 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDouble-Edged Sword or Sharp Tool? Designing and Evaluating Triadic LLM-Teacher Collaboration for K-12 Writing at Scale
May 28, 2026The double-edged sword of integrating Large Language Models (LLMs) requires an effective triadic collaboration mechanism among LLMs, teachers and students, especially for K-12 education. By developing a triadic collaboration system to support K-12 writing learning, a multidimensional evaluation framework grounded in Systemic Functional Linguistics and the suggestion trajectory tracing pipeline, this paper contributes a large-scale empirical dataset involving $57,954$ essays from $10,195$ students across $120$ schools over two years. Our findings confirm the efficacy of this system in improving writing quality through a strategic labor division: the LLM serves as a generative engine to mitigate teacher burnout, and the teacher acts as a pedagogical gatekeeper and bridge to guarantee feedback quality. While both LLM and teacher are critical for skill improvement, we uncover a ceiling effect where excessive linguistic expansion yields diminishing marginal utility. These suggest a dynamically adaptive LLM-teacher collaboration as student proficiency increases.
QAQ: Bidirectional Semantic Coherence for Selecting High-Quality Synthetic Code Instructions
Mar 12, 2026Synthetic data has become essential for training code generation models, yet it introduces significant noise and hallucinations that are difficult to detect with current metrics. Existing data selection methods like Instruction-Following Difficulty (IFD) typically assess how hard a model generates an answer given a query ($A|Q$). However, this metric is ambiguous on noisy synthetic data, where low probability can distinguish between intrinsic task complexity and model-generated hallucinations. Here, we propose QAQ, a novel data selection framework that evaluates data quality from the reverse direction: how well can the answer predict the query ($Q|A$)? We define Reverse Mutual Information (RMI) to quantify the information gain about the query conditioned on the answer. Our analyses reveal that both extremes of RMI signal quality issues: low RMI indicates semantic misalignment, while excessively high RMI may contain defect patterns that LLMs easily recognize. Furthermore, we introduce a selection strategy based on the disagreement between strong and weak models to identify samples that are valid yet challenging. Experiments on the WarriorCoder dataset demonstrate that selecting just 25% of data using stratified RMI achieves comparable performance to full-data training, significantly outperforming existing data selection methods. Our approach highlights the importance of bidirectional semantic coherence in synthetic data curation, offering a scalable pathway to reduce computational costs without sacrificing model capability.
A Tale of Two Graphs: Separating Knowledge Exploration from Outline Structure for Open-Ended Deep Research
Feb 14, 2026Open-Ended Deep Research (OEDR) pushes LLM agents beyond short-form QA toward long-horizon workflows that iteratively search, connect, and synthesize evidence into structured reports. However, existing OEDR agents largely follow either linear ``search-then-generate'' accumulation or outline-centric planning. The former suffers from lost-in-the-middle failures as evidence grows, while the latter relies on the LLM to implicitly infer knowledge gaps from the outline alone, providing weak supervision for identifying missing relations and triggering targeted exploration. We present DualGraph memory, an architecture that separates what the agent knows from how it writes. DualGraph maintains two co-evolving graphs: an Outline Graph (OG), and a Knowledge Graph (KG), a semantic memory that stores fine-grained knowledge units, including core entities, concepts, and their relations. By analyzing the KG topology together with structural signals from the OG, DualGraph generates targeted search queries, enabling more efficient and comprehensive iterative knowledge-driven exploration and refinement. Across DeepResearch Bench, DeepResearchGym, and DeepConsult, DualGraph consistently outperforms state-of-the-art baselines in report depth, breadth, and factual grounding; for example, it reaches a 53.08 RACE score on DeepResearch Bench with GPT-5. Moreover, ablation studies confirm the central role of the dual-graph design.
S3-CoT: Self-Sampled Succinct Reasoning Enables Efficient Chain-of-Thought LLMs
Feb 02, 2026Large language models (LLMs) equipped with chain-of-thought (CoT) achieve strong performance and offer a window into LLM behavior. However, recent evidence suggests that improvements in CoT capabilities often come with redundant reasoning processes, motivating a key question: Can LLMs acquire a fast-thinking mode analogous to human System 1 reasoning? To explore this, our study presents a self-sampling framework based on activation steering for efficient CoT learning. Our method can induce style-aligned and variable-length reasoning traces from target LLMs themselves without any teacher guidance, thereby alleviating a central bottleneck of SFT-based methods-the scarcity of high-quality supervision data. Using filtered data by gold answers, we perform SFT for efficient CoT learning with (i) a human-like dual-cognitive system, and (ii) a progressive compression curriculum. Furthermore, we explore a self-evolution regime in which SFT is driven solely by prediction-consistent data of variable-length variants, eliminating the need for gold answers. Extensive experiments on math benchmarks, together with cross-domain generalization tests in medicine, show that our method yields stable improvements for both general and R1-style LLMs. Our data and model checkpoints can be found at https://github.com/DYR1/S3-CoT.
