 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Vision-Language-Action-Critic Model for Robotic Real-World Reinforcement Learning
Sep 19, 2025Robotic real-world reinforcement learning (RL) with vision-language