 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategizing at Speed: A Learned Model Predictive Game for Multi-Agent Drone Racing
Feb 06, 2026Autonomous drone racing pushes the boundaries of high-speed motion planning and multi-agent strategic decision-making. Success in this domain requires drones not only to navigate at their limits but also to anticipate and counteract competitors' actions. In this paper, we study a fundamental question that arises in this domain: how deeply should an agent strategize before taking an action? To this end, we compare two planning paradigms: the Model Predictive Game (MPG), which finds interaction-aware strategies at the expense of longer computation times, and contouring Model Predictive Control (MPC), which computes strategies rapidly but does not reason about interactions. We perform extensive experiments to study this trade-off, revealing that MPG outperforms MPC at moderate velocities but loses its advantage at higher speeds due to latency. To address this shortcoming, we propose a Learned Model Predictive Game (LMPG) approach that amortizes model predictive gameplay to reduce latency. In both simulation and hardware experiments, we benchmark our approach against MPG and MPC in head-to-head races, finding that LMPG outperforms both baselines.
From Data to Safe Mobile Robot Navigation: An Efficient and Modular Robust MPC Design Pipeline
Aug 09, 2025Model predictive control (MPC) is a powerful strategy for planning and control in autonomous mobile robot navigation. However, ensuring safety in real-world deployments remains challenging due to the presence of disturbances and measurement noise. Existing approaches often rely on idealized assumptions, neglect the impact of noisy measurements, and simply heuristically guess unrealistic bounds. In this work, we present an efficient and modular robust MPC design pipeline that systematically addresses these limitations. The pipeline consists of an iterative procedure that leverages closed-loop experimental data to estimate disturbance bounds and synthesize a robust output-feedback MPC scheme. We provide the pipeline in the form of deterministic and reproducible code to synthesize the robust output-feedback MPC from data. We empirically demonstrate robust constraint satisfaction and recursive feasibility in quadrotor simulations using Gazebo.
ASkDAgger: Active Skill-level Data Aggregation for Interactive Imitation Learning
Aug 07, 2025Human teaching effort is a significant bottleneck for the broader applicability of interactive imitation learning. To reduce the number of required queries, existing methods employ active learning to query the human teacher only in uncertain, risky, or novel situations. However, during these queries, the novice's planned actions are not utilized despite containing valuable information, such as the novice's capabilities, as well as corresponding uncertainty levels. To this end, we allow the novice to say: "I plan to do this, but I am uncertain." We introduce the Active Skill-level Data Aggregation (ASkDAgger) framework, which leverages teacher feedback on the novice plan in three key ways: (1) S-Aware Gating (SAG): Adjusts the gating threshold to track sensitivity, specificity, or a minimum success rate; (2) Foresight Interactive Experience Replay (FIER), which recasts valid and relabeled novice action plans into demonstrations; and (3) Prioritized Interactive Experience Replay (PIER), which prioritizes replay based on uncertainty, novice success, and demonstration age. Together, these components balance query frequency with failure incidence, reduce the number of required demonstration annotations, improve generalization, and speed up adaptation to changing domains. We validate the effectiveness of ASkDAgger through language-conditioned manipulation tasks in both simulation and real-world environments. Code, data, and videos are available at https://askdagger.github.io.
A Step-by-step Guide on Nonlinear Model Predictive Control for Safe Mobile Robot Navigation
Jul 23, 2025Designing a Model Predictive Control (MPC) scheme that enables a mobile robot to safely navigate through an obstacle-filled environment is a complicated yet essential task in robotics. In this technical report, safety refers to ensuring that the robot respects state and input constraints while avoiding collisions with obstacles despite the presence of disturbances and measurement noise. This report offers a step-by-step approach to implementing Nonlinear Model Predictive Control (NMPC) schemes addressing these safety requirements. Numerous books and survey papers provide comprehensive overviews of linear MPC (LMPC) \cite{bemporad2007robust,kouvaritakis2016model}, NMPC \cite{rawlings2017model,allgower2004nonlinear,mayne2014model,grune2017nonlinear,saltik2018outlook}, and their applications in various domains, including robotics \cite{nascimento2018nonholonomic,nguyen2021model,shi2021advanced,wei2022mpc}. This report does not aim to replicate those exhaustive reviews. Instead, it focuses specifically on NMPC as a foundation for safe mobile robot navigation. The goal is to provide a practical and accessible path from theoretical concepts to mathematical proofs and implementation, emphasizing safety and performance guarantees. It is intended for researchers, robotics engineers, and practitioners seeking to bridge the gap between theoretical NMPC formulations and real-world robotic applications. This report is not necessarily meant to remain fixed over time. If someone finds an error in the presented theory, please reach out via the given email addresses. We are happy to update the document if necessary.
