 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAstrolabe: Steering Forward-Process Reinforcement Learning for Distilled Autoregressive Video Models
Mar 17, 2026Distilled autoregressive (AR) video models enable efficient streaming generation but frequently misalign with human visual preferences. Existing reinforcement learning (RL) frameworks are not naturally suited to these architectures, typically requiring either expensive re-distillation or solver-coupled reverse-process optimization that introduces considerable memory and computational overhead. We present Astrolabe, an efficient online RL framework tailored for distilled AR models. To overcome existing bottlenecks, we introduce a forward-process RL formulation based on negative-aware fine-tuning. By contrasting positive and negative samples directly at inference endpoints, this approach establishes an implicit policy improvement direction without requiring reverse-process unrolling. To scale this alignment to long videos, we propose a streaming training scheme that generates sequences progressively via a rolling KV-cache, applying RL updates exclusively to local clip windows while conditioning on prior context to ensure long-range coherence. Finally, to mitigate reward hacking, we integrate a multi-reward objective stabilized by uncertainty-aware selective regularization and dynamic reference updates. Extensive experiments demonstrate that our method consistently enhances generation quality across multiple distilled AR video models, serving as a robust and scalable alignment solution.
ShotVerse: Advancing Cinematic Camera Control for Text-Driven Multi-Shot Video Creation
Mar 12, 2026Text-driven video generation has democratized film creation, but camera control in cinematic multi-shot scenarios remains a significant block. Implicit textual prompts lack precision, while explicit trajectory conditioning imposes prohibitive manual overhead and often triggers execution failures in current models. To overcome this bottleneck, we propose a data-centric paradigm shift, positing that aligned (Caption, Trajectory, Video) triplets form an inherent joint distribution that can connect automated plotting and precise execution. Guided by this insight, we present ShotVerse, a "Plan-then-Control" framework that decouples generation into two collaborative agents: a VLM (Vision-Language Model)-based Planner that leverages spatial priors to obtain cinematic, globally aligned trajectories from text, and a Controller that renders these trajectories into multi-shot video content via a camera adapter. Central to our approach is the construction of a data foundation: we design an automated multi-shot camera calibration pipeline aligns disjoint single-shot trajectories into a unified global coordinate system. This facilitates the curation of ShotVerse-Bench, a high-fidelity cinematic dataset with a three-track evaluation protocol that serves as the bedrock for our framework. Extensive experiments demonstrate that ShotVerse effectively bridges the gap between unreliable textual control and labor-intensive manual plotting, achieving superior cinematic aesthetics and generating multi-shot videos that are both camera-accurate and cross-shot consistent.
Composing Concepts from Images and Videos via Concept-prompt Binding
Dec 10, 2025Visual concept composition, which aims to integrate different elements from images and videos into a single, coherent visual output, still falls short in accurately extracting complex concepts from visual inputs and flexibly combining concepts from both images and videos. We introduce Bind & Compose, a one-shot method that enables flexible visual concept composition by binding visual concepts with corresponding prompt tokens and composing the target prompt with bound tokens from various sources. It adopts a hierarchical binder structure for cross-attention conditioning in Diffusion Transformers to encode visual concepts into corresponding prompt tokens for accurate decomposition of complex visual concepts. To improve concept-token binding accuracy, we design a Diversify-and-Absorb Mechanism that uses an extra absorbent token to eliminate the impact of concept-irrelevant details when training with diversified prompts. To enhance the compatibility between image and video concepts, we present a Temporal Disentanglement Strategy that decouples the training process of video concepts into two stages with a dual-branch binder structure for temporal modeling. Evaluations demonstrate that our method achieves superior concept consistency, prompt fidelity, and motion quality over existing approaches, opening up new possibilities for visual creativity.
