 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSFM: A Biologically-Inspired Framework for Selective Forgetting of Agent Memory
Apr 22, 2026For LLM agents, memory management critically impacts efficiency, quality, and security. While much research focuses on retention, selective forgetting--inspired by human cognitive processes (hippocampal indexing/consolidation theory and Ebbinghaus forgetting curve)--remains underexplored. We argue that in resource-constrained environments, a well-designed forgetting mechanism is as crucial as remembering, delivering benefits across three dimensions: (1) efficiency via intelligent memory pruning, (2) quality by dynamically updating outdated preferences and context, and (3) security through active forgetting of malicious inputs, sensitive data, and privacy-compromising content. Our framework establishes a taxonomy of forgetting mechanisms: passive decay-based, active deletion-based, safety-triggered, and adaptive reinforcement-based. Building on advances in LLM agent architectures and vector databases, we present detailed specifications, implementation strategies, and empirical validation from controlled experiments. Results show significant improvements: access efficiency (+8.49%), content quality (+29.2% signal-to-noise ratio), and security performance (100% elimination of security risks). Our work bridges cognitive neuroscience and AI systems, offering practical solutions for real-world deployment while addressing ethical and regulatory compliance. The paper concludes with challenges and future directions, establishing selective forgetting as a fundamental capability for next-generation LLM agents operating in real-world, resource-constrained scenarios. Our contributions align with AI-native memory systems and responsible AI development.
ARC-Hunyuan-Video-7B: Structured Video Comprehension of Real-World Shorts
Jul 28, 2025Real-world user-generated short videos, especially those distributed on platforms such as WeChat Channel and TikTok, dominate the mobile internet. However, current large multimodal models lack essential temporally-structured, detailed, and in-depth video comprehension capabilities, which are the cornerstone of effective video search and recommendation, as well as emerging video applications. Understanding real-world shorts is actually challenging due to their complex visual elements, high information density in both visuals and audio, and fast pacing that focuses on emotional expression and viewpoint delivery. This requires advanced reasoning to effectively integrate multimodal information, including visual, audio, and text. In this work, we introduce ARC-Hunyuan-Video, a multimodal model that processes visual, audio, and textual signals from raw video inputs end-to-end for structured comprehension. The model is capable of multi-granularity timestamped video captioning and summarization, open-ended video question answering, temporal video grounding, and video reasoning. Leveraging high-quality data from an automated annotation pipeline, our compact 7B-parameter model is trained through a comprehensive regimen: pre-training, instruction fine-tuning, cold start, reinforcement learning (RL) post-training, and final instruction fine-tuning. Quantitative evaluations on our introduced benchmark ShortVid-Bench and qualitative comparisons demonstrate its strong performance in real-world video comprehension, and it supports zero-shot or fine-tuning with a few samples for diverse downstream applications. The real-world production deployment of our model has yielded tangible and measurable improvements in user engagement and satisfaction, a success supported by its remarkable efficiency, with stress tests indicating an inference time of just 10 seconds for a one-minute video on H20 GPU.
