 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASkDAgger: Active Skill-level Data Aggregation for Interactive Imitation Learning
Aug 07, 2025Human teaching effort is a significant bottleneck for the broader applicability of interactive imitation learning. To reduce the number of required queries, existing methods employ active learning to query the human teacher only in uncertain, risky, or novel situations. However, during these queries, the novice's planned actions are not utilized despite containing valuable information, such as the novice's capabilities, as well as corresponding uncertainty levels. To this end, we allow the novice to say: "I plan to do this, but I am uncertain." We introduce the Active Skill-level Data Aggregation (ASkDAgger) framework, which leverages teacher feedback on the novice plan in three key ways: (1) S-Aware Gating (SAG): Adjusts the gating threshold to track sensitivity, specificity, or a minimum success rate; (2) Foresight Interactive Experience Replay (FIER), which recasts valid and relabeled novice action plans into demonstrations; and (3) Prioritized Interactive Experience Replay (PIER), which prioritizes replay based on uncertainty, novice success, and demonstration age. Together, these components balance query frequency with failure incidence, reduce the number of required demonstration annotations, improve generalization, and speed up adaptation to changing domains. We validate the effectiveness of ASkDAgger through language-conditioned manipulation tasks in both simulation and real-world environments. Code, data, and videos are available at https://askdagger.github.io.
EAGERx: Graph-Based Framework for Sim2real Robot Learning
Jul 05, 2024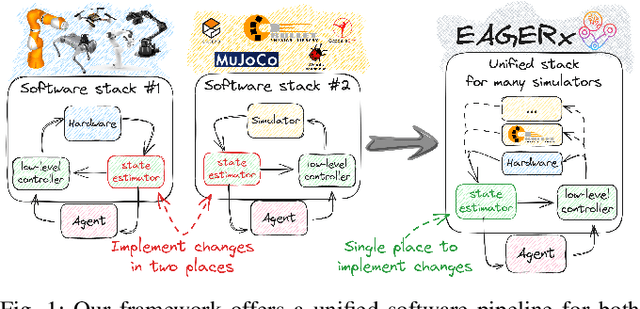
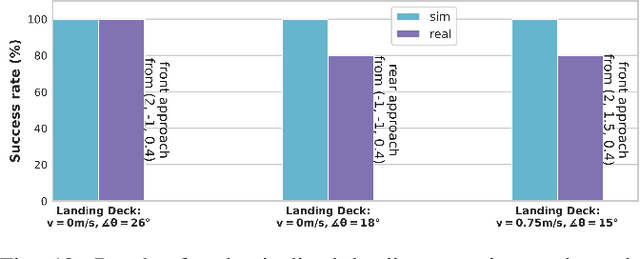
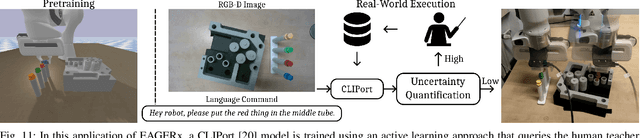
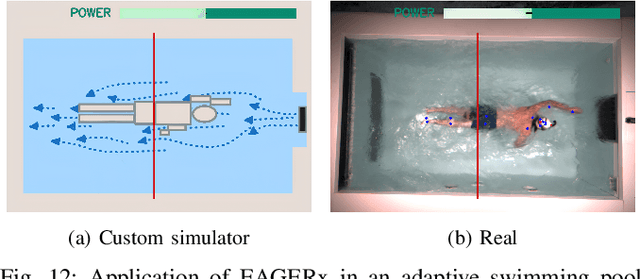
Sim2real, that is, the transfer of learned control policies from simulation to real world, is an area of growing interest in robotics due to its potential to efficiently handle complex tasks. The sim2real approach faces challenges due to mismatches between simulation and reality. These discrepancies arise from inaccuracies in modeling physical phenomena and asynchronous control, among other factors. To this end, we introduce EAGERx, a framework with a unified software pipeline for both real and simulated robot learning. It can support various simulators and aids in integrating state, action and time-scale abstractions to facilitate learning. EAGERx's integrated delay simulation, domain randomization features, and proposed synchronization algorithm contribute to narrowing the sim2real gap. We demonstrate (in the context of robot learning and beyond) the efficacy of EAGERx in accommodating diverse robotic systems and maintaining consistent simulation behavior. EAGERx is open source and its code is available at https://eagerx.readthedocs.io.
ExploRLLM: Guiding Exploration in Reinforcement Learning with Large Language Models
Mar 15, 2024



In image-based robot manipulation tasks with large observation and action spaces, reinforcement learning struggles with low sample efficiency, slow training speed, and uncertain convergence. As an alternative, large pre-trained foundation models have shown promise in robotic manipulation, particularly in zero-shot and few-shot applications. However, using these models directly is unreliable due to limited reasoning capabilities and challenges in understanding physical and spatial contexts. This paper introduces ExploRLLM, a novel approach that leverages the inductive bias of foundation models (e.g. Large Language Models) to guide exploration in reinforcement learning. We also exploit these foundation models to reformulate the action and observation spaces to enhance the training efficiency in reinforcement learning. Our experiments demonstrate that guided exploration enables much quicker convergence than training without it. Additionally, we validate that ExploRLLM outperforms vanilla foundation model baselines and that the policy trained in simulation can be applied in real-world settings without additional training.
PARTNR: Pick and place Ambiguity Resolving by Trustworthy iNteractive leaRning
Nov 15, 2022Several recent works show impressive results in mapping language-based human commands and image scene observations to direct robot executable policies (e.g., pick and place poses). However, these approaches do not consider the uncertainty of the trained policy and simply always execute actions suggested by the current policy as the most probable ones. This makes them vulnerable to domain shift and inefficient in the number of required demonstrations. We extend previous works and present the PARTNR algorithm that can detect ambiguities in the trained policy by analyzing multiple modalities in the pick and place poses using topological analysis. PARTNR employs an adaptive, sensitivity-based, gating function that decides if additional user demonstrations are required. User demonstrations are aggregated to the dataset and used for subsequent training. In this way, the policy can adapt promptly to domain shift and it can minimize the number of required demonstrations for a well-trained policy. The adaptive threshold enables to achieve the user-acceptable level of ambiguity to execute the policy autonomously and in turn, increase the trustworthiness of our system. We demonstrate the performance of PARTNR in a table-top pick and place task.