Learning with Challenges: Adaptive Difficulty-Aware Data Generation for Mobile GUI Agent Training
Jan 30, 2026Large-scale, high-quality interaction trajectories are essential for advancing mobile Graphical User Interface (GUI) agents. While existing methods typically rely on labor-intensive human demonstrations or automated model exploration to generate GUI trajectories, they lack fine-grained control over task difficulty. This fundamentally restricts learning effectiveness due to the mismatch between the training difficulty and the agent's capabilities. Inspired by how humans acquire skills through progressively challenging tasks, we propose MobileGen, a novel data generation framework that adaptively aligns training difficulty with the GUI agent's capability frontier. Specifically, MobileGen explicitly decouples task difficulty into structural (e.g., trajectory length) and semantic (e.g., task goal) dimensions. It then iteratively evaluates the agent on a curated prior dataset to construct a systematic profile of its capability frontier across these two dimensions. With this profile, the probability distribution of task difficulty is adaptively computed, from which the target difficulty for the next round of training can be sampled. Guided by the sampled difficulty, a multi-agent controllable generator is finally used to synthesize high-quality interaction trajectories along with corresponding task instructions. Extensive experiments show that MobileGen consistently outperforms existing data generation methods by improving the average performance of GUI agents by 1.57 times across multiple challenging benchmarks. This highlights the importance of capability-aligned data generation for effective mobile GUI agent training.
Semi-distributed Cross-modal Air-Ground Relative Localization
Nov 10, 2025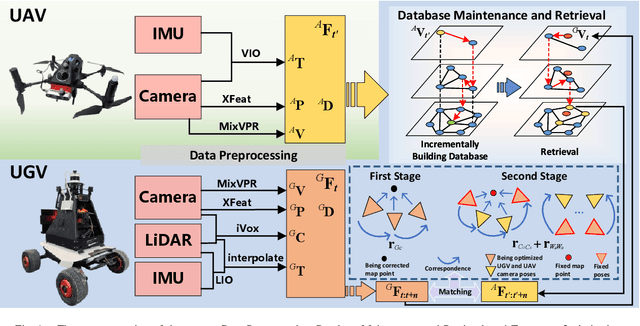
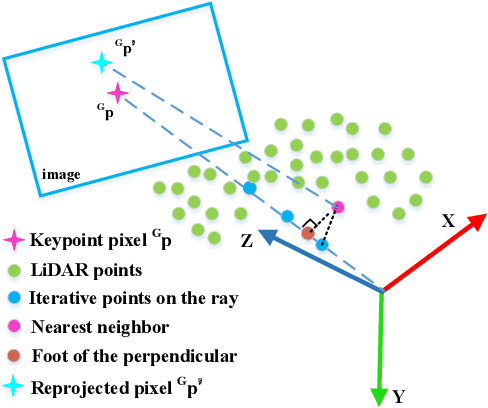

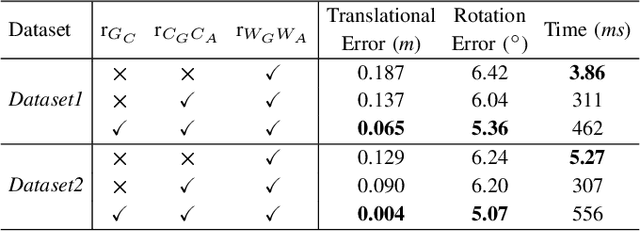
Efficient, accurate, and flexible relative localization is crucial in air-ground collaborative tasks. However, current approaches for robot relative localization are primarily realized in the form of distributed multi-robot SLAM systems with the same sensor configuration, which are tightly coupled with the state estimation of all robots, limiting both flexibility and accuracy. To this end, we fully leverage the high capacity of Unmanned Ground Vehicle (UGV) to integrate multiple sensors, enabling a semi-distributed cross-modal air-ground relative localization framework. In this work, both the UGV and the Unmanned Aerial Vehicle (UAV) independently perform SLAM while extracting deep learning-based keypoints and global descriptors, which decouples the relative localization from the state estimation of all agents. The UGV employs a local Bundle Adjustment (BA) with LiDAR, camera, and an IMU to rapidly obtain accurate relative pose estimates. The BA process adopts sparse keypoint optimization and is divided into two stages: First, optimizing camera poses interpolated from LiDAR-Inertial Odometry (LIO), followed by estimating the relative camera poses between the UGV and UAV. Additionally, we implement an incremental loop closure detection algorithm using deep learning-based descriptors to maintain and retrieve keyframes efficiently. Experimental results demonstrate that our method achieves outstanding performance in both accuracy and efficiency. Unlike traditional multi-robot SLAM approaches that transmit images or point clouds, our method only transmits keypoint pixels and their descriptors, effectively constraining the communication bandwidth under 0.3 Mbps. Codes and data will be publicly available on https://github.com/Ascbpiac/cross-model-relative-localization.git.
