 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2S-FDD: Bridging Industrial Time Series and Natural Language for Explainable Zero-shot Fault Diagnosis
Mar 09, 2026Fault diagnosis is critical for the safe operation of industrial systems. Conventional diagnosis models typically produce abstract outputs such as anomaly scores or fault categories, failing to answer critical operational questions like "Why" or "How to repair". While large language models (LLMs) offer strong generalization and reasoning abilities, their training on discrete textual corpora creates a semantic gap when processing high-dimensional, temporal industrial signals. To address this challenge, we propose a Signals-to-Semantics fault diagnosis (S2S-FDD) framework that bridges high-dimensional sensor signals with natural language semantics through two key innovations: We first design a Signal-to-Semantic operator to convert abstract time-series signals into natural language summaries, capturing trends, periodicity, and deviations. Based on the descriptions, we design a multi-turn tree-structured diagnosis method to perform fault diagnosis by referencing historical maintenance documents and dynamically querying additional signals. The framework further supports human-in-the-loop feedback for continuous refinement. Experiments on the multiphase flow process show the feasibility and effectiveness of the proposed method for explainable zero-shot fault diagnosis.
A Bi-directional Adaptive Framework for Agile UAV Landing
Jan 06, 2026Autonomous landing on mobile platforms is crucial for extending quadcopter operational flexibility, yet conventional methods are often too inefficient for highly dynamic scenarios. The core limitation lies in the prevalent ``track-then-descend'' paradigm, which treats the platform as a passive target and forces the quadcopter to perform complex, sequential maneuvers. This paper challenges that paradigm by introducing a bi-directional cooperative landing framework that redefines the roles of the vehicle and the platform. The essential innovation is transforming the problem from a single-agent tracking challenge into a coupled system optimization. Our key insight is that the mobile platform is not merely a target, but an active agent in the landing process. It proactively tilts its surface to create an optimal, stable terminal attitude for the approaching quadcopter. This active cooperation fundamentally breaks the sequential model by parallelizing the alignment and descent phases. Concurrently, the quadcopter's planning pipeline focuses on generating a time-optimal and dynamically feasible trajectory that minimizes energy consumption. This bi-directional coordination allows the system to execute the recovery in an agile manner, characterized by aggressive trajectory tracking and rapid state synchronization within transient windows. The framework's effectiveness, validated in dynamic scenarios, significantly improves the efficiency, precision, and robustness of autonomous quadrotor recovery in complex and time-constrained missions.
TimeSeries2Report prompting enables adaptive large language model management of lithium-ion batteries
Dec 18, 2025

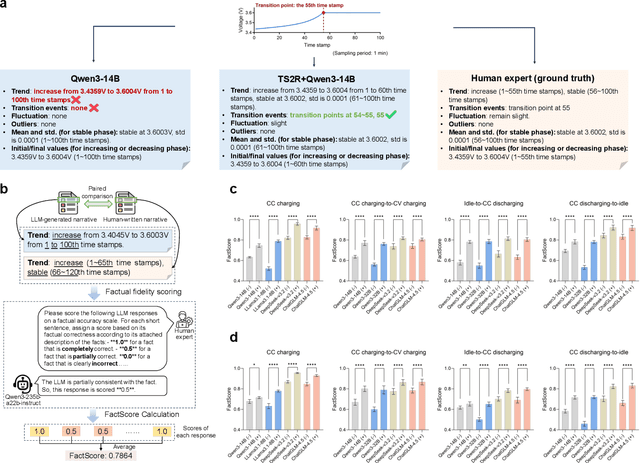

Large language models (LLMs) offer promising capabilities for interpreting multivariate time-series data, yet their application to real-world battery energy storage system (BESS) operation and maintenance remains largely unexplored. Here, we present TimeSeries2Report (TS2R), a prompting framework that converts raw lithium-ion battery operational time-series into structured, semantically enriched reports, enabling LLMs to reason, predict, and make decisions in BESS management scenarios. TS2R encodes short-term temporal dynamics into natural language through a combination of segmentation, semantic abstraction, and rule-based interpretation, effectively bridging low-level sensor signals with high-level contextual insights. We benchmark TS2R across both lab-scale and real-world datasets, evaluating report quality and downstream task performance in anomaly detection, state-of-charge prediction, and charging/discharging management. Compared with vision-, embedding-, and text-based prompting baselines, report-based prompting via TS2R consistently improves LLM performance in terms of across accuracy, robustness, and explainability metrics. Notably, TS2R-integrated LLMs achieve expert-level decision quality and predictive consistency without retraining or architecture modification, establishing a practical path for adaptive, LLM-driven battery intelligence.
