 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASH: Cooperative-Heterogeneous Multi-Agent Reinforcement Learning for Single Humanoid Robot Locomotion
Aug 14, 2025This paper proposes a novel method to enhance locomotion for a single humanoid robot through cooperative-heterogeneous multi-agent deep reinforcement learning (MARL). While most existing methods typically employ single-agent reinforcement learning algorithms for a single humanoid robot or MARL algorithms for multi-robot system tasks, we propose a distinct paradigm: applying cooperative-heterogeneous MARL to optimize locomotion for a single humanoid robot. The proposed method, multi-agent reinforcement learning for single humanoid locomotion (MASH), treats each limb (legs and arms) as an independent agent that explores the robot's action space while sharing a global critic for cooperative learning. Experiments demonstrate that MASH accelerates training convergence and improves whole-body cooperation ability, outperforming conventional single-agent reinforcement learning methods. This work advances the integration of MARL into single-humanoid-robot control, offering new insights into efficient locomotion strategies.
MBL-CPDP: A Multi-objective Bilevel Method for Cross-Project Defect Prediction via Automated Machine Learning
Nov 10, 2024



Cross-project defect prediction (CPDP) leverages machine learning (ML) techniques to proactively identify software defects, especially where project-specific data is scarce. However, developing a robust ML pipeline with optimal hyperparameters that effectively use cross-project information and yield satisfactory performance remains challenging. In this paper, we resolve this bottleneck by formulating CPDP as a multi-objective bilevel optimization (MBLO) method, dubbed MBL-CPDP. It comprises two nested problems: the upper-level, a multi-objective combinatorial optimization problem, enhances robustness and efficiency in optimizing ML pipelines, while the lower-level problem is an expensive optimization problem that focuses on tuning their optimal hyperparameters. Due to the high-dimensional search space characterized by feature redundancy and inconsistent data distributions, the upper-level problem combines feature selection, transfer learning, and classification to leverage limited and heterogeneous historical data. Meanwhile, an ensemble learning method is proposed to capture differences in cross-project distribution and generalize across diverse datasets. Finally, a MBLO algorithm is presented to solve this problem while achieving high adaptability effectively. To evaluate the performance of MBL-CPDP, we compare it with five automated ML tools and $50$ CPDP techniques across $20$ projects. Extensive empirical results show that MBL-CPDPoutperforms the comparison methods, demonstrating its superior adaptability and comprehensive performance evaluation capability.
Hierarchical learning control for autonomous robots inspired by central nervous system
Aug 07, 2024Mammals can generate autonomous behaviors in various complex environments through the coordination and interaction of activities at different levels of their central nervous system. In this paper, we propose a novel hierarchical learning control framework by mimicking the hierarchical structure of the central nervous system along with their coordination and interaction behaviors. The framework combines the active and passive control systems to improve both the flexibility and reliability of the control system as well as to achieve more diverse autonomous behaviors of robots. Specifically, the framework has a backbone of independent neural network controllers at different levels and takes a three-level dual descending pathway structure, inspired from the functionality of the cerebral cortex, cerebellum, and spinal cord. We comprehensively validated the proposed approach through the simulation as well as the experiment of a hexapod robot in various complex environments, including obstacle crossing and rapid recovery after partial damage. This study reveals the principle that governs the autonomous behavior in the central nervous system and demonstrates the effectiveness of the hierarchical control approach with the salient features of the hierarchical learning control architecture and combination of active and passive control systems.
A Neuro-Inspired Hierarchical Reinforcement Learning for Motor Control
Nov 14, 2023



Designing controllers to achieve natural motion capabilities for multi-joint robots is a significant challenge. However, animals in nature are naturally with basic motor abilities and can master various complex motor skills through acquired learning. On the basis of analyzing the mechanism of the central motor system in mammals, we propose a neuro-inspired hierarchical reinforcement learning algorithm that enables robots to learn rich motor skills and apply them to complex task environments without relying on external data. We first design a skills network similar to the cerebellum by utilizing the selection mechanism of voluntary movements in the basal ganglia and the regulatory ability of the cerebellum to regulate movement. Subsequently, by imitating the structure of advanced centers in the motion system, we propose a high-level policy to generate different skill combinations, thereby enabling the robot to acquire natural motor abilities. We conduct experiments on 4 types of robots and 22 task environments, and the results show that the proposed method can enable different types of robots to achieve flexible motion skills. Overall, our research provides a promising framework for the design of robotic neural motor controllers.
Solving Expensive Optimization Problems in Dynamic Environments with Meta-learning
Oct 19, 2023Dynamic environments pose great challenges for expensive optimization problems, as the objective functions of these problems change over time and thus require remarkable computational resources to track the optimal solutions. Although data-driven evolutionary optimization and Bayesian optimization (BO) approaches have shown promise in solving expensive optimization problems in static environments, the attempts to develop such approaches in dynamic environments remain rarely unexplored. In this paper, we propose a simple yet effective meta-learning-based optimization framework for solving expensive dynamic optimization problems. This framework is flexible, allowing any off-the-shelf continuously differentiable surrogate model to be used in a plug-in manner, either in data-driven evolutionary optimization or BO approaches. In particular, the framework consists of two unique components: 1) the meta-learning component, in which a gradient-based meta-learning approach is adopted to learn experience (effective model parameters) across different dynamics along the optimization process. 2) the adaptation component, where the learned experience (model parameters) is used as the initial parameters for fast adaptation in the dynamic environment based on few shot samples. By doing so, the optimization process is able to quickly initiate the search in a new environment within a strictly restricted computational budget. Experiments demonstrate the effectiveness of the proposed algorithm framework compared to several state-of-the-art algorithms on common benchmark test problems under different dynamic characteristics.
