 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Self-Evolving Agentic Framework for Metasurface Inverse Design
Apr 01, 2026Metasurface inverse design has become central to realizing complex optical functionality, yet translating target responses into executable, solver-compatible workflows still demands specialized expertise in computational electromagnetics and solver-specific software engineering. Recent large language models (LLMs) offer a complementary route to reducing this workflow-construction burden, but existing language-driven systems remain largely session-bounded and do not preserve reusable workflow knowledge across inverse-design tasks. We present an agentic framework for metasurface inverse design that addresses this limitation through context-level skill evolution. The framework couples a coding agent, evolving skill artifacts, and a deterministic evaluator grounded in physical simulation so that solver-specific strategies can be iteratively refined across tasks without modifying model weights or the underlying physics solver. We evaluate the framework on a benchmark spanning multiple metasurface inverse-design task types, with separate training-aligned and held-out task families. Evolved skills raise in-distribution task success from 38% to 74%, increase criteria pass fraction from 0.510 to 0.870, and reduce average attempts from 4.10 to 2.30. On held-out task families, binary success changes only marginally, but improvements in best margin together with shifts in error composition and agent behavior indicate partial transfer of workflow knowledge. These results suggest that the main value of skill evolution lies in accumulating reusable solver-specific expertise around reliable computational engines, thereby offering a practical path toward more autonomous and accessible metasurface inverse-design workflows.
Deep Research for Recommender Systems
Mar 08, 2026The technical foundations of recommender systems have progressed from collaborative filtering to complex neural models and, more recently, large language models. Despite these technological advances, deployed systems often underserve their users by simply presenting a list of items, leaving the burden of exploration, comparison, and synthesis entirely on the user. This paper argues that this traditional "tool-based" paradigm fundamentally limits user experience, as the system acts as a passive filter rather than an active assistant. To address this limitation, we propose a novel deep research paradigm for recommendation, which replaces conventional item lists with comprehensive, user-centric reports. We instantiate this paradigm through RecPilot, a multi-agent framework comprising two core components: a user trajectory simulation agent that autonomously explores the item space, and a self-evolving report generation agent that synthesizes the findings into a coherent, interpretable report tailored to support user decisions. This approach reframes recommendation as a proactive, agent-driven service. Extensive experiments on public datasets demonstrate that RecPilot not only achieves strong performance in modeling user behaviors but also generates highly persuasive reports that substantially reduce user effort in item evaluation, validating the potential of this new interaction paradigm.
VII: Visual Instruction Injection for Jailbreaking Image-to-Video Generation Models
Feb 24, 2026Image-to-Video (I2V) generation models, which condition video generation on reference images, have shown emerging visual instruction-following capability, allowing certain visual cues in reference images to act as implicit control signals for video generation. However, this capability also introduces a previously overlooked risk: adversaries may exploit visual instructions to inject malicious intent through the image modality. In this work, we uncover this risk by proposing Visual Instruction Injection (VII), a training-free and transferable jailbreaking framework that intentionally disguises the malicious intent of unsafe text prompts as benign visual instructions in the safe reference image. Specifically, VII coordinates a Malicious Intent Reprogramming module to distill malicious intent from unsafe text prompts while minimizing their static harmfulness, and a Visual Instruction Grounding module to ground the distilled intent onto a safe input image by rendering visual instructions that preserve semantic consistency with the original unsafe text prompt, thereby inducing harmful content during I2V generation. Empirically, our extensive experiments on four state-of-the-art commercial I2V models (Kling-v2.5-turbo, Gemini Veo-3.1, Seedance-1.5-pro, and PixVerse-V5) demonstrate that VII achieves Attack Success Rates of up to 83.5% while reducing Refusal Rates to near zero, significantly outperforming existing baselines.