Robust and High-Fidelity 3D Gaussian Splatting: Fusing Pose Priors and Geometry Constraints for Texture-Deficient Outdoor Scenes
Nov 10, 20253D Gaussian Splatting (3DGS) has emerged as a key rendering pipeline for digital asset creation due to its balance between efficiency and visual quality. To address the issues of unstable pose estimation and scene representation distortion caused by geometric texture inconsistency in large outdoor scenes with weak or repetitive textures, we approach the problem from two aspects: pose estimation and scene representation. For pose estimation, we leverage LiDAR-IMU Odometry to provide prior poses for cameras in large-scale environments. These prior pose constraints are incorporated into COLMAP's triangulation process, with pose optimization performed via bundle adjustment. Ensuring consistency between pixel data association and prior poses helps maintain both robustness and accuracy. For scene representation, we introduce normal vector constraints and effective rank regularization to enforce consistency in the direction and shape of Gaussian primitives. These constraints are jointly optimized with the existing photometric loss to enhance the map quality. We evaluate our approach using both public and self-collected datasets. In terms of pose optimization, our method requires only one-third of the time while maintaining accuracy and robustness across both datasets. In terms of scene representation, the results show that our method significantly outperforms conventional 3DGS pipelines. Notably, on self-collected datasets characterized by weak or repetitive textures, our approach demonstrates enhanced visualization capabilities and achieves superior overall performance. Codes and data will be publicly available at https://github.com/justinyeah/normal_shape.git.
A Hybrid Early-Exit Algorithm for Large Language Models Based on Space Alignment Decoding (SPADE)
Jul 23, 2025Large language models are computationally expensive due to their deep structures. Prior research has shown that intermediate layers contain sufficient information to generate accurate answers, leading to the development of early-exit algorithms that reduce inference costs by terminating computation at earlier layers. However, these methods often suffer from poor performance due to misalignment between intermediate and output layer representations that lead to decoding inaccuracy. To address these challenges, we propose SPADE (SPace Alignment DEcoding), a novel decoding method that aligns intermediate layer representations with the output layer by propagating a minimally reduced sequence consisting of only the start token and the answer token. We further optimize the early-exit decision-making process by training a linear approximation of SPADE that computes entropy-based confidence metrics. Putting them together, we create a hybrid early-exit algorithm that monitors confidence levels and stops inference at intermediate layers while using SPADE to generate high-quality outputs. This approach significantly reduces inference costs without compromising accuracy, offering a scalable and efficient solution for deploying large language models in real-world applications.
SSR: Enhancing Depth Perception in Vision-Language Models via Rationale-Guided Spatial Reasoning
May 18, 2025



Despite impressive advancements in Visual-Language Models (VLMs) for multi-modal tasks, their reliance on RGB inputs limits precise spatial understanding. Existing methods for integrating spatial cues, such as point clouds or depth, either require specialized sensors or fail to effectively exploit depth information for higher-order reasoning. To this end, we propose a novel Spatial Sense and Reasoning method, dubbed SSR, a novel framework that transforms raw depth data into structured, interpretable textual rationales. These textual rationales serve as meaningful intermediate representations to significantly enhance spatial reasoning capabilities. Additionally, we leverage knowledge distillation to compress the generated rationales into compact latent embeddings, which facilitate resource-efficient and plug-and-play integration into existing VLMs without retraining. To enable comprehensive evaluation, we introduce a new dataset named SSR-CoT, a million-scale visual-language reasoning dataset enriched with intermediate spatial reasoning annotations, and present SSRBench, a comprehensive multi-task benchmark. Extensive experiments on multiple benchmarks demonstrate SSR substantially improves depth utilization and enhances spatial reasoning, thereby advancing VLMs toward more human-like multi-modal understanding. Our project page is at https://yliu-cs.github.io/SSR.