Data-Driven Optical To Thermal Inference in Pool Boiling Using Generative Adversarial Networks
May 01, 2025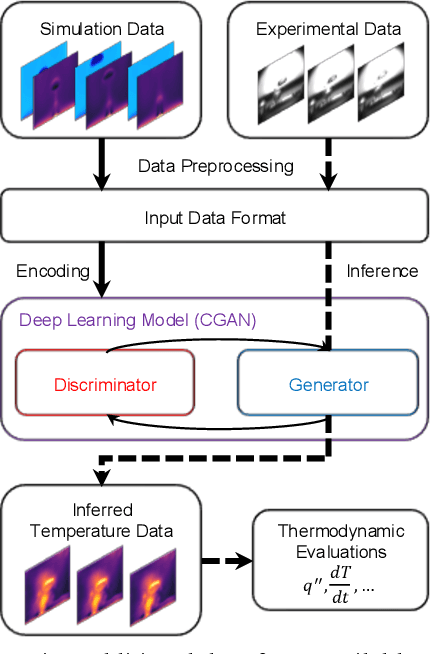
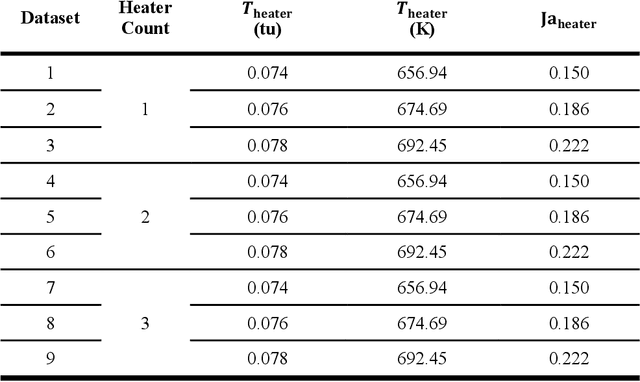
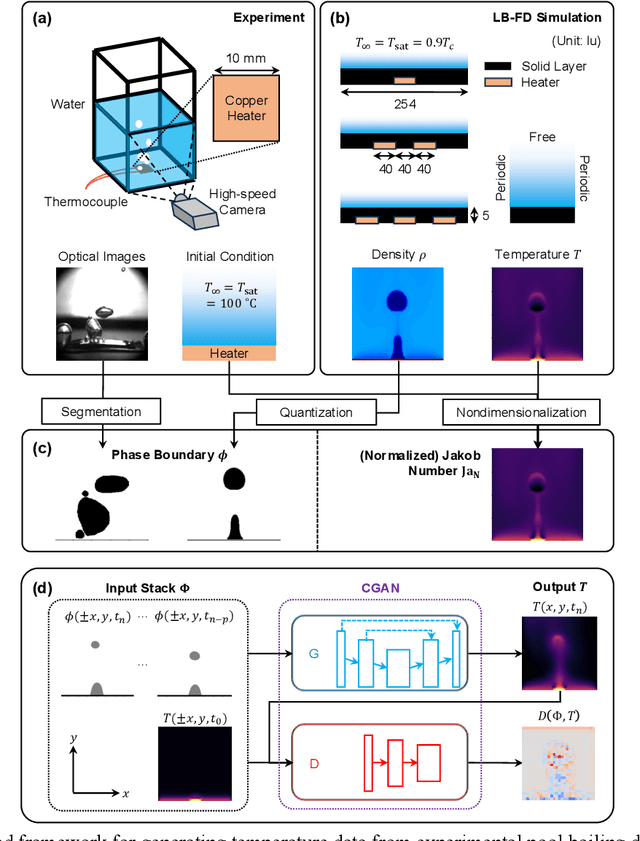
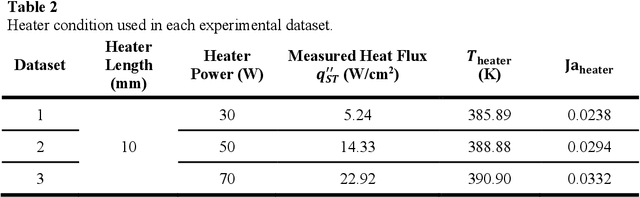
Phase change plays a critical role in thermal management systems, yet quantitative characterization of multiphase heat transfer remains limited by the challenges of measuring temperature fields in chaotic, rapidly evolving flow regimes. While computational methods offer spatiotemporal resolution in idealized cases, replicating complex experimental conditions remains prohibitively difficult. Here, we present a data-driven framework that leverages a conditional generative adversarial network (CGAN) to infer temperature fields from geometric phase contours in a canonical pool boiling configuration where advanced data collection techniques are restricted. Using high-speed imaging data and simulation-informed training, our model demonstrates the ability to reconstruct temperature fields with errors below 6%. We further show that standard data augmentation strategies are effective in enhancing both accuracy and physical plausibility of the predicted maps across both simulation and experimental datasets when precise physical constraints are not applicable. Our results highlight the potential of deep generative models to bridge the gap between observable multiphase phenomena and underlying thermal transport, offering a powerful approach to augment and interpret experimental measurements in complex two-phase systems.
