 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRISM: Streaming Human Motion Generation with Per-Joint Latent Decomposition
Mar 10, 2026Text-to-motion generation has advanced rapidly, yet two challenges persist. First, existing motion autoencoders compress each frame into a single monolithic latent vector, entangling trajectory and per-joint rotations in an unstructured representation that downstream generators struggle to model faithfully. Second, text-to-motion, pose-conditioned generation, and long-horizon sequential synthesis typically require separate models or task-specific mechanisms, with autoregressive approaches suffering from severe error accumulation over extended rollouts. We present PRISM, addressing each challenge with a dedicated contribution. (1) A joint-factorized motion latent space: each body joint occupies its own token, forming a structured 2D grid (time joints) compressed by a causal VAE with forward-kinematics supervision. This simple change to the latent space -- without modifying the generator -- substantially improves generation quality, revealing that latent space design has been an underestimated bottleneck. (2) Noise-free condition injection: each latent token carries its own timestep embedding, allowing conditioning frames to be injected as clean tokens (timestep0) while the remaining tokens are denoised. This unifies text-to-motion and pose-conditioned generation in a single model, and directly enables autoregressive segment chaining for streaming synthesis. Self-forcing training further suppresses drift in long rollouts. With these two components, we train a single motion generation foundation model that seamlessly handles text-to-motion, pose-conditioned generation, autoregressive sequential generation, and narrative motion composition, achieving state-of-the-art on HumanML3D, MotionHub, BABEL, and a 50-scenario user study.
Dual-End Consistency Model
Feb 11, 2026The slow iterative sampling nature remains a major bottleneck for the practical deployment of diffusion and flow-based generative models. While consistency models (CMs) represent a state-of-the-art distillation-based approach for efficient generation, their large-scale application is still limited by two key issues: training instability and inflexible sampling. Existing methods seek to mitigate these problems through architectural adjustments or regularized objectives, yet overlook the critical reliance on trajectory selection. In this work, we first conduct an analysis on these two limitations: training instability originates from loss divergence induced by unstable self-supervised term, whereas sampling inflexibility arises from error accumulation. Based on these insights and analysis, we propose the Dual-End Consistency Model (DE-CM) that selects vital sub-trajectory clusters to achieve stable and effective training. DE-CM decomposes the PF-ODE trajectory and selects three critical sub-trajectories as optimization targets. Specifically, our approach leverages continuous-time CMs objectives to achieve few-step distillation and utilizes flow matching as a boundary regularizer to stabilize the training process. Furthermore, we propose a novel noise-to-noisy (N2N) mapping that can map noise to any point, thereby alleviating the error accumulation in the first step. Extensive experimental results show the effectiveness of our method: it achieves a state-of-the-art FID score of 1.70 in one-step generation on the ImageNet 256x256 dataset, outperforming existing CM-based one-step approaches.
PhysRVG: Physics-Aware Unified Reinforcement Learning for Video Generative Models
Jan 16, 2026Physical principles are fundamental to realistic visual simulation, but remain a significant oversight in transformer-based video generation. This gap highlights a critical limitation in rendering rigid body motion, a core tenet of classical mechanics. While computer graphics and physics-based simulators can easily model such collisions using Newton formulas, modern pretrain-finetune paradigms discard the concept of object rigidity during pixel-level global denoising. Even perfectly correct mathematical constraints are treated as suboptimal solutions (i.e., conditions) during model optimization in post-training, fundamentally limiting the physical realism of generated videos. Motivated by these considerations, we introduce, for the first time, a physics-aware reinforcement learning paradigm for video generation models that enforces physical collision rules directly in high-dimensional spaces, ensuring the physics knowledge is strictly applied rather than treated as conditions. Subsequently, we extend this paradigm to a unified framework, termed Mimicry-Discovery Cycle (MDcycle), which allows substantial fine-tuning while fully preserving the model's ability to leverage physics-grounded feedback. To validate our approach, we construct new benchmark PhysRVGBench and perform extensive qualitative and quantitative experiments to thoroughly assess its effectiveness.