Pragmatist: Multiview Conditional Diffusion Models for High-Fidelity 3D Reconstruction from Unposed Sparse Views
Dec 12, 2024Inferring 3D structures from sparse, unposed observations is challenging due to its unconstrained nature. Recent methods propose to predict implicit representations directly from unposed inputs in a data-driven manner, achieving promising results. However, these methods do not utilize geometric priors and cannot hallucinate the appearance of unseen regions, thus making it challenging to reconstruct fine geometric and textural details. To tackle this challenge, our key idea is to reformulate this ill-posed problem as conditional novel view synthesis, aiming to generate complete observations from limited input views to facilitate reconstruction. With complete observations, the poses of the input views can be easily recovered and further used to optimize the reconstructed object. To this end, we propose a novel pipeline Pragmatist. First, we generate a complete observation of the object via a multiview conditional diffusion model. Then, we use a feed-forward large reconstruction model to obtain the reconstructed mesh. To further improve the reconstruction quality, we recover the poses of input views by inverting the obtained 3D representations and further optimize the texture using detailed input views. Unlike previous approaches, our pipeline improves reconstruction by efficiently leveraging unposed inputs and generative priors, circumventing the direct resolution of highly ill-posed problems. Extensive experiments show that our approach achieves promising performance in several benchmarks.
Monocular Obstacle Avoidance Based on Inverse PPO for Fixed-wing UAVs
Nov 27, 2024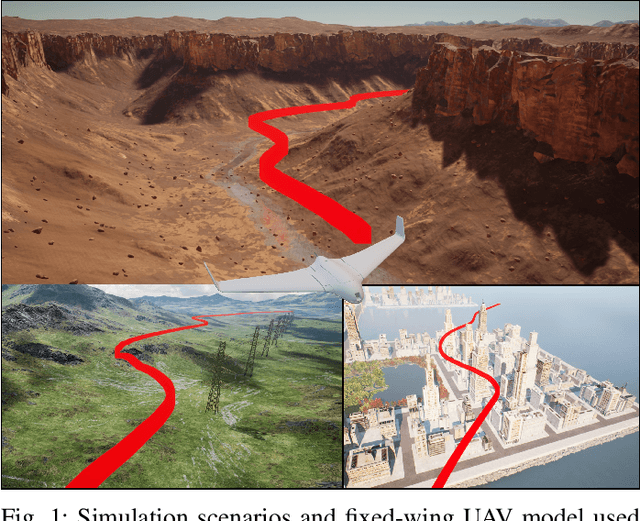
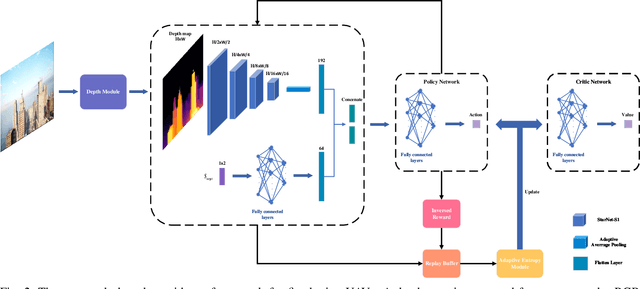
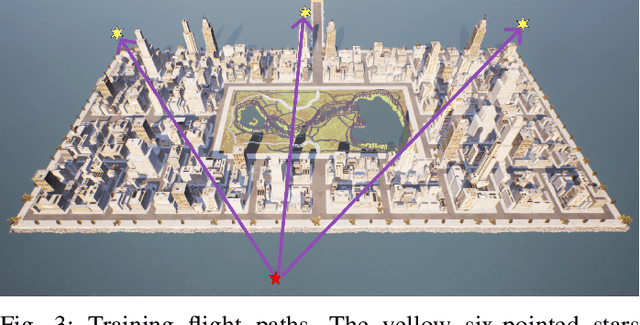
Fixed-wing Unmanned Aerial Vehicles (UAVs) are one of the most commonly used platforms for the burgeoning Low-altitude Economy (LAE) and Urban Air Mobility (UAM), due to their long endurance and high-speed capabilities. Classical obstacle avoidance systems, which rely on prior maps or sophisticated sensors, face limitations in unknown low-altitude environments and small UAV platforms. In response, this paper proposes a lightweight deep reinforcement learning (DRL) based UAV collision avoidance system that enables a fixed-wing UAV to avoid unknown obstacles at cruise speed over 30m/s, with only onboard visual sensors. The proposed system employs a single-frame image depth inference module with a streamlined network architecture to ensure real-time obstacle detection, optimized for edge