Interpreting and Improving Optimal Control Problems with Directional Corrections
Apr 01, 2025



Many robotics tasks, such as path planning or trajectory optimization, are formulated as optimal control problems (OCPs). The key to obtaining high performance lies in the design of the OCP's objective function. In practice, the objective function consists of a set of individual components that must be carefully modeled and traded off such that the OCP has the desired solution. It is often challenging to balance multiple components to achieve the desired solution and to understand, when the solution is undesired, the impact of individual cost components. In this paper, we present a framework addressing these challenges based on the concept of directional corrections. Specifically, given the solution to an OCP that is deemed undesirable, and access to an expert providing the direction of change that would increase the desirability of the solution, our method analyzes the individual cost components for their "consistency" with the provided directional correction. This information can be used to improve the OCP formulation, e.g., by increasing the weight of consistent cost components, or reducing the weight of - or even redesigning - inconsistent cost components. We also show that our framework can automatically tune parameters of the OCP to achieve consistency with a set of corrections.
$\texttt{PatentAgent}$: Intelligent Agent for Automated Pharmaceutical Patent Analysis
Oct 25, 2024Pharmaceutical patents play a vital role in biochemical industries, especially in drug discovery, providing researchers with unique early access to data, experimental results, and research insights. With the advancement of machine learning, patent analysis has evolved from manual labor to tasks assisted by automatic tools. However, there still lacks an unified agent that assists every aspect of patent analysis, from patent reading to core chemical identification. Leveraging the capabilities of Large Language Models (LLMs) to understand requests and follow instructions, we introduce the $\textbf{first}$ intelligent agent in this domain, $\texttt{PatentAgent}$, poised to advance and potentially revolutionize the landscape of pharmaceutical research. $\texttt{PatentAgent}$ comprises three key end-to-end modules -- $\textit{PA-QA}$, $\textit{PA-Img2Mol}$, and $\textit{PA-CoreId}$ -- that respectively perform (1) patent question-answering, (2) image-to-molecular-structure conversion, and (3) core chemical structure identification, addressing the essential needs of scientists and practitioners in pharmaceutical patent analysis. Each module of $\texttt{PatentAgent}$ demonstrates significant effectiveness with the updated algorithm and the synergistic design of $\texttt{PatentAgent}$ framework. $\textit{PA-Img2Mol}$ outperforms existing methods across CLEF, JPO, UOB, and USPTO patent benchmarks with an accuracy gain between 2.46% and 8.37% while $\textit{PA-CoreId}$ realizes accuracy improvement ranging from 7.15% to 7.62% on PatentNetML benchmark. Our code and dataset will be publicly available.