SpatialCrafter: Unleashing the Imagination of Video Diffusion Models for Scene Reconstruction from Limited Observations
May 17, 2025Novel view synthesis (NVS) boosts immersive experiences in computer vision and graphics. Existing techniques, though progressed, rely on dense multi-view observations, restricting their application. This work takes on the challenge of reconstructing photorealistic 3D scenes from sparse or single-view inputs. We introduce SpatialCrafter, a framework that leverages the rich knowledge in video diffusion models to generate plausible additional observations, thereby alleviating reconstruction ambiguity. Through a trainable camera encoder and an epipolar attention mechanism for explicit geometric constraints, we achieve precise camera control and 3D consistency, further reinforced by a unified scale estimation strategy to handle scale discrepancies across datasets. Furthermore, by integrating monocular depth priors with semantic features in the video latent space, our framework directly regresses 3D Gaussian primitives and efficiently processes long-sequence features using a hybrid network structure. Extensive experiments show our method enhances sparse view reconstruction and restores the realistic appearance of 3D scenes.
Pragmatist: Multiview Conditional Diffusion Models for High-Fidelity 3D Reconstruction from Unposed Sparse Views
Dec 12, 2024Inferring 3D structures from sparse, unposed observations is challenging due to its unconstrained nature. Recent methods propose to predict implicit representations directly from unposed inputs in a data-driven manner, achieving promising results. However, these methods do not utilize geometric priors and cannot hallucinate the appearance of unseen regions, thus making it challenging to reconstruct fine geometric and textural details. To tackle this challenge, our key idea is to reformulate this ill-posed problem as conditional novel view synthesis, aiming to generate complete observations from limited input views to facilitate reconstruction. With complete observations, the poses of the input views can be easily recovered and further used to optimize the reconstructed object. To this end, we propose a novel pipeline Pragmatist. First, we generate a complete observation of the object via a multiview conditional diffusion model. Then, we use a feed-forward large reconstruction model to obtain the reconstructed mesh. To further improve the reconstruction quality, we recover the poses of input views by inverting the obtained 3D representations and further optimize the texture using detailed input views. Unlike previous approaches, our pipeline improves reconstruction by efficiently leveraging unposed inputs and generative priors, circumventing the direct resolution of highly ill-posed problems. Extensive experiments show that our approach achieves promising performance in several benchmarks.
Cross-Video Contextual Knowledge Exploration and Exploitation for Ambiguity Reduction in Weakly Supervised Temporal Action Localization
Aug 24, 2023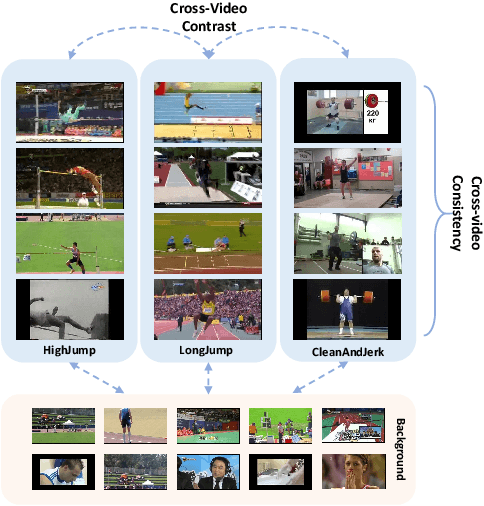
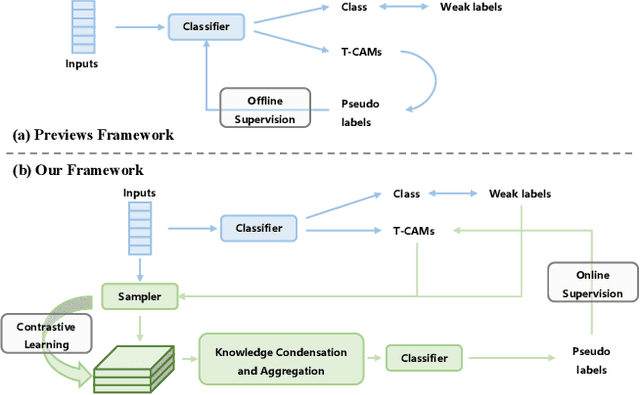
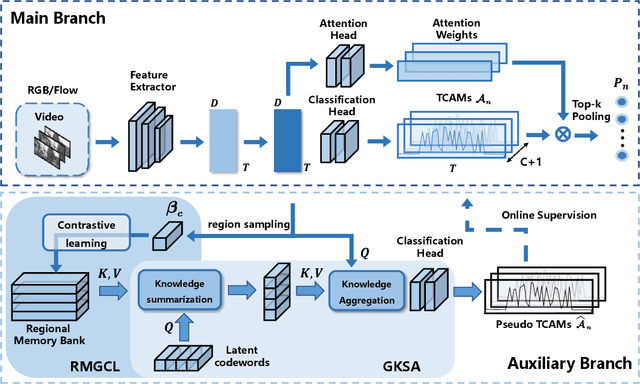
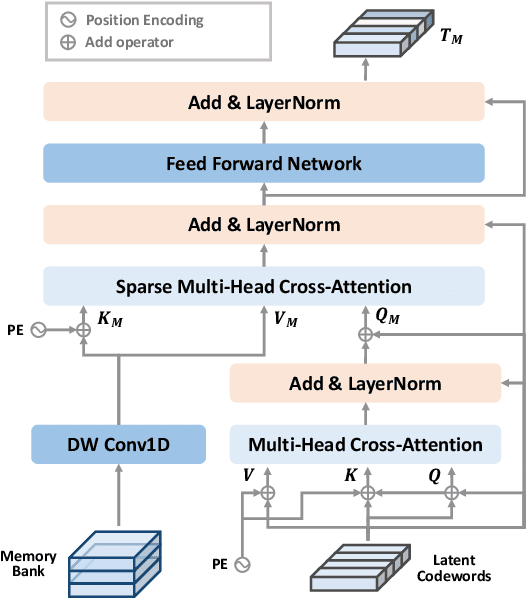