Improving LLM-based Recommendation with Self-Hard Negatives from Intermediate Layers
Feb 19, 2026Large language models (LLMs) have shown great promise in recommender systems, where supervised fine-tuning (SFT) is commonly used for adaptation. Subsequent studies further introduce preference learning to incorporate negative samples into the training process. However, existing methods rely on sequence-level, offline-generated negatives, making them less discriminative and informative when adapting LLMs to recommendation tasks with large negative item spaces. To address these challenges, we propose ILRec, a novel preference fine-tuning framework for LLM-based recommendation, leveraging self-hard negative signals extracted from intermediate layers to improve preference learning. Specifically, we identify self-hard negative tokens from intermediate layers as fine-grained negative supervision that dynamically reflects the model's preference learning process. To effectively integrate these signals into training, we design a two-stage framework comprising cross-layer preference optimization and cross-layer preference distillation, enabling the model to jointly discriminate informative negatives and enhance the quality of negative signals from intermediate layers. In addition, we introduce a lightweight collaborative filtering model to assign token-level rewards for negative signals, mitigating the risk of over-penalizing false negatives. Extensive experiments on three datasets demonstrate ILRec's effectiveness in enhancing the performance of LLM-based recommender systems.
A Hybrid Early-Exit Algorithm for Large Language Models Based on Space Alignment Decoding (SPADE)
Jul 23, 2025Large language models are computationally expensive due to their deep structures. Prior research has shown that intermediate layers contain sufficient information to generate accurate answers, leading to the development of early-exit algorithms that reduce inference costs by terminating computation at earlier layers. However, these methods often suffer from poor performance due to misalignment between intermediate and output layer representations that lead to decoding inaccuracy. To address these challenges, we propose SPADE (SPace Alignment DEcoding), a novel decoding method that aligns intermediate layer representations with the output layer by propagating a minimally reduced sequence consisting of only the start token and the answer token. We further optimize the early-exit decision-making process by training a linear approximation of SPADE that computes entropy-based confidence metrics. Putting them together, we create a hybrid early-exit algorithm that monitors confidence levels and stops inference at intermediate layers while using SPADE to generate high-quality outputs. This approach significantly reduces inference costs without compromising accuracy, offering a scalable and efficient solution for deploying large language models in real-world applications.
Integrated Pipeline for Monocular 3D Reconstruction and Finite Element Simulation in Industrial Applications
Jun 16, 2025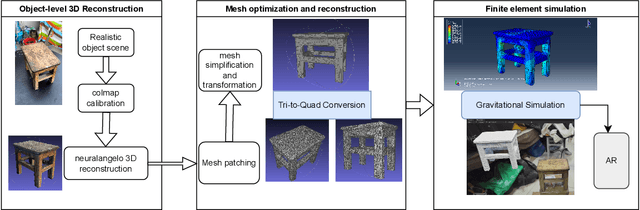
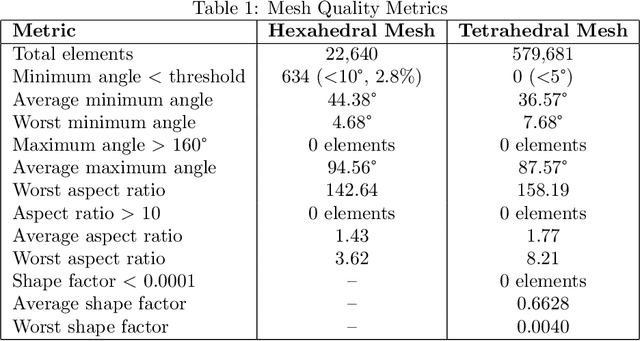
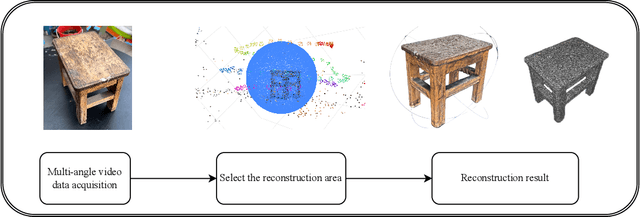
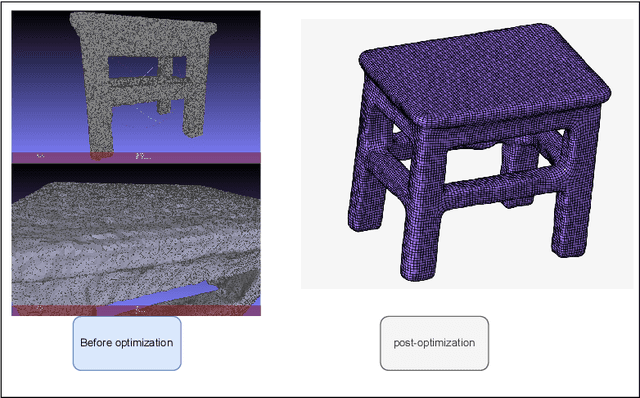