computing devices. After that, a reinforcement learning controller with a novel reward function is designed to balance the target approach and flight trajectory smoothness, satisfying the specific dynamic constraints and stability requirements of a fixed-wing UAV platform. An adaptive entropy adjustment mechanism is introduced to mitigate the exploration-exploitation trade-off inherent in DRL, improving training convergence and obstacle avoidance success rates. Extensive software-in-the-loop and hardware-in-the-loop experiments demonstrate that the proposed framework outperforms other methods in obstacle avoidance efficiency and flight trajectory smoothness and confirm the feasibility of implementing the algorithm on edge devices. The source code is publicly available at \url{https://github.com/ch9397/FixedWing-MonoPPO}.
Less but Better: Enabling Generalized Zero-shot Learning Towards Unseen Domains by Intrinsic Learning from Redundant LLM Semantics
Mar 21, 2024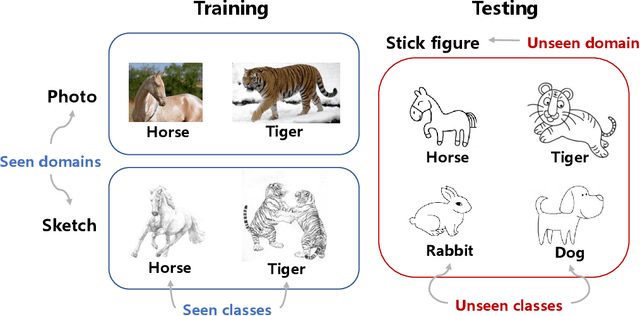
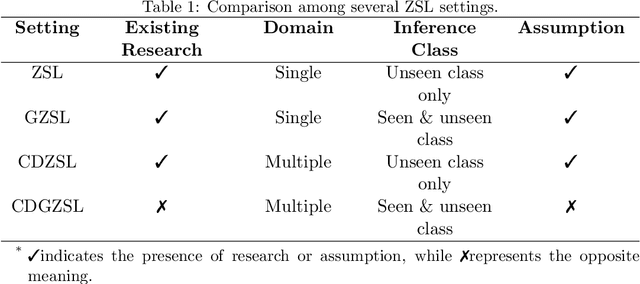
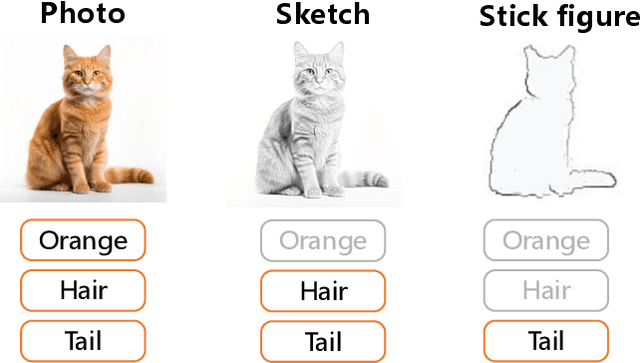
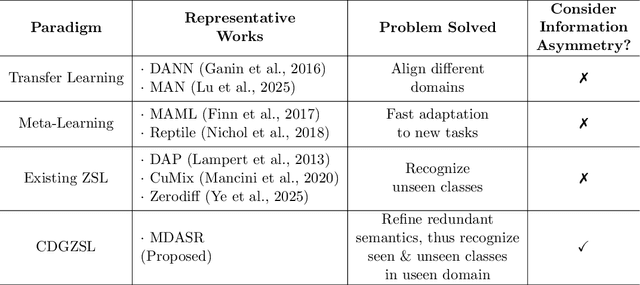
Generalized zero-shot learning (GZSL) focuses on recognizing seen and unseen classes against domain shift problem (DSP) where data of unseen classes may be misclassified as seen classes. However, existing GZSL is still limited to seen domains. In the current work, we pioneer cross-domain GZSL (CDGZSL) which addresses GZSL towards unseen domains. Different from existing GZSL methods which alleviate DSP by generating features of unseen classes with semantics, CDGZSL needs to construct a common feature space across domains and acquire the corresponding intrinsic semantics shared among domains to transfer from seen to unseen domains. Considering the information asymmetry problem caused by redundant class semantics annotated with large language models (LLMs), we present Meta Domain Alignment Semantic Refinement (MDASR). Technically, MDASR consists of two parts: Inter-class Similarity Alignment (ISA), which eliminates the non-intrinsic semantics not shared across all domains under the guidance of inter-class feature relationships, and Unseen-class Meta Generation (UMG), which preserves intrinsic semantics to maintain connectivity between seen and unseen classes by simulating feature generation. MDASR effectively aligns the redundant semantic space with the common feature space, mitigating the information asymmetry in CDGZSL. The effectiveness of MDASR is demonstrated on the Office-Home and Mini-DomainNet, and we have shared the LLM-based semantics for these datasets as the benchmark.