Weakly supervised temporal action localization (WSTAL) aims to localize actions in untrimmed videos using video-level labels. Despite recent advances, existing approaches mainly follow a localization-by-classification pipeline, generally processing each segment individually, thereby exploiting only limited contextual information. As a result, the model will lack a comprehensive understanding (e.g. appearance and temporal structure) of various action patterns, leading to ambiguity in classification learning and temporal localization. Our work addresses this from a novel perspective, by exploring and exploiting the cross-video contextual knowledge within the dataset to recover the dataset-level semantic structure of action instances via weak labels only, thereby indirectly improving the holistic understanding of fine-grained action patterns and alleviating the aforementioned ambiguities. Specifically, an end-to-end framework is proposed, including a Robust Memory-Guided Contrastive Learning (RMGCL) module and a Global Knowledge Summarization and Aggregation (GKSA) module. First, the RMGCL module explores the contrast and consistency of cross-video action features, assisting in learning more structured and compact embedding space, thus reducing ambiguity in classification learning. Further, the GKSA module is used to efficiently summarize and propagate the cross-video representative action knowledge in a learnable manner to promote holistic action patterns understanding, which in turn allows the generation of high-confidence pseudo-labels for self-learning, thus alleviating ambiguity in temporal localization. Extensive experiments on THUMOS14, ActivityNet1.3, and FineAction demonstrate that our method outperforms the state-of-the-art methods, and can be easily plugged into other WSTAL methods.
Dyna-DepthFormer: Multi-frame Transformer for Self-Supervised Depth Estimation in Dynamic Scenes
Jan 14, 2023Self-supervised methods have showed promising results on depth estimation task. However, previous methods estimate the target depth map and camera ego-motion simultaneously, underusing multi-frame correlation information and ignoring the motion of dynamic objects. In this paper, we propose a novel Dyna-Depthformer framework, which predicts scene depth and 3D motion field jointly and aggregates multi-frame information with transformer. Our contributions are two-fold. First, we leverage multi-view correlation through a series of self- and cross-attention layers in order to obtain enhanced depth feature representation. Specifically, we use the perspective transformation to acquire the initial reference point, and use deformable attention to reduce the computational cost. Second, we propose a warping-based Motion Network to estimate the motion field of dynamic objects without using semantic prior. To improve the motion field predictions, we propose an iterative optimization strategy, together with a sparsity-regularized loss. The entire pipeline achieves end-to-end self-supervised training by constructing a minimum reprojection loss. Extensive experiments on the KITTI and Cityscapes benchmarks demonstrate the effectiveness of our method and show that our method outperforms state-of-the-art algorithms.