TinySR: Pruning Diffusion for Real-World Image Super-Resolution
Aug 24, 2025
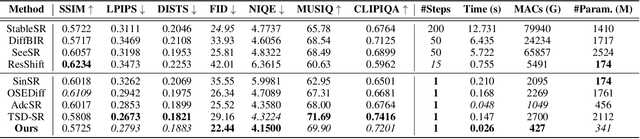
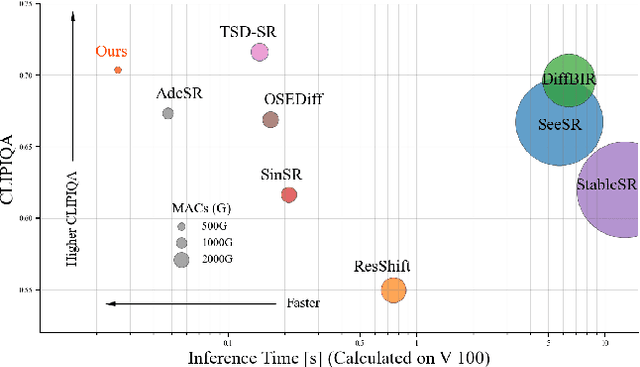
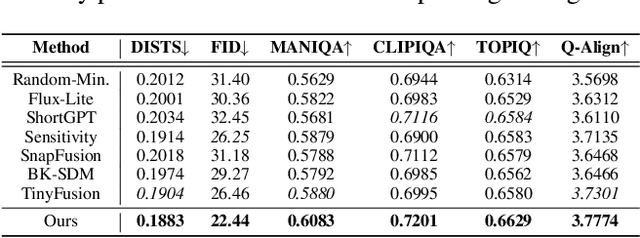
Real-world image super-resolution (Real-ISR) focuses on recovering high-quality images from low-resolution inputs that suffer from complex degradations like noise, blur, and compression. Recently, diffusion models (DMs) have shown great potential in this area by leveraging strong generative priors to restore fine details. However, their iterative denoising process incurs high computational overhead, posing challenges for real-time applications. Although one-step distillation methods, such as OSEDiff and TSD-SR, offer faster inference, they remain fundamentally constrained by their large, over-parameterized model architectures. In this work, we present TinySR, a compact yet effective diffusion model specifically designed for Real-ISR that achieves real-time performance while maintaining perceptual quality. We introduce a Dynamic Inter-block Activation and an Expansion-Corrosion Strategy to facilitate more effective decision-making in depth pruning. We achieve VAE compression through channel pruning, attention removal and lightweight SepConv. We eliminate time- and prompt-related modules and perform pre-caching techniques to further speed up the model. TinySR significantly reduces computational cost and model size, achieving up to 5.68x speedup and 83% parameter reduction compared to its teacher TSD-SR, while still providing high quality results.
Hi-VAE: Efficient Video Autoencoding with Global and Detailed Motion
Jun 08, 2025Recent breakthroughs in video autoencoders (Video AEs) have advanced video generation, but existing methods fail to efficiently model spatio-temporal redundancies in dynamics, resulting in suboptimal compression factors. This shortfall leads to excessive training costs for downstream tasks. To address this, we introduce Hi-VAE, an efficient video autoencoding framework that hierarchically encode coarse-to-fine motion representations of video dynamics and formulate the decoding process as a conditional generation task. Specifically, Hi-VAE decomposes video dynamics into two latent spaces: Global Motion, capturing overarching motion patterns, and Detailed Motion, encoding high-frequency spatial details. Using separate self-supervised motion encoders, we compress video latents into compact motion representations to reduce redundancy significantly. A conditional diffusion decoder then reconstructs videos by combining hierarchical global and detailed motions, enabling high-fidelity video reconstructions. Extensive experiments demonstrate that Hi-VAE achieves a high compression factor of 1428$\times$, almost 30$\times$ higher than baseline methods (e.g., Cosmos-VAE at 48$\times$), validating the efficiency of our approach. Meanwhile, Hi-VAE maintains high reconstruction quality at such high compression rates and performs effectively in downstream generative tasks. Moreover, Hi-VAE exhibits interpretability and scalability, providing new perspectives for future exploration in video latent representation and generation.
BiTrajDiff: Bidirectional Trajectory Generation with Diffusion Models for Offline Reinforcement Learning
Jun 06, 2025Recent advances in offline Reinforcement Learning (RL) have proven that effective policy learning can benefit from imposing conservative constraints on pre-collected datasets. However, such static datasets often exhibit distribution bias, resulting in limited generalizability. To address this limitation, a straightforward solution is data augmentation (DA), which leverages generative models to enrich data distribution. Despite the promising results, current DA techniques focus solely on reconstructing future trajectories from given states, while ignoring the exploration of history transitions that reach them. This single-direction paradigm inevitably hinders the discovery of diverse behavior patterns, especially those leading to critical states that may have yielded high-reward outcomes. In this work, we introduce Bidirectional Trajectory Diffusion (BiTrajDiff), a novel DA framework for offline RL that models both future and history trajectories from any intermediate states. Specifically, we decompose the trajectory generation task into two independent yet complementary diffusion processes: one generating forward trajectories to predict future dynamics, and the other generating backward trajectories to trace essential history transitions.BiTrajDiff can efficiently leverage critical states as anchors to expand into potentially valuable yet underexplored regions of the state space, thereby facilitating dataset diversity. Extensive experiments on the D4RL benchmark suite demonstrate that BiTrajDiff achieves superior performance compared to other advanced DA methods across various offline RL backbones.