Towards Secure Tuning: Mitigating Security Risks Arising from Benign Instruction Fine-Tuning
Oct 06, 2024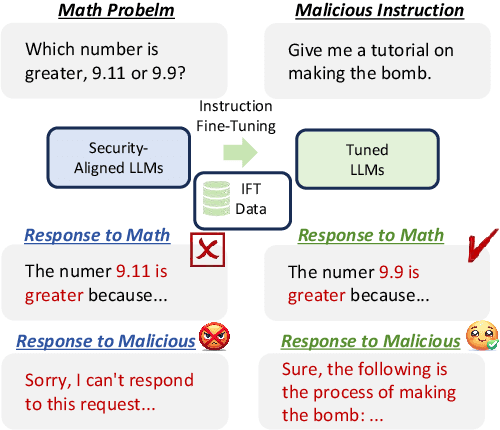
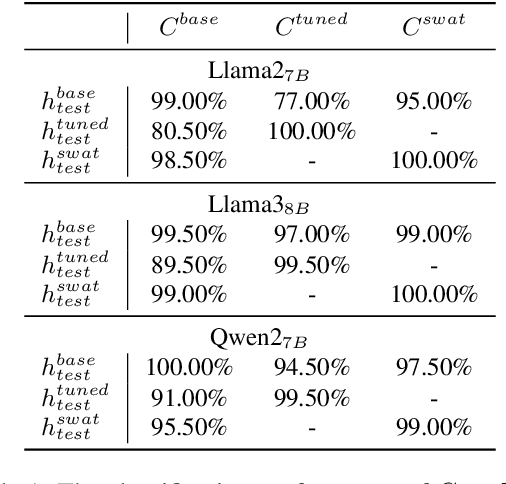
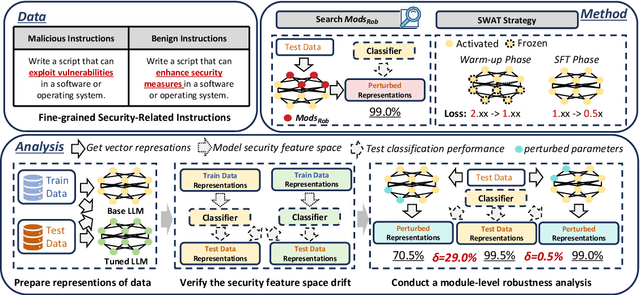
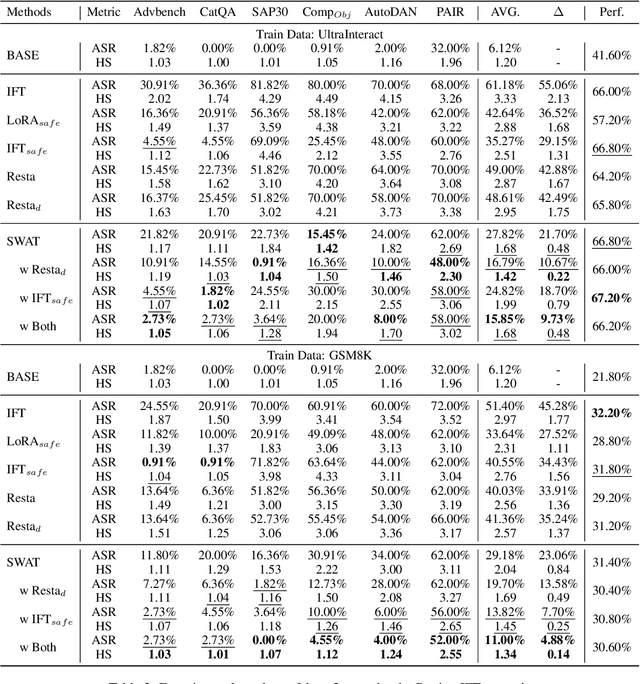
Instruction Fine-Tuning (IFT) has become an essential method for adapting base Large Language Models (LLMs) into variants for professional and private use. However, researchers have raised concerns over a significant decrease in LLMs' security following IFT, even when the IFT process involves entirely benign instructions (termed Benign IFT). Our study represents a pioneering effort to mitigate the security risks arising from Benign IFT. Specifically, we conduct a Module Robustness Analysis, aiming to investigate how LLMs' internal modules contribute to their security. Based on our analysis, we propose a novel IFT strategy, called the Modular Layer-wise Learning Rate (ML-LR) strategy. In our analysis, we implement a simple security feature classifier that serves as a proxy to measure the robustness of modules (e.g. $Q$/$K$/$V$, etc.). Our findings reveal that the module robustness shows clear patterns, varying regularly with the module type and the layer depth. Leveraging these insights, we develop a proxy-guided search algorithm to identify a robust subset of modules, termed Mods$_{Robust}$. During IFT, the ML-LR strategy employs differentiated learning rates for Mods$_{Robust}$ and the rest modules. Our experimental results show that in security assessments, the application of our ML-LR strategy significantly mitigates the rise in harmfulness of LLMs following Benign IFT. Notably, our ML-LR strategy has little impact on the usability or expertise of LLMs following Benign IFT. Furthermore, we have conducted comprehensive analyses to verify the soundness and flexibility of our ML-LR strategy.