 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Behaviors of Evolutionary Algorithms on GPUs: When Does Parallelism Pay Off?
Jan 27, 2026Evolutionary algorithms (EAs) are increasingly implemented on graphics processing units (GPUs) to leverage parallel processing capabilities for enhanced efficiency. However, existing studies largely emphasize the raw speedup obtained by porting individual algorithms from CPUs to GPUs. Consequently, these studies offer limited insight into when and why GPU parallelism fundamentally benefits EAs. To address this gap, we investigate how GPU parallelism alters the behavior of EAs beyond simple acceleration metrics. We conduct a systematic empirical study of 16 representative EAs on 30 benchmark problems. Specifically, we compare CPU and GPU executions across a wide range of problem dimensionalities and population sizes. Our results reveal that the impact of GPU acceleration is highly heterogeneous and depends strongly on algorithmic structure. We further demonstrate that conventional fixed-budget evaluation based on the number of function evaluations (FEs) is inadequate for GPU execution. In contrast, fixed-time evaluation uncovers performance characteristics that are unobservable under small or practically constrained FE budgets, particularly for adaptive and exploration-oriented algorithms. Moreover, we identify distinct scaling regimes in which GPU parallelism is beneficial, saturates, or degrades as problem dimensionality and population size increase. Crucially, we show that large populations enabled by GPUs not only improve hardware utilization but also reveal algorithm-specific convergence and diversity dynamics that are difficult to observe under CPU-constrained settings. Consequently, our findings indicate that GPU parallelism is not strictly an implementation detail, but a pivotal factor that influences how EAs should be evaluated, compared, and designed for modern computing platforms.
Learning to Evolve with Convergence Guarantee via Neural Unrolling
Dec 12, 2025The transition from hand-crafted heuristics to data-driven evolutionary algorithms faces a fundamental dilemma: achieving neural plasticity without sacrificing mathematical stability. Emerging learned optimizers demonstrate high adaptability. However, they often lack rigorous convergence guarantees. This deficiency results in unpredictable behaviors on unseen landscapes. To address this challenge, we introduce Learning to Evolve (L2E), a unified bilevel meta-optimization framework. This method reformulates evolutionary search as a Neural Unrolling process grounded in Krasnosel'skii-Mann (KM) fixed-point theory. First, L2E models a coupled dynamic system in which the inner loop enforces a strict contractive trajectory via a structured Mamba-based neural operator. Second, the outer loop optimizes meta-parameters to align the fixed point of the operator with the target objective minimizers. Third, we design a gradient-derived composite solver that adaptively fuses learned evolutionary proposals with proxy gradient steps, thereby harmonizing global exploration with local refinement. Crucially, this formulation provides the learned optimizer with provable convergence guarantees. Extensive experiments demonstrate the scalability of L2E in high-dimensional spaces and its robust zero-shot generalization across synthetic and real-world control tasks. These results confirm that the framework learns a generic optimization manifold that extends beyond specific training distributions.
Learning Where, What and How to Transfer: A Multi-Role Reinforcement Learning Approach for Evolutionary Multitasking
Nov 19, 2025Evolutionary multitasking (EMT) algorithms typically require tailored designs for knowledge transfer, in order to assure convergence and optimality in multitask optimization. In this paper, we explore designing a systematic and generalizable knowledge transfer policy through Reinforcement Learning. We first identify three major challenges: determining the task to transfer (where), the knowledge to be transferred (what) and the mechanism for the transfer (how). To address these challenges, we formulate a multi-role RL system where three (groups of) policy networks act as specialized agents: a task routing agent incorporates an attention-based similarity recognition module to determine source-target transfer pairs via attention scores; a knowledge control agent determines the proportion of elite solutions to transfer; and a group of strategy adaptation agents control transfer strength by dynamically controlling hyper-parameters in the underlying EMT framework. Through pre-training all network modules end-to-end over an augmented multitask problem distribution, a generalizable meta-policy is obtained. Comprehensive validation experiments show state-of-the-art performance of our method against representative baselines. Further in-depth analysis not only reveals the rationale behind our proposal but also provide insightful interpretations on what the system have learned.