A Vehicle System for Navigating Among Vulnerable Road Users Including Remote Operation
May 08, 2025



We present a vehicle system capable of navigating safely and efficiently around Vulnerable Road Users (VRUs), such as pedestrians and cyclists. The system comprises key modules for environment perception, localization and mapping, motion planning, and control, integrated into a prototype vehicle. A key innovation is a motion planner based on Topology-driven Model Predictive Control (T-MPC). The guidance layer generates multiple trajectories in parallel, each representing a distinct strategy for obstacle avoidance or non-passing. The underlying trajectory optimization constrains the joint probability of collision with VRUs under generic uncertainties. To address extraordinary situations ("edge cases") that go beyond the autonomous capabilities - such as construction zones or encounters with emergency responders - the system includes an option for remote human operation, supported by visual and haptic guidance. In simulation, our motion planner outperforms three baseline approaches in terms of safety and efficiency. We also demonstrate the full system in prototype vehicle tests on a closed track, both in autonomous and remotely operated modes.
EAGERx: Graph-Based Framework for Sim2real Robot Learning
Jul 05, 2024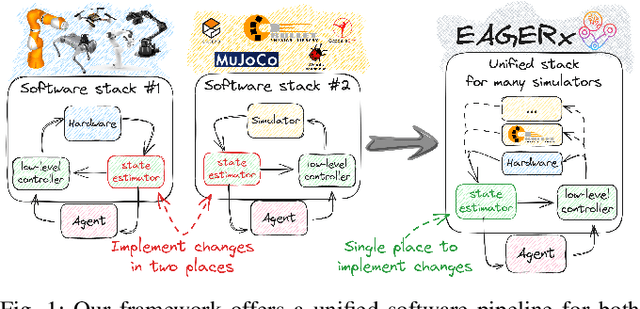
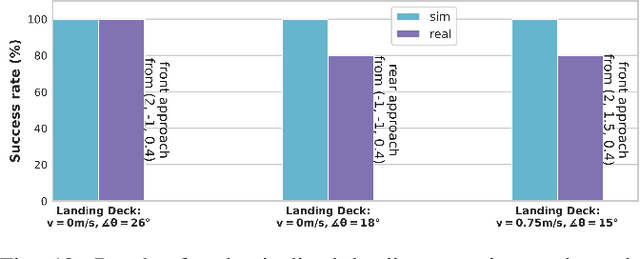
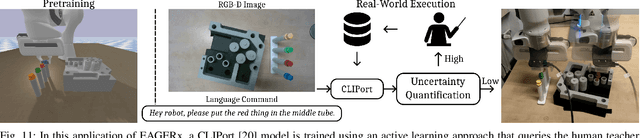
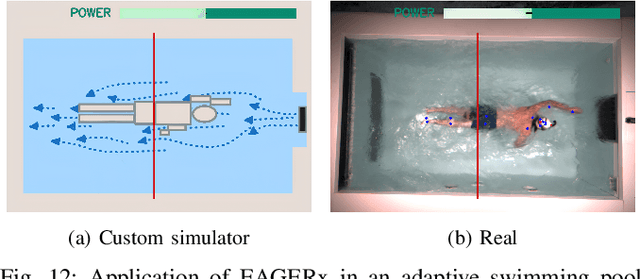
Sim2real, that is, the transfer of learned control policies from simulation to real world, is an area of growing interest in robotics due to its potential to efficiently handle complex tasks. The sim2real approach faces challenges due to mismatches between simulation and reality. These discrepancies arise from inaccuracies in modeling physical phenomena and asynchronous control, among other factors. To this end, we introduce EAGERx, a framework with a unified software pipeline for both real and simulated robot learning. It can support various simulators and aids in integrating state, action and time-scale abstractions to facilitate learning. EAGERx's integrated delay simulation, domain randomization features, and proposed synchronization algorithm contribute to narrowing the sim2real gap. We demonstrate (in the context of robot learning and beyond) the efficacy of EAGERx in accommodating diverse robotic systems and maintaining consistent simulation behavior. EAGERx is open source and its code is available at https://eagerx.readthedocs.io.
