanwhile, although fine-tuning methods significantly enhance the capabilities of smaller LLMs, the fine-tuned agents often lack the potential for self-reflection and self-improvement. To address these challenges, we introduce a novel agent framework named RetroAct, which is a framework that jointly optimizes both task-planning and self-reflective evolution capabilities in language agents. Specifically, we develop a two-stage joint optimization process that integrates imitation learning and reinforcement learning, and design an off-policy joint policy gradient optimization algorithm with imitation learning regularization to enhance the data efficiency and training stability in agent tasks. RetroAct significantly improves the performance of open-source models, reduces dependency on closed-source LLMs, and enables fine-tuned agents to learn and evolve continuously. We conduct extensive experiments across various testing environments, demonstrating RetroAct has substantial improvements in task performance and decision-making processes.
GenSim: A General Social Simulation Platform with Large Language Model based Agents
Oct 06, 2024

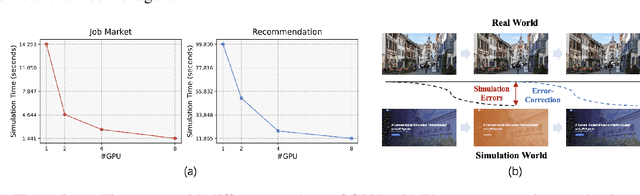

With the rapid advancement of large language models (LLMs), recent years have witnessed many promising studies on leveraging LLM-based agents to simulate human social behavior. While prior work has demonstrated significant potential across various domains, much of it has focused on specific scenarios involving a limited number of agents and has lacked the ability to adapt when errors occur during simulation. To overcome these limitations, we propose a novel LLM-agent-based simulation platform called \textit{GenSim}, which: (1) \textbf{Abstracts a set of general functions} to simplify the simulation of customized social scenarios; (2) \textbf{Supports one hundred thousand agents} to better simulate large-scale populations in real-world contexts; (3) \textbf{Incorporates error-correction mechanisms} to ensure more reliable and long-term simulations. To evaluate our platform, we assess both the efficiency of large-scale agent simulations and the effectiveness of the error-correction mechanisms. To our knowledge, GenSim represents an initial step toward a general, large-scale, and correctable social simulation platform based on LLM agents, promising to further advance the field of social science.
Towards Robust Recommendation via Decision Boundary-aware Graph Contrastive Learning
Jul 14, 2024



In recent years, graph contrastive learning (GCL) has received increasing attention in recommender systems due to its effectiveness in reducing bias caused by data sparsity. However, most existing GCL models rely on heuristic approaches and usually assume entity independence when constructing contrastive views. We argue that these methods struggle to strike a balance between semantic invariance and view hardness across the dynamic training process, both of which are critical factors in graph contrastive learning. To address the above issues, we propose a novel GCL-based recommendation framework RGCL, which effectively maintains the semantic invariance of contrastive pairs and dynamically adapts as the model capability evolves through the training process. Specifically, RGCL first introduces decision boundary-aware adversarial perturbations to constrain the exploration space of contrastive augmented views, avoiding the decrease of task-specific information. Furthermore, to incorporate global user-user and item-item collaboration relationships for guiding on the generation of hard contrastive views, we propose an adversarial-contrastive learning objective to construct a relation-aware view-generator. Besides, considering that unsupervised GCL could potentially narrower margins between data points and the decision boundary, resulting in decreased model robustness, we introduce the adversarial examples based on maximum perturbations to achieve margin maximization. We also provide theoretical analyses on the effectiveness of our designs. Through extensive experiments on five public datasets, we demonstrate the superiority of RGCL compared against twelve baseline models.