BioKGBench: A Knowledge Graph Checking Benchmark of AI Agent for Biomedical Science
Jun 29, 2024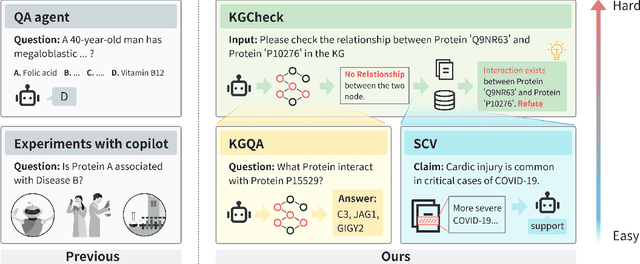
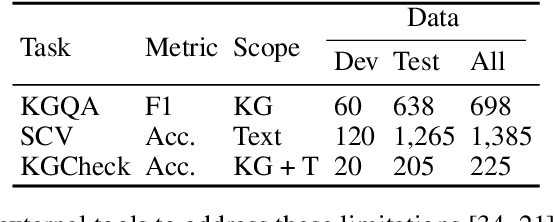
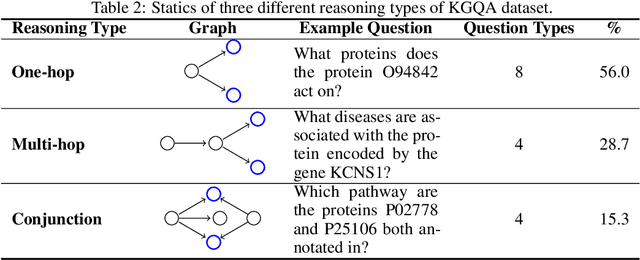
Pursuing artificial intelligence for biomedical science, a.k.a. AI Scientist, draws increasing attention, where one common approach is to build a copilot agent driven by Large Language Models (LLMs). However, to evaluate such systems, people either rely on direct Question-Answering (QA) to the LLM itself, or in a biomedical experimental manner. How to precisely benchmark biomedical agents from an AI Scientist perspective remains largely unexplored. To this end, we draw inspiration from one most important abilities of scientists, understanding the literature, and introduce BioKGBench. In contrast to traditional evaluation benchmark that only focuses on factual QA, where the LLMs are known to have hallucination issues, we first disentangle "Understanding Literature" into two atomic abilities, i) "Understanding" the unstructured text from research papers by performing scientific claim verification, and ii) Ability to interact with structured Knowledge-Graph Question-Answering (KGQA) as a form of "Literature" grounding. We then formulate a novel agent task, dubbed KGCheck, using KGQA and domain-based Retrieval-Augmented Generation (RAG) to identify the factual errors of existing large-scale knowledge graph databases. We collect over two thousand data for two atomic tasks and 225 high-quality annotated data for the agent task. Surprisingly, we discover that state-of-the-art agents, both daily scenarios and biomedical ones, have either failed or inferior performance on our benchmark. We then introduce a simple yet effective baseline, dubbed BKGAgent. On the widely used popular knowledge graph, we discover over 90 factual errors which provide scenarios for agents to make discoveries and demonstrate the effectiveness of our approach. The code and data are available at https://github.com/westlake-autolab/BioKGBench.
a novel attention-based network for fast salient object detection
Dec 20, 2021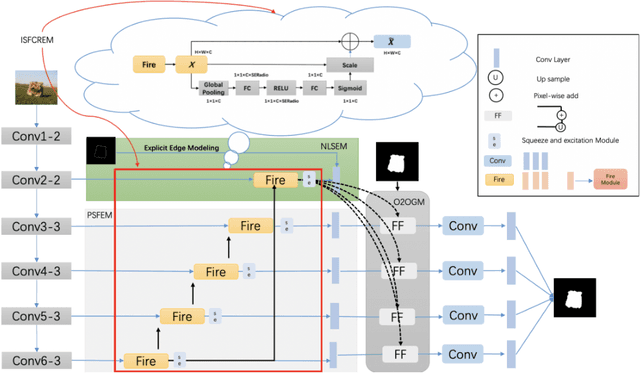

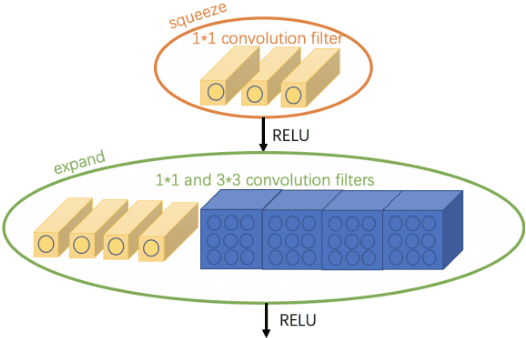
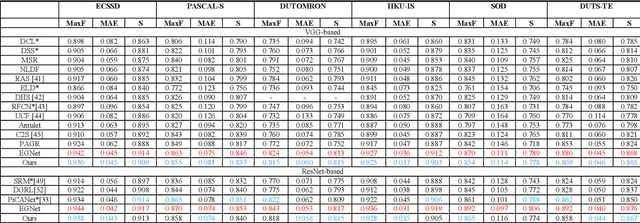
