 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTARec: An Efficient Agent Framework for Recommender Systems via Autonomous Deliberate Reasoning
Aug 26, 2025While modern recommender systems are instrumental in navigating information abundance, they remain fundamentally limited by static user modeling and reactive decision-making paradigms. Current large language model (LLM)-based agents inherit these shortcomings through their overreliance on heuristic pattern matching, yielding recommendations prone to shallow correlation bias, limited causal inference, and brittleness in sparse-data scenarios. We introduce STARec, a slow-thinking augmented agent framework that endows recommender systems with autonomous deliberative reasoning capabilities. Each user is modeled as an agent with parallel cognitions: fast response for immediate interactions and slow reasoning that performs chain-of-thought rationales. To cultivate intrinsic slow thinking, we develop anchored reinforcement training - a two-stage paradigm combining structured knowledge distillation from advanced reasoning models with preference-aligned reward shaping. This hybrid approach scaffolds agents in acquiring foundational capabilities (preference summarization, rationale generation) while enabling dynamic policy adaptation through simulated feedback loops. Experiments on MovieLens 1M and Amazon CDs benchmarks demonstrate that STARec achieves substantial performance gains compared with state-of-the-art baselines, despite using only 0.4% of the full training data.
Pre-training Generative Recommender with Multi-Identifier Item Tokenization
Apr 06, 2025Generative recommendation autoregressively generates item identifiers to recommend potential items. Existing methods typically adopt a one-to-one mapping strategy, where each item is represented by a single identifier. However, this scheme poses issues, such as suboptimal semantic modeling for low-frequency items and limited diversity in token sequence data. To overcome these limitations, we propose MTGRec, which leverages Multi-identifier item Tokenization to augment token sequence data for Generative Recommender pre-training. Our approach involves two key innovations: multi-identifier item tokenization and curriculum recommender pre-training. For multi-identifier item tokenization, we leverage the RQ-VAE as the tokenizer backbone and treat model checkpoints from adjacent training epochs as semantically relevant tokenizers. This allows each item to be associated with multiple identifiers, enabling a single user interaction sequence to be converted into several token sequences as different data groups. For curriculum recommender pre-training, we introduce a curriculum learning scheme guided by data influence estimation, dynamically adjusting the sampling probability of each data group during recommender pre-training. After pre-training, we fine-tune the model using a single tokenizer to ensure accurate item identification for recommendation. Extensive experiments on three public benchmark datasets demonstrate that MTGRec significantly outperforms both traditional and generative recommendation baselines in terms of effectiveness and scalability.
EulerFormer: Sequential User Behavior Modeling with Complex Vector Attention
Apr 04, 2024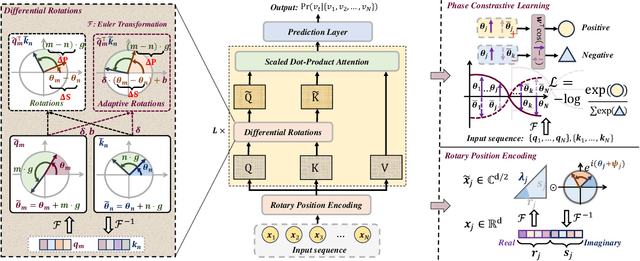
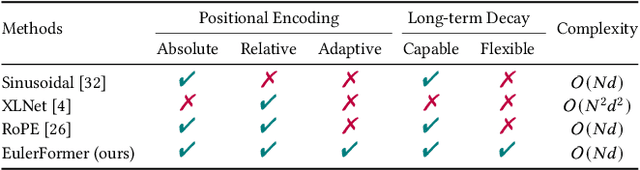
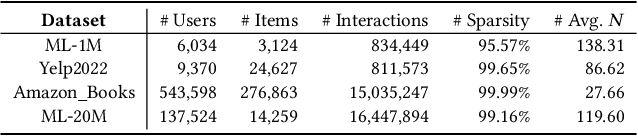
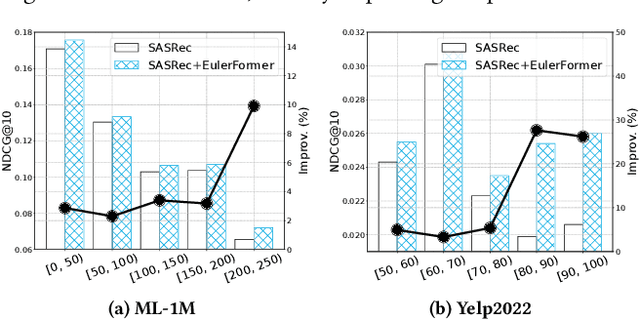
To capture user preference, transformer models have been widely applied to model sequential user behavior data. The core of transformer architecture lies in the self-attention mechanism, which computes the pairwise attention scores in a sequence. Due to the permutation-equivariant nature, positional encoding is used to enhance the attention between token representations. In this setting, the pairwise attention scores can be derived by both semantic difference and positional difference. However, prior studies often model the two kinds of difference measurements in different ways, which potentially limits the expressive capacity of sequence modeling. To address this issue, this paper proposes a novel transformer variant with complex vector attention, named EulerFormer, which provides a unified theoretical framework to formulate both semantic difference and positional difference. The EulerFormer involves two key technical improvements. First, it employs a new transformation function for efficiently transforming the sequence tokens into polar-form complex vectors using Euler's formula, enabling the unified modeling of both semantic and positional information in a complex rotation form.Secondly, it develops a differential rotation mechanism, where the semantic rotation angles can be controlled by an adaptation function, enabling the adaptive integration of the semantic and positional information according to the semantic contexts.Furthermore, a phase contrastive learning task is proposed to improve the isotropy of contextual representations in EulerFormer. Our theoretical framework possesses a high degree of completeness and generality. It is more robust to semantic variations and possesses moresuperior theoretical properties in principle. Extensive experiments conducted on four public datasets demonstrate the effectiveness and efficiency of our approach.
RA-Rec: An Efficient ID Representation Alignment Framework for LLM-based Recommendation
Feb 07, 2024



Large language models (LLM) have recently emerged as a powerful tool for a variety of natural language processing tasks, bringing a new surge of combining LLM with recommendation systems, termed as LLM-based RS. Current approaches generally fall into two main paradigms, the ID direct usage paradigm and the ID translation paradigm, noting their core weakness stems from lacking recommendation knowledge and uniqueness. To address this limitation, we propose a new paradigm, ID representation, which incorporates pre-trained ID embeddings into LLMs in a complementary manner. In this work, we present RA-Rec, an efficient ID representation alignment framework for LLM-based recommendation, which is compatible with multiple ID-based methods and LLM architectures. Specifically, we treat ID embeddings as soft prompts and design an innovative alignment module and an efficient tuning method with tailored data construction for alignment. Extensive experiments demonstrate RA-Rec substantially outperforms current state-of-the-art methods, achieving up to 3.0% absolute HitRate@100 improvements while utilizing less than 10x training data.