Learning to better see the unseen: Broad-Deep Mixed Anti-Forgetting Framework for Incremental Zero-Shot Fault Diagnosis
Mar 18, 2024Zero-shot fault diagnosis (ZSFD) is capable of identifying unseen faults via predicting fault attributes labeled by human experts. We first recognize the demand of ZSFD to deal with continuous changes in industrial processes, i.e., the model's ability to adapt to new fault categories and attributes while avoiding forgetting the diagnosis ability learned previously. To overcome the issue that the existing ZSFD paradigm cannot learn from evolving streams of training data in industrial scenarios, the incremental ZSFD (IZSFD) paradigm is proposed for the first time, which incorporates category increment and attribute increment for both traditional ZSFD and generalized ZSFD paradigms. To achieve IZSFD, we present a broad-deep mixed anti-forgetting framework (BDMAFF) that aims to learn from new fault categories and attributes. To tackle the issue of forgetting, BDMAFF effectively accumulates previously acquired knowledge from two perspectives: features and attribute prototypes. The feature memory is established through a deep generative model that employs anti-forgetting training strategies, ensuring the generation quality of historical categories is supervised and maintained. The diagnosis model SEEs the UNSEEN faults with the help of generated samples from the generative model. The attribute prototype memory is established through a diagnosis model inspired by the broad learning system. Unlike traditional incremental learning algorithms, BDMAFF introduces a memory-driven iterative update strategy for the diagnosis model, which allows the model to learn new faults and attributes without requiring the storage of all historical training samples. The effectiveness of the proposed method is verified by a real hydraulic system and the Tennessee-Eastman benchmark process.
Light-LOAM: A Lightweight LiDAR Odometry and Mapping based on Graph-Matching
Oct 06, 2023
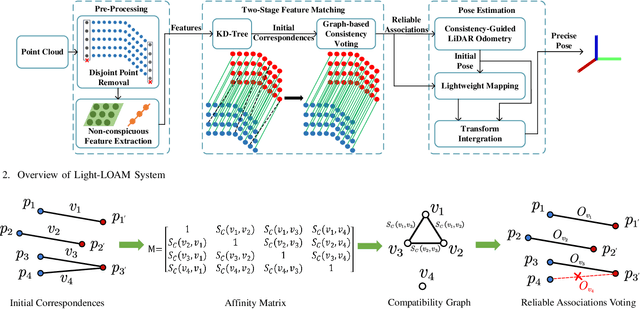
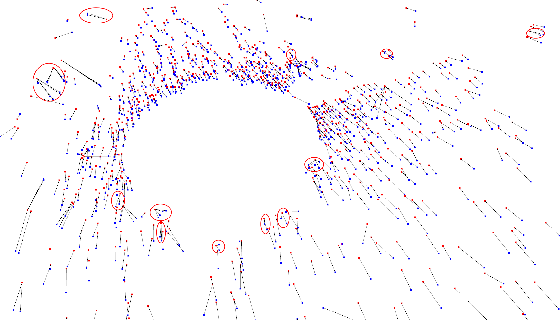
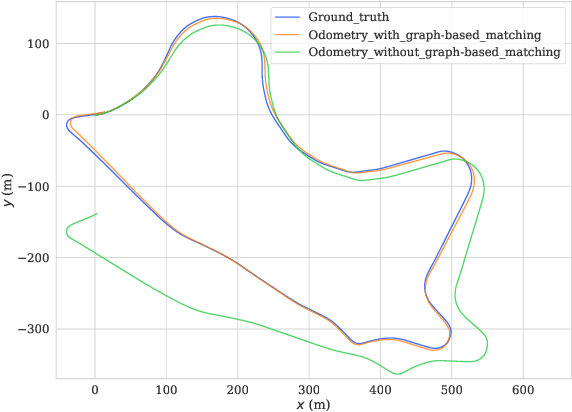