In the current salient object detection network, the most popular method is using U-shape structure. However, the massive number of parameters leads to more consumption of computing and storage resources which are not feasible to deploy on the limited memory device. Some others shallow layer network will not maintain the same accuracy compared with U-shape structure and the deep network structure with more parameters will not converge to a global minimum loss with great speed. To overcome all of these disadvantages, we proposed a new deep convolution network architecture with three contributions: (1) using smaller convolution neural networks (CNNs) to compress the model in our improved salient object features compression and reinforcement extraction module (ISFCREM) to reduce parameters of the model. (2) introducing channel attention mechanism in ISFCREM to weigh different channels for improving the ability of feature representation. (3) applying a new optimizer to accumulate the long-term gradient information during training to adaptively tune the learning rate. The results demonstrate that the proposed method can compress the model to 1/3 of the original size nearly without losing the accuracy and converging faster and more smoothly on six widely used datasets of salient object detection compared with the others models. Our code is published in https://gitee.com/binzhangbinzhangbin/code-a-novel-attention-based-network-for-fast-salient-object-detection.git
A Distributed Multi-Robot Coordination Algorithm for Navigation in Tight Environments
Jun 20, 2020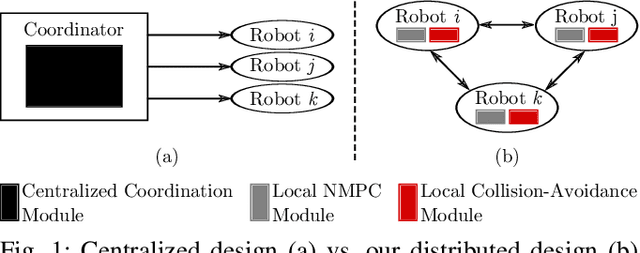
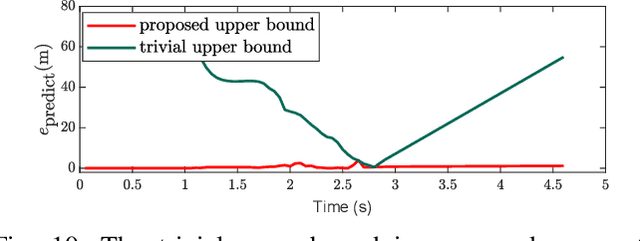
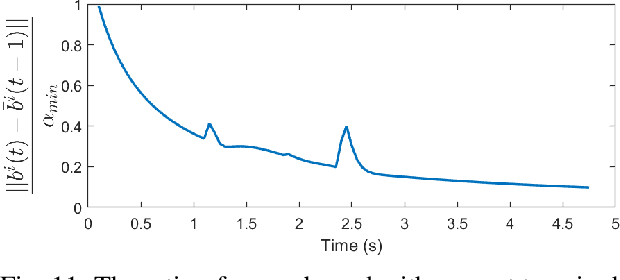
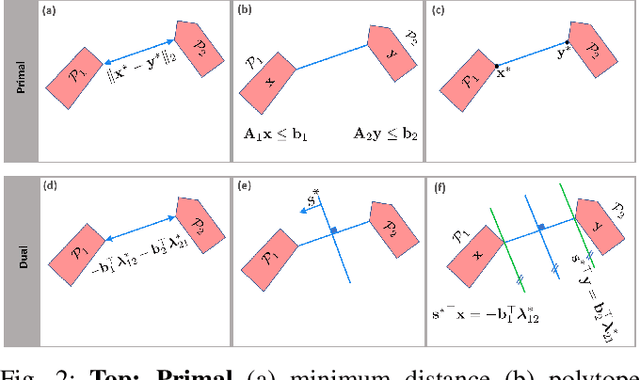
This work presents a distributed method for multi-robot coordination based on nonlinear model predictive control (NMPC) and dual decomposition. Our approach allows the robots to coordinate in tight spaces (e.g., highway lanes, parking lots, warehouses, canals, etc.) by using a polytopic description of each robot's shape and formulating the collision avoidance as a dual optimization problem. Our method accommodates heterogeneous teams of robots (i.e., robots with different polytopic shapes and dynamic models can be part of the same team) and can be used to avoid collisions in $n$-dimensional spaces. Starting from a centralized implementation of the NMPC problem, we show how to exploit the problem structure to allow the robots to cooperate (while communicating their intentions to the neighbors) and compute collision-free paths in a distributed way in real time. By relying on a bi-level optimization scheme, our design decouples the optimization of the robot states and of the collision-avoidance variables to create real time coordination strategies. Finally, we apply our method for the autonomous navigation of a platoon of connected vehicles on a simulation setting. We compare our design with the centralized NMPC design to show the computational benefits of the proposed distributed algorithm. In addition, we demonstrate our method for coordination of a heterogeneous team of robots (with different polytopic shapes).