To address the challenges of 3D modeling and structural simulation in industrial environment, such as the difficulty of equipment deployment, and the difficulty of balancing accuracy and real-time performance, this paper proposes an integrated workflow, which integrates high-fidelity 3D reconstruction based on monocular video, finite element simulation analysis, and mixed reality visual display, aiming to build an interactive digital twin system for industrial inspection, equipment maintenance and other scenes. Firstly, the Neuralangelo algorithm based on deep learning is used to reconstruct the 3D mesh model with rich details from the surround-shot video. Then, the QuadRemesh tool of Rhino is used to optimize the initial triangular mesh and generate a structured mesh suitable for finite element analysis. The optimized mesh is further discretized by HyperMesh, and the material parameter setting and stress simulation are carried out in Abaqus to obtain high-precision stress and deformation results. Finally, combined with Unity and Vuforia engine, the real-time superposition and interactive operation of simulation results in the augmented reality environment are realized, which improves users 'intuitive understanding of structural response. Experiments show that the method has good simulation efficiency and visualization effect while maintaining high geometric accuracy. It provides a practical solution for digital modeling, mechanical analysis and interactive display in complex industrial scenes, and lays a foundation for the deep integration of digital twin and mixed reality technology in industrial applications.
Revisiting Diffusion Models: From Generative Pre-training to One-Step Generation
Jun 11, 2025Diffusion distillation is a widely used technique to reduce the sampling cost of diffusion models, yet it often requires extensive training, and the student performance tends to be degraded. Recent studies show that incorporating a GAN objective may alleviate these issues, yet the underlying mechanism remains unclear. In this work, we first identify a key limitation of distillation: mismatched step sizes and parameter numbers between the teacher and the student model lead them to converge to different local minima, rendering direct imitation suboptimal. We further demonstrate that a standalone GAN objective, without relying a distillation loss, overcomes this limitation and is sufficient to convert diffusion models into efficient one-step generators. Based on this finding, we propose that diffusion training may be viewed as a form of generative pre-training, equipping models with capabilities that can be unlocked through lightweight GAN fine-tuning. Supporting this view, we create a one-step generation model by fine-tuning a pre-trained model with 85% of parameters frozen, achieving strong performance with only 0.2M images and near-SOTA results with 5M images. We further present a frequency-domain analysis that may explain the one-step generative capability gained in diffusion training. Overall, our work provides a new perspective for diffusion training, highlighting its role as a powerful generative pre-training process, which can be the basis for building efficient one-step generation models.
Minute-Long Videos with Dual Parallelisms
May 29, 2025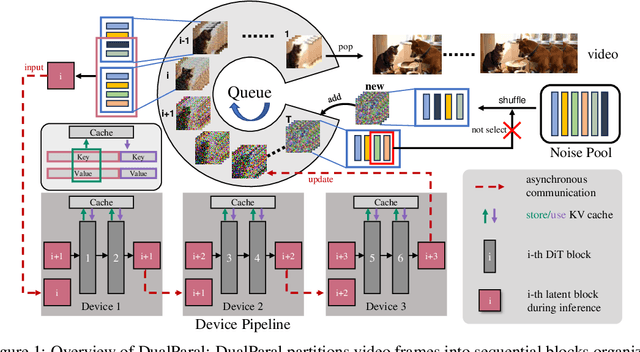



Diffusion Transformer (DiT)-based video diffusion models generate high-quality videos at scale but incur prohibitive processing latency and memory costs for long videos. To address this, we propose a novel distributed inference strategy, termed DualParal. The core idea is that, instead of generating an entire video on a single GPU, we parallelize both temporal frames and model layers across GPUs. However, a naive implementation of this division faces a key limitation: since diffusion models require synchronized noise levels across frames, this implementation leads to the serialization of original parallelisms. We leverage a block-wise denoising scheme to handle this. Namely, we process a sequence of frame blocks through the pipeline with progressively decreasing noise levels. Each GPU handles a specific block and layer subset while passing previous results to the next GPU, enabling asynchronous computation and communication. To further optimize performance, we incorporate two key enhancements. Firstly, a feature cache is implemented on each GPU to store and reuse features from the prior block as context, minimizing inter-GPU communication and redundant computation. Secondly, we employ a coordinated noise initialization strategy, ensuring globally consistent temporal dynamics by sharing initial noise patterns across GPUs without extra resource costs. Together, these enable fast, artifact-free, and infinitely long video generation. Applied to the latest diffusion transformer video generator, our method efficiently produces 1,025-frame videos with up to 6.54$\times$ lower latency and 1.48$\times$ lower memory cost on 8$\times$RTX 4090 GPUs.
LARES: Latent Reasoning for Sequential Recommendation
May 22, 2025Sequential recommender systems have become increasingly important in real-world applications that model user behavior sequences to predict their preferences. However, existing sequential recommendation methods predominantly rely on non-reasoning paradigms, which may limit the model's computational capacity and result in suboptimal recommendation performance. To address these limitations, we present LARES, a novel and scalable LAtent REasoning framework for Sequential recommendation that enhances model's representation capabilities through increasing the computation density of parameters by depth-recurrent latent reasoning. Our proposed approach employs a recurrent architecture that allows flexible expansion of reasoning depth without increasing parameter complexity, thereby effectively capturing dynamic and intricate user interest patterns. A key difference of LARES lies in refining all input tokens at each implicit reasoning step to improve the computation utilization. To fully unlock the model's reasoning potential, we design a two-phase training strategy: (1) Self-supervised pre-training (SPT) with dual alignment objectives; (2) Reinforcement post-training (RPT). During the first phase, we introduce trajectory-level alignment and step-level alignment objectives, which enable the model to learn recommendation-oriented latent reasoning patterns without requiring supplementary annotated data. The subsequent phase utilizes reinforcement learning (RL) to harness the model's exploratory ability, further refining its reasoning capabilities. Comprehensive experiments on real-world benchmarks demonstrate our framework's superior performance. Notably, LARES exhibits seamless compatibility with existing advanced models, further improving their recommendation performance.
DeepRec: Towards a Deep Dive Into the Item Space with Large Language Model Based Recommendation
May 22, 2025Recently, large language models (LLMs) have been introduced into recommender systems (RSs), either to enhance traditional recommendation models (TRMs) or serve as recommendation backbones. However, existing LLM-based RSs often do not fully exploit the complementary advantages of LLMs (e.g., world knowledge and reasoning) and TRMs (e.g., recommendation-specific knowledge and efficiency) to fully explore the item space. To address this, we propose DeepRec, a novel LLM-based RS that enables autonomous multi-turn interactions between LLMs and TRMs for deep exploration of the item space. In each interaction turn, LLMs reason over user preferences and interact with TRMs to retrieve candidate items. After multi-turn interactions, LLMs rank the retrieved items to generate the final recommendations. We adopt reinforcement learning(RL) based optimization and propose novel designs from three aspects: recommendation model based data rollout, recommendation-oriented hierarchical rewards, and a two-stage RL training strategy. For data rollout, we introduce a preference-aware TRM, with which LLMs interact to construct trajectory data. For rewards, we design a hierarchical reward function that involves both process-level and outcome-level rewards to optimize the interaction process and recommendation performance, respectively. For RL training, we develop a two-stage training strategy, where the first stage aims to guide LLMs to interact with TRMs and the second stage focuses on performance improvement. Experiments on public datasets demonstrate that DeepRec significantly outperforms both traditional and LLM-based baselines, offering a new paradigm for deep exploration in recommendation systems.