Embedded Hierarchical MPC for Autonomous Navigation
Jun 17, 2024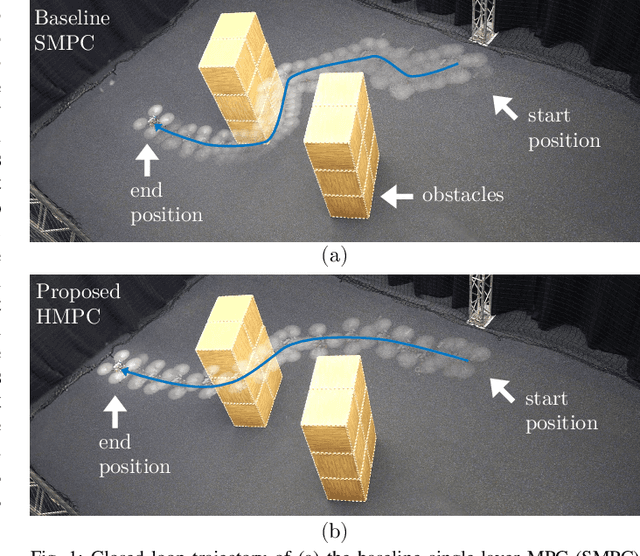
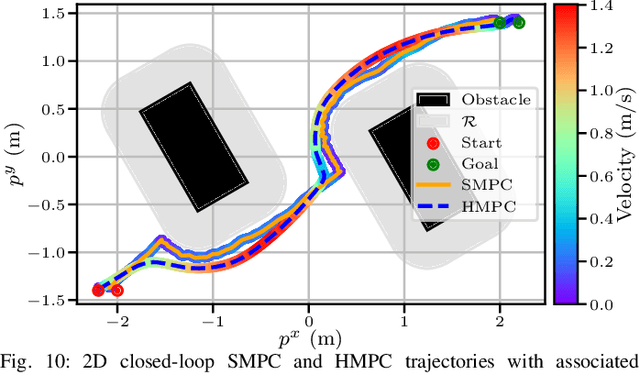
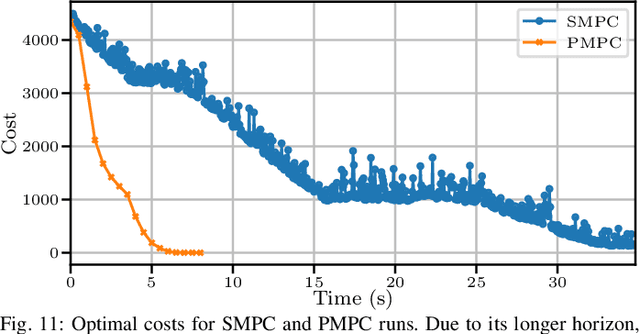
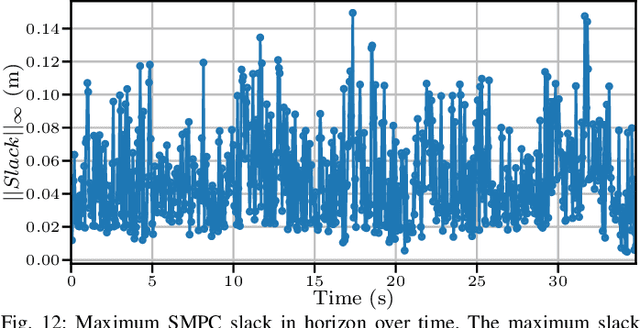
To efficiently deploy robotic systems in society, mobile robots need to autonomously and safely move through complex environments. Nonlinear model predictive control (MPC) methods provide a natural way to find a dynamically feasible trajectory through the environment without colliding with nearby obstacles. However, the limited computation power available on typical embedded robotic systems, such as quadrotors, poses a challenge to running MPC in real-time, including its most expensive tasks: constraints generation and optimization. To address this problem, we propose a novel hierarchical MPC scheme that interconnects a planning and a tracking layer. The planner constructs a trajectory with a long prediction horizon at a slow rate, while the tracker ensures trajectory tracking at a relatively fast rate. We prove that the proposed framework avoids collisions and is recursively feasible. Furthermore, we demonstrate its effectiveness in simulations and lab experiments with a quadrotor that needs to reach a goal position in a complex static environment. The code is efficiently implemented on the quadrotor's embedded computer to ensure real-time feasibility. Compared to a state-of-the-art single-layer MPC formulation, this allows us to increase the planning horizon by a factor of 5, which results in significantly better performance.
DART: A Compact Platform For Autonomous Driving Research
Feb 12, 2024This paper presents the design of a research platform for autonomous driving applications, the Delft's Autonomous-driving Robotic Testbed (DART). Our goal was to design a small-scale car-like robot equipped with all the hardware needed for on-board navigation and control while keeping it cost-effective and easy to replicate. To develop DART, we built on an existing off-the-shelf model and augmented its sensor suite to improve its capabilities for control and motion planning tasks. We detail the hardware setup and the system identification challenges to derive the vehicle's models. Furthermore, we present some use cases where we used DART to test different motion planning applications to show the versatility of the platform. Finally, we provide a git repository with all the details to replicate DART, complete with a simulation environment and the data used for system identification.