Formation and Reconfiguration of Tight Multi-Lane Platoons
Mar 19, 2020
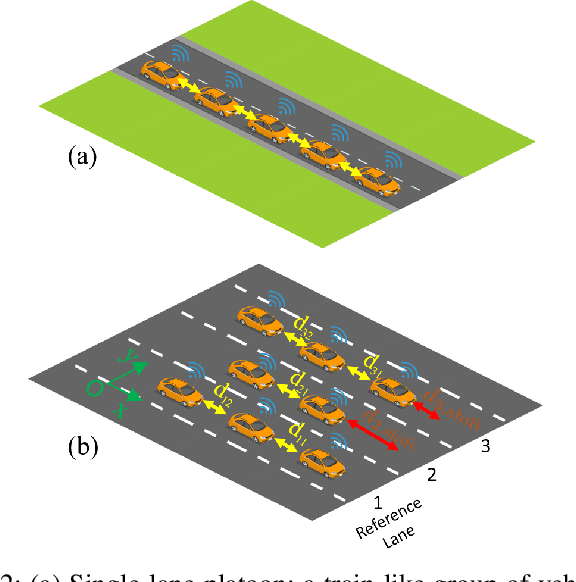
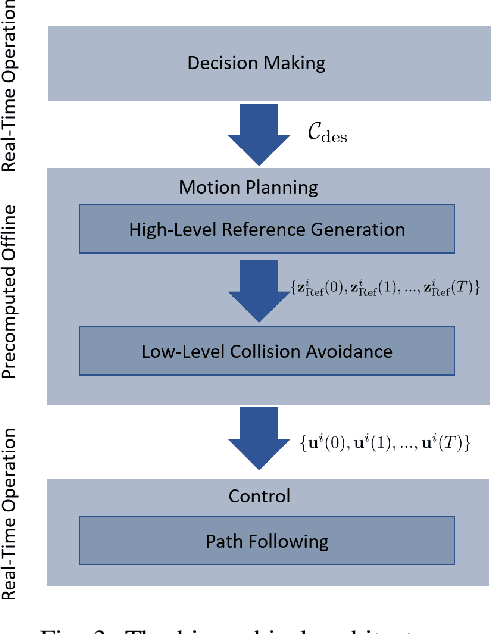
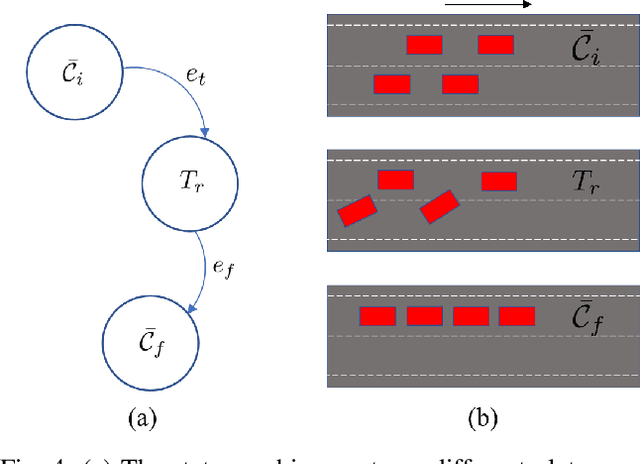
Advances in vehicular communication technologies are expected to facilitate cooperative driving in the future. Connected and Automated Vehicles (CAVs) are able to collaboratively plan and execute driving maneuvers by sharing their perceptual knowledge and future plans. In this paper, we present an architecture for autonomous navigation of tight multi-lane platoons travelling on public roads. Using the proposed approach, CAVs are able to form single or multi-lane platoons of various geometrical configurations. They are able to reshape and adjust their configurations according to changes in the environment. The proposed architecture consists of three main components: an online decision-maker, an offline motion planner and an online path-follower. The decision-maker selects the desired platoon configuration based on real-time information about the surrounding traffic. The motion planner uses an optimization-based approach for cooperative formation and reconfiguration in tight spaces. The motion planner uses a Model Predictive Control scheme to plan smooth, dynamically feasible and collision-free trajectories for all the vehicles within the platoon. The paper addresses online computation limitations by employing a family of maneuvers pre-computed offline and stored on the vehicles' control units to be executed by a low-level