Addressing Domain Shift via Knowledge Space Sharing for Generalized Zero-Shot Industrial Fault Diagnosis
Jun 04, 2023Fault diagnosis is a critical aspect of industrial safety, and supervised industrial fault diagnosis has been extensively researched. However, obtaining fault samples of all categories for model training can be challenging due to cost and safety concerns. As a result, the generalized zero-shot industrial fault diagnosis has gained attention as it aims to diagnose both seen and unseen faults. Nevertheless, the lack of unseen fault data for training poses a challenging domain shift problem (DSP), where unseen faults are often identified as seen faults. In this article, we propose a knowledge space sharing (KSS) model to address the DSP in the generalized zero-shot industrial fault diagnosis task. The KSS model includes a generation mechanism (KSS-G) and a discrimination mechanism (KSS-D). KSS-G generates samples for rare faults by recombining transferable attribute features extracted from seen samples under the guidance of auxiliary knowledge. KSS-D is trained in a supervised way with the help of generated samples, which aims to address the DSP by modeling seen categories in the knowledge space. KSS-D avoids misclassifying rare faults as seen faults and identifies seen fault samples. We conduct generalized zero-shot diagnosis experiments on the benchmark Tennessee-Eastman process, and our results show that our approach outperforms state-of-the-art methods for the generalized zero-shot industrial fault diagnosis problem.
Incremental Data-driven Optimization of Complex Systems in Nonstationary Environments
Dec 25, 2020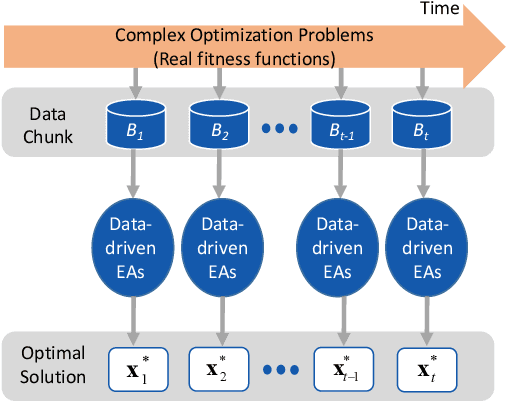
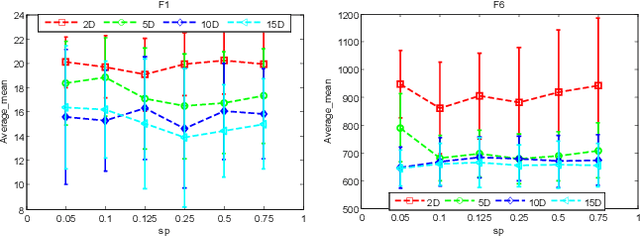
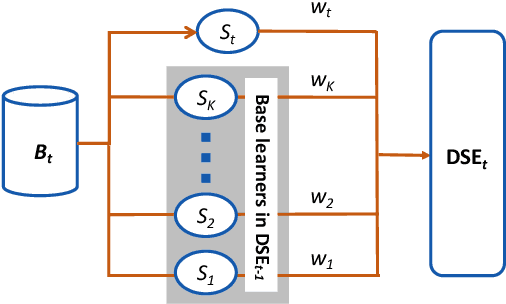
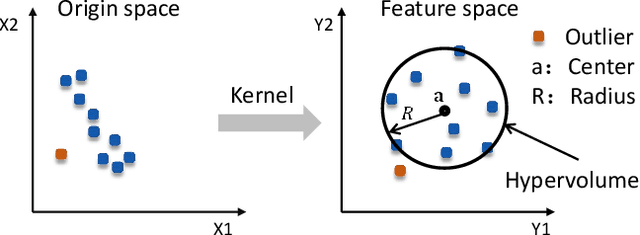
Existing work on data-driven optimization focuses on problems in static environments, but little attention has been paid to problems in dynamic environments. This paper proposes a data-driven optimization algorithm to deal with the challenges presented by the dynamic environments. First, a data stream ensemble learning method is adopted to train the surrogates so that each base learner of the ensemble learns the time-varying objective function in the previous environments. After that, a multi-task evolutionary algorithm is employed to simultaneously optimize the problems in the past environments assisted by the ensemble surrogate. This way, the optimization tasks in the previous environments can be used to accelerate the tracking of the optimum in the current environment. Since the real fitness function is not available for verifying the surrogates in offline data-driven optimization, a support vector domain description that was designed for outlier detection is introduced to select a reliable solution. Empirical results on six dynamic optimization benchmark problems demonstrate the effectiveness of the proposed algorithm compared with four state-of-the-art data-driven optimization algorithms.