Topology-Driven Parallel Trajectory Optimization in Dynamic Environments
Jan 11, 2024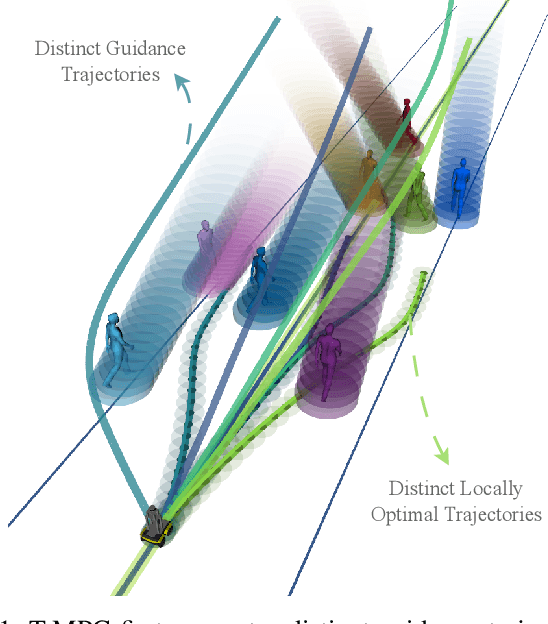
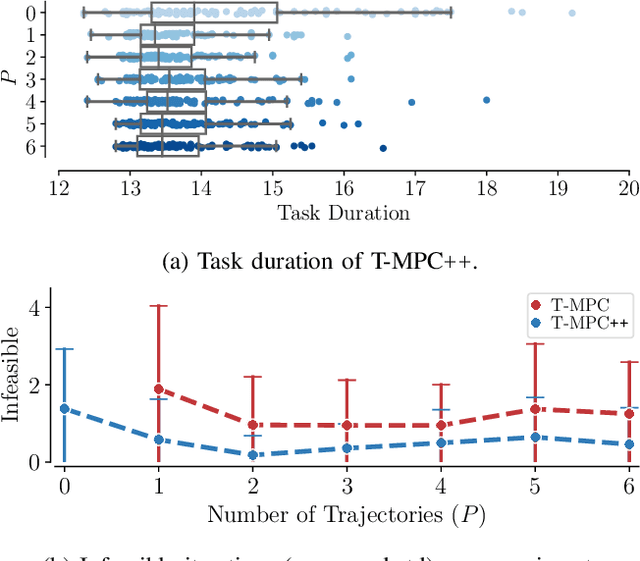
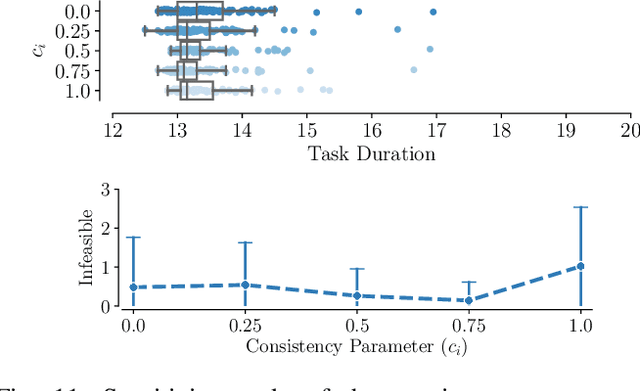

Ground robots navigating in complex, dynamic environments must compute collision-free trajectories to avoid obstacles safely and efficiently. Nonconvex optimization is a popular method to compute a trajectory in real-time. However, these methods often converge to locally optimal solutions and frequently switch between different local minima, leading to inefficient and unsafe robot motion. In this work, We propose a novel topology-driven trajectory optimization strategy for dynamic environments that plans multiple distinct evasive trajectories to enhance the robot's behavior and efficiency. A global planner iteratively generates trajectories in distinct homotopy classes. These trajectories are then optimized by local planners working in parallel. While each planner shares the same navigation objectives, they are locally constrained to a specific homotopy class, meaning each local planner attempts a different evasive maneuver. The robot then executes the feasible trajectory with the lowest cost in a receding horizon manner. We demonstrate, on a mobile robot navigating among pedestrians, that our approach leads to faster and safer trajectories than existing planners.
Rule-Based Lloyd Algorithm for Multi-Robot Motion Planning and Control with Safety and Convergence Guarantees
Oct 30, 2023This paper presents a distributed rule-based Lloyd algorithm (RBL) for multi-robot motion planning and control. The main limitations of the basic Loyd-based algorithm (LB) concern deadlock issues and the failure to address dynamic constraints effectively. Our contribution is twofold. First, we show how RBL is able to provide safety and convergence to the goal region without relying on communication between robots, nor neighbors control inputs, nor synchronization between the robots. We considered both case of holonomic and non-holonomic robots with control inputs saturation. Second, we show that the Lloyd-based algorithm (without rules) can be successfully used as a safety layer for learning-based approaches, leading to non-negligible benefits. We further prove the soundness, reliability, and scalability of RBL through extensive simulations, an updated comparison with the state of the art, and experimental validations on small-scale car-like robots.