path-following feedback controller in real-time based on the selected desired configuration. We demonstrate the effectiveness of our approach through simulations of three case studies: 1) formation reconfiguration 2) obstacle avoidance, and 3) bench-marking against behavior-based planning in which the desired formation is achieved using a sequence of motion primitives. Videos and software can be found online here https://github.com/RoyaFiroozi/Centralized-Planning.
Improving Neural Network Classifier using Gradient-based Floating Centroid Method
Jul 21, 2019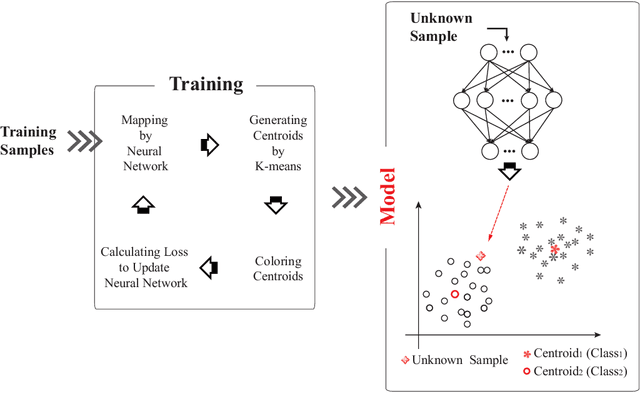
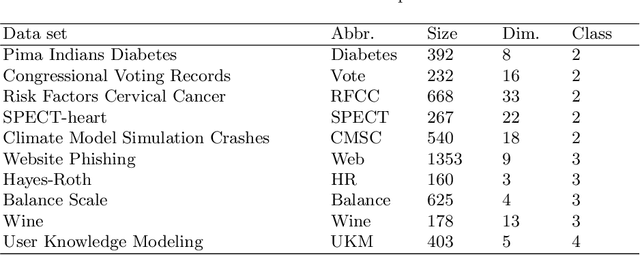
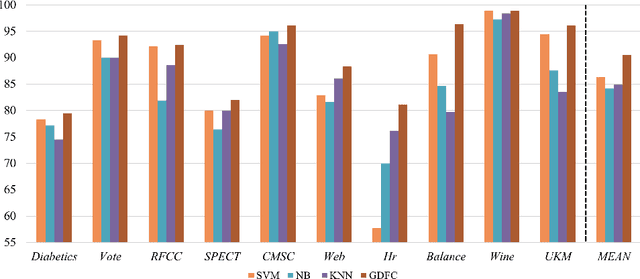
Floating centroid method (FCM) offers an efficient way to solve a fixed-centroid problem for the neural network classifiers. However, evolutionary computation as its optimization method restrains the FCM to achieve satisfactory performance for different neural network structures, because of the high computational complexity and inefficiency. Traditional gradient-based methods have been extensively adopted to optimize the neural network classifiers. In this study, a gradient-based floating centroid (GDFC) method is introduced to address the fixed centroid problem for the neural network classifiers optimized by gradient-based methods. Furthermore, a new loss function for optimizing GDFC is introduced. The experimental results display that GDFC obtains promising classification performance than the comparison methods on the benchmark datasets.