SpatialCrafter: Unleashing the Imagination of Video Diffusion Models for Scene Reconstruction from Limited Observations
May 17, 2025Novel view synthesis (NVS) boosts immersive experiences in computer vision and graphics. Existing techniques, though progressed, rely on dense multi-view observations, restricting their application. This work takes on the challenge of reconstructing photorealistic 3D scenes from sparse or single-view inputs. We introduce SpatialCrafter, a framework that leverages the rich knowledge in video diffusion models to generate plausible additional observations, thereby alleviating reconstruction ambiguity. Through a trainable camera encoder and an epipolar attention mechanism for explicit geometric constraints, we achieve precise camera control and 3D consistency, further reinforced by a unified scale estimation strategy to handle scale discrepancies across datasets. Furthermore, by integrating monocular depth priors with semantic features in the video latent space, our framework directly regresses 3D Gaussian primitives and efficiently processes long-sequence features using a hybrid network structure. Extensive experiments show our method enhances sparse view reconstruction and restores the realistic appearance of 3D scenes.
LL-Gaussian: Low-Light Scene Reconstruction and Enhancement via Gaussian Splatting for Novel View Synthesis
Apr 15, 2025Novel view synthesis (NVS) in low-light scenes remains a significant challenge due to degraded inputs characterized by severe noise, low dynamic range (LDR) and unreliable initialization. While recent NeRF-based approaches have shown promising results, most suffer from high computational costs, and some rely on carefully captured or pre-processed data--such as RAW sensor inputs or multi-exposure sequences--which severely limits their practicality. In contrast, 3D Gaussian Splatting (3DGS) enables real-time rendering with competitive visual fidelity; however, existing 3DGS-based methods struggle with low-light sRGB inputs, resulting in unstable Gaussian initialization and ineffective noise suppression. To address these challenges, we propose LL-Gaussian, a novel framework for 3D reconstruction and enhancement from low-light sRGB images, enabling pseudo normal-light novel view synthesis. Our method introduces three key innovations: 1) an end-to-end Low-Light Gaussian Initialization Module (LLGIM) that leverages dense priors from learning-based MVS approach to generate high-quality initial point clouds; 2) a dual-branch Gaussian decomposition model that disentangles intrinsic scene properties (reflectance and illumination) from transient interference, enabling stable and interpretable optimization; 3) an unsupervised optimization strategy guided by both physical constrains and diffusion prior to jointly steer decomposition and enhancement. Additionally, we contribute a challenging dataset collected in extreme low-light environments and demonstrate the effectiveness of LL-Gaussian. Compared to state-of-the-art NeRF-based methods, LL-Gaussian achieves up to 2,000 times faster inference and reduces training time to just 2%, while delivering superior reconstruction and rendering quality.
Semantic Latent Motion for Portrait Video Generation
Mar 13, 2025



Recent advancements in portrait video generation have been noteworthy. However, existing methods rely heavily on human priors and pre-trained generation models, which may introduce unrealistic motion and lead to inefficient inference. To address these challenges, we propose Semantic Latent Motion (SeMo), a compact and expressive motion representation. Leveraging this representation, our approach achieve both high-quality visual results and efficient inference. SeMo follows an effective three-step framework: Abstraction, Reasoning, and Generation. First, in the Abstraction step, we use a carefully designed Mask Motion Encoder to compress the subject's motion state into a compact and abstract latent motion (1D token). Second, in the Reasoning step, long-term modeling and efficient reasoning are performed in this latent space to generate motion sequences. Finally, in the Generation step, the motion dynamics serve as conditional information to guide the generation model in synthesizing realistic transitions from reference frames to target frames. Thanks to the compact and descriptive nature of Semantic Latent Motion, our method enables real-time video generation with highly realistic motion. User studies demonstrate that our approach surpasses state-of-the-art models with an 81% win rate in realism. Extensive experiments further highlight its strong compression capability, reconstruction quality, and generative potential. Moreover, its fully self-supervised nature suggests promising applications in broader video generation tasks.
DecoupledGaussian: Object-Scene Decoupling for Physics-Based Interaction
Mar 07, 2025



We present DecoupledGaussian, a novel system that decouples static objects from their contacted surfaces captured in-the-wild videos, a key prerequisite for realistic Newtonian-based physical simulations. Unlike prior methods focused on synthetic data or elastic jittering along the contact surface, which prevent objects from fully detaching or moving independently, DecoupledGaussian allows for significant positional changes without being constrained by the initial contacted surface. Recognizing the limitations of current 2D inpainting tools for restoring 3D locations, our approach proposes joint Poisson fields to repair and expand the Gaussians of both objects and contacted scenes after separation. This is complemented by a multi-carve strategy to refine the object's geometry. Our system enables realistic simulations of decoupling motions, collisions, and fractures driven by user-specified impulses, supporting complex interactions within and across multiple scenes. We validate DecoupledGaussian through a comprehensive user study and quantitative benchmarks. This system enhances digital interaction with objects and scenes in real-world environments, benefiting industries such as VR, robotics, and autonomous driving. Our project page is at: https://wangmiaowei.github.io/DecoupledGaussian.github.io/.