Simultaneous Localization and Mapping (SLAM) plays an important role in robot autonomy. Reliability and efficiency are the two most valued features for applying SLAM in robot applications. In this paper, we consider achieving a reliable LiDAR-based SLAM function in computation-limited platforms, such as quadrotor UAVs based on graph-based point cloud association. First, contrary to most works selecting salient features for point cloud registration, we propose a non-conspicuous feature selection strategy for reliability and robustness purposes. Then a two-stage correspondence selection method is used to register the point cloud, which includes a KD-tree-based coarse matching followed by a graph-based matching method that uses geometric consistency to vote out incorrect correspondences. Additionally, we propose an odometry approach where the weight optimizations are guided by vote results from the aforementioned geometric consistency graph. In this way, the optimization of LiDAR odometry rapidly converges and evaluates a fairly accurate transformation resulting in the back-end module efficiently finishing the mapping task. Finally, we evaluate our proposed framework on the KITTI odometry dataset and real-world environments. Experiments show that our SLAM system achieves a comparative level or higher level of accuracy with more balanced computation efficiency compared with the mainstream LiDAR-based SLAM solutions.
Cross-Video Contextual Knowledge Exploration and Exploitation for Ambiguity Reduction in Weakly Supervised Temporal Action Localization
Aug 24, 2023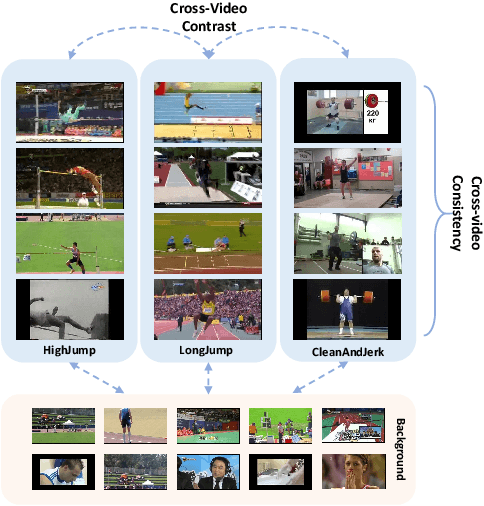
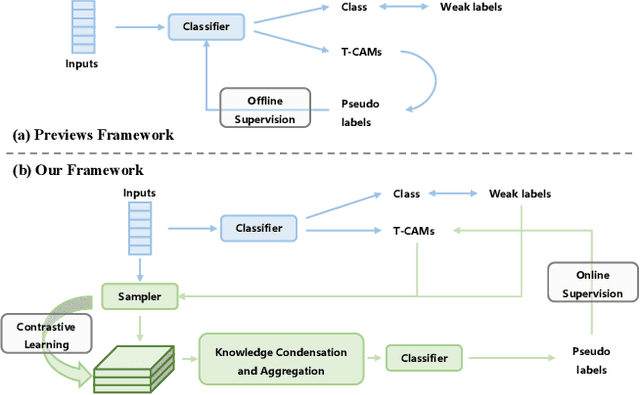
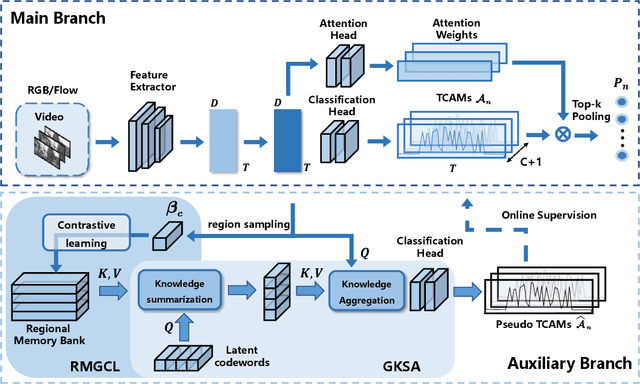
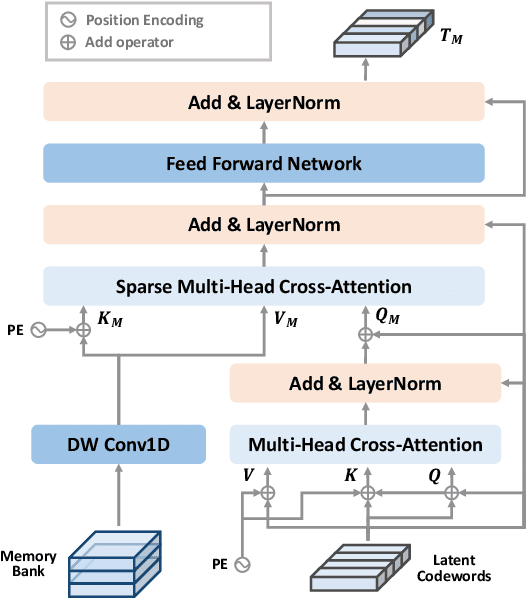
Weakly supervised temporal action localization (WSTAL) aims to localize actions in untrimmed videos using video-level labels. Despite recent advances, existing approaches mainly follow a localization-by-classification pipeline, generally processing each segment individually, thereby exploiting only limited contextual information. As a result, the model will lack a comprehensive understanding (e.g. appearance and temporal structure) of various action patterns, leading to ambiguity in classification learning and temporal localization. Our work addresses this from a novel perspective, by exploring and exploiting the cross-video contextual knowledge within the dataset to recover the dataset-level semantic structure of action instances via weak labels only, thereby indirectly improving the holistic understanding of fine-grained action patterns and alleviating the aforementioned ambiguities. Specifically, an end-to-end framework is proposed, including