HEAR: An EEG Foundation Model with Heterogeneous Electrode Adaptive Representation
Oct 14, 2025Electroencephalography (EEG) is an essential technique for neuroscience research and brain-computer interface (BCI) applications. Recently, large-scale EEG foundation models have been developed, exhibiting robust generalization capabilities across diverse tasks and subjects. However, the heterogeneity of EEG devices not only hinders the widespread adoption of these models but also poses significant challenges to their further scaling and development. In this paper, we introduce HEAR, the first EEG foundation model explicitly designed to support heterogeneous EEG devices, accommodating varying electrode layouts and electrode counts. HEAR employs a learnable, coordinate-based spatial embedding to map electrodes with diverse layouts and varying counts into a unified representational space. This unified spatial representation is then processed by a novel spatially-guided transformer, which effectively captures spatiotemporal dependencies across electrodes. To support the development of HEAR, we construct a large-scale EEG dataset comprising 8,782 hours of data collected from over 150 distinct electrode layouts with up to 1,132 electrodes. Experimental results demonstrate that HEAR substantially outperforms existing EEG foundation models in supporting heterogeneous EEG devices and generalizing across diverse cognitive tasks and subjects.
A Systematic Survey on Large Language Models for Evolutionary Optimization: From Modeling to Solving
Sep 10, 2025


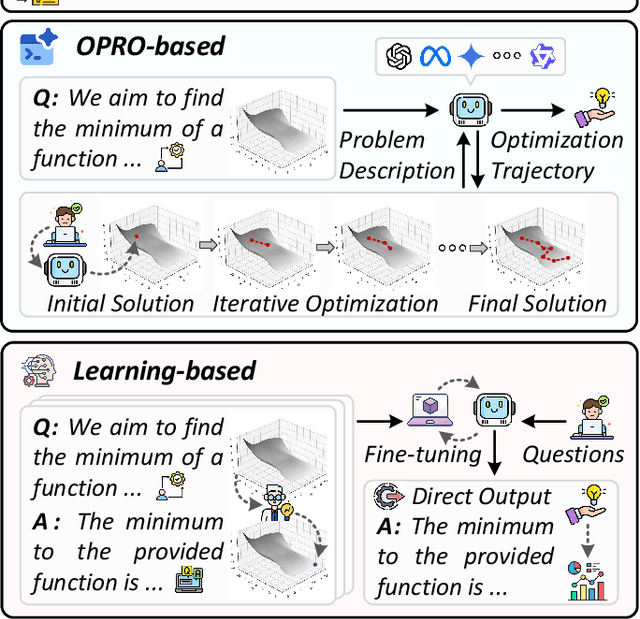
Large Language Models (LLMs), with their strong understanding and reasoning capabilities, are increasingly being explored for tackling optimization problems, especially in synergy with evolutionary computation. Despite rapid progress, however, the field still lacks a unified synthesis and a systematic taxonomy. This survey addresses this gap by providing a comprehensive review of recent developments and organizing them within a structured framework. We classify existing research into two main stages: LLMs for optimization modeling and LLMs for optimization solving. The latter is further divided into three paradigms according to the role of LLMs in the optimization workflow: LLMs as stand-alone optimizers, low-level LLMs embedded within optimization algorithms, and high-level LLMs for algorithm selection and generation. For each category, we analyze representative methods, distill technical challenges, and examine their interplay with traditional approaches. We also review interdisciplinary applications spanning the natural sciences, engineering, and machine learning. By contrasting LLM-driven and conventional methods, we highlight key limitations and research gaps, and point toward future directions for developing self-evolving agentic ecosystems for optimization. An up-to-date collection of related literature is maintained at https://github.com/ishmael233/LLM4OPT.
Fading the Digital Ink: A Universal Black-Box Attack Framework for 3DGS Watermarking Systems
Aug 10, 2025With the rise of 3D Gaussian Splatting (3DGS), a variety of digital watermarking techniques, embedding either 1D bitstreams or 2D images, are used for copyright protection. However, the robustness of these watermarking techniques against potential attacks remains underexplored. This paper introduces the first universal black-box attack framework, the Group-based Multi-objective Evolutionary Attack (GMEA), designed to challenge these watermarking systems. We formulate the attack as a large-scale multi-objective optimization problem, balancing watermark removal with visual quality. In a black-box setting, we introduce an indirect objective function that blinds the watermark detector by minimizing the standard deviation of features extracted by a convolutional network, thus rendering the feature maps uninformative. To manage the vast search space of 3DGS models, we employ a group-based optimization strategy to partition the model into multiple, independent sub-optimization problems. Experiments demonstrate that our framework effectively removes both 1D and 2D watermarks from mainstream 3DGS watermarking methods while maintaining high visual fidelity. This work reveals critical vulnerabilities in existing 3DGS copyright protection schemes and calls for the development of more robust watermarking systems.
