 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-training Generative Recommender with Multi-Identifier Item Tokenization
Apr 06, 2025Generative recommendation autoregressively generates item identifiers to recommend potential items. Existing methods typically adopt a one-to-one mapping strategy, where each item is represented by a single identifier. However, this scheme poses issues, such as suboptimal semantic modeling for low-frequency items and limited diversity in token sequence data. To overcome these limitations, we propose MTGRec, which leverages Multi-identifier item Tokenization to augment token sequence data for Generative Recommender pre-training. Our approach involves two key innovations: multi-identifier item tokenization and curriculum recommender pre-training. For multi-identifier item tokenization, we leverage the RQ-VAE as the tokenizer backbone and treat model checkpoints from adjacent training epochs as semantically relevant tokenizers. This allows each item to be associated with multiple identifiers, enabling a single user interaction sequence to be converted into several token sequences as different data groups. For curriculum recommender pre-training, we introduce a curriculum learning scheme guided by data influence estimation, dynamically adjusting the sampling probability of each data group during recommender pre-training. After pre-training, we fine-tune the model using a single tokenizer to ensure accurate item identification for recommendation. Extensive experiments on three public benchmark datasets demonstrate that MTGRec significantly outperforms both traditional and generative recommendation baselines in terms of effectiveness and scalability.
A Novel Bi-directional Interrelated Model for Joint Intent Detection and Slot Filling
Jun 30, 2019
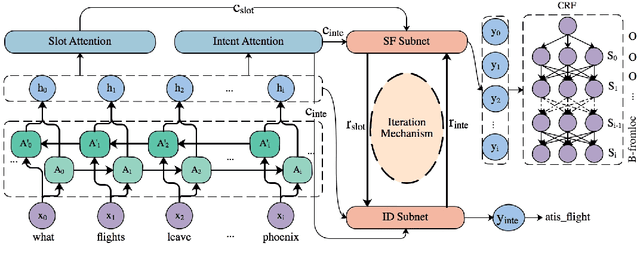
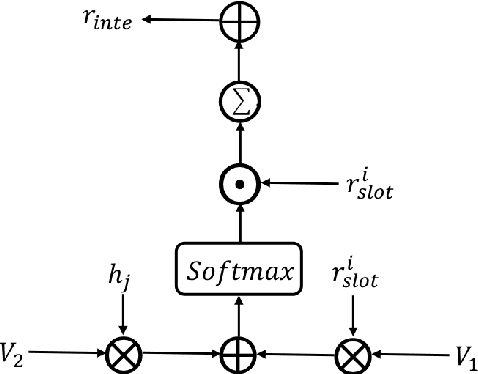
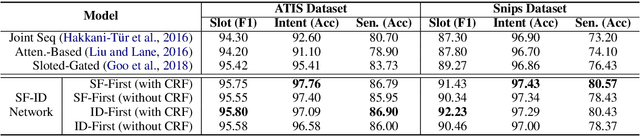
A spoken language understanding (SLU) system includes two main tasks, slot filling (SF) and intent detection (ID). The joint model for the two tasks is becoming a tendency in SLU. But the bi-directional interrelated connections between the intent and slots are not established in the existing joint models. In this paper, we propose a novel bi-directional interrelated model for joint intent detection and slot filling. We introduce an SF-ID network to establish direct connections for the two tasks to help them promote each other mutually. Besides, we design an entirely new iteration mechanism inside the SF-ID network to enhance the bi-directional interrelated connections. The experimental results show that the relative improvement in the sentence-level semantic frame accuracy of our model is 3.79% and 5.42% on ATIS and Snips datasets, respectively, compared to the state-of-the-art model.