a Robust Memory-Guided Contrastive Learning (RMGCL) module and a Global Knowledge Summarization and Aggregation (GKSA) module. First, the RMGCL module explores the contrast and consistency of cross-video action features, assisting in learning more structured and compact embedding space, thus reducing ambiguity in classification learning. Further, the GKSA module is used to efficiently summarize and propagate the cross-video representative action knowledge in a learnable manner to promote holistic action patterns understanding, which in turn allows the generation of high-confidence pseudo-labels for self-learning, thus alleviating ambiguity in temporal localization. Extensive experiments on THUMOS14, ActivityNet1.3, and FineAction demonstrate that our method outperforms the state-of-the-art methods, and can be easily plugged into other WSTAL methods.
Addressing Domain Shift via Knowledge Space Sharing for Generalized Zero-Shot Industrial Fault Diagnosis
Jun 04, 2023Fault diagnosis is a critical aspect of industrial safety, and supervised industrial fault diagnosis has been extensively researched. However, obtaining fault samples of all categories for model training can be challenging due to cost and safety concerns. As a result, the generalized zero-shot industrial fault diagnosis has gained attention as it aims to diagnose both seen and unseen faults. Nevertheless, the lack of unseen fault data for training poses a challenging domain shift problem (DSP), where unseen faults are often identified as seen faults. In this article, we propose a knowledge space sharing (KSS) model to address the DSP in the generalized zero-shot industrial fault diagnosis task. The KSS model includes a generation mechanism (KSS-G) and a discrimination mechanism (KSS-D). KSS-G generates samples for rare faults by recombining transferable attribute features extracted from seen samples under the guidance of auxiliary knowledge. KSS-D is trained in a supervised way with the help of generated samples, which aims to address the DSP by modeling seen categories in the knowledge space. KSS-D avoids misclassifying rare faults as seen faults and identifies seen fault samples. We conduct generalized zero-shot diagnosis experiments on the benchmark Tennessee-Eastman process, and our results show that our approach outperforms state-of-the-art methods for the generalized zero-shot industrial fault diagnosis problem.