Diversity-Aware Policy Optimization for Large Language Model Reasoning
May 29, 2025The reasoning capabilities of large language models (LLMs) have advanced rapidly, particularly following the release of DeepSeek R1, which has inspired a surge of research into data quality and reinforcement learning (RL) algorithms. Despite the pivotal role diversity plays in RL, its influence on LLM reasoning remains largely underexplored. To bridge this gap, this work presents a systematic investigation into the impact of diversity in RL-based training for LLM reasoning, and proposes a novel diversity-aware policy optimization method. Across evaluations on 12 LLMs, we observe a strong positive correlation between the solution diversity and Potential at k (a novel metric quantifying an LLM's reasoning potential) in high-performing models. This finding motivates our method to explicitly promote diversity during RL training. Specifically, we design a token-level diversity and reformulate it into a practical objective, then we selectively apply it to positive samples. Integrated into the R1-zero training framework, our method achieves a 3.5 percent average improvement across four mathematical reasoning benchmarks, while generating more diverse and robust solutions.
Neuromorphic Sequential Arena: A Benchmark for Neuromorphic Temporal Processing
May 28, 2025Temporal processing is vital for extracting meaningful information from time-varying signals. Recent advancements in Spiking Neural Networks (SNNs) have shown immense promise in efficiently processing these signals. However, progress in this field has been impeded by the lack of effective and standardized benchmarks, which complicates the consistent measurement of technological advancements and limits the practical applicability of SNNs. To bridge this gap, we introduce the Neuromorphic Sequential Arena (NSA), a comprehensive benchmark that offers an effective, versatile, and application-oriented evaluation framework for neuromorphic temporal processing. The NSA includes seven real-world temporal processing tasks from a diverse range of application scenarios, each capturing rich temporal dynamics across multiple timescales. Utilizing NSA, we conduct extensive comparisons of recently introduced spiking neuron models and neural architectures, presenting comprehensive baselines in terms of task performance, training speed, memory usage, and energy efficiency. Our findings emphasize an urgent need for efficient SNN designs that can consistently deliver high performance across tasks with varying temporal complexities while maintaining low computational costs. NSA enables systematic tracking of advancements in neuromorphic algorithm research and paves the way for developing effective and efficient neuromorphic temporal processing systems.
A New Scope and Domain Measure Comparison Method for Global Convergence Analysis in Evolutionary Computation
May 07, 2025Convergence analysis is a fundamental research topic in evolutionary computation (EC). The commonly used analysis method models the EC algorithm as a homogeneous Markov chain for analysis, which is not always suitable for different EC variants, and also sometimes causes misuse and confusion due to their complex process. In this article, we categorize the existing researches on convergence analysis in EC algorithms into stable convergence and global convergence, and then prove that the conditions for these two convergence properties are somehow mutually exclusive. Inspired by this proof, we propose a new scope and domain measure comparison (SDMC) method for analyzing the global convergence of EC algorithms and provide a rigorous proof of its necessity and sufficiency as an alternative condition. Unlike traditional methods, the SDMC method is straightforward, bypasses Markov chain modeling, and minimizes errors from misapplication as it only focuses on the measure of the algorithm's search scope. We apply SDMC to two algorithm types that are unsuitable for traditional methods, confirming its effectiveness in global convergence analysis. Furthermore, we apply the SDMC method to explore the gene targeting mechanism's impact on the global convergence in large-scale global optimization, deriving insights into how to design EC algorithms that guarantee global convergence and exploring how theoretical analysis can guide EC algorithm design.
QM-ToT: A Medical Tree of Thoughts Reasoning Framework for Quantized Model
Apr 13, 2025Large language models (LLMs) face significant challenges in specialized biomedical tasks due to the inherent complexity of medical reasoning and the sensitive nature of clinical data. Existing LLMs often struggle with intricate medical terminology and the need for accurate clinical insights, leading to performance reduction when quantized for resource-constrained deployment. To address these issues, we propose Quantized Medical Tree of Thought (QM-ToT), a path-based reasoning framework. QM-ToT leverages a Tree of Thought (ToT) reasoning approach to decompose complex medical problems into manageable subtasks, coupled with evaluator assessment layers. This framework facilitates substantial performance improvements in INT4-quantized models on the challenging MedQAUSMLE dataset. Specifically, we demonstrate a remarkable accuracy increase from 34% to 50% for the LLaMA2-70b model and from 58.77% to 69.49% for LLaMA-3.1-8b. Besides, we also proposed an effect data distillation method based on ToT. Compared to the traditional distillation method, we achieved an improvement of 86. 27% while using only 3.9% of the data.This work, for the first time, showcases the potential of ToT to significantly enhance performance on complex biomedical tasks, establishing a crucial foundation for future advances in deploying high-performing quantized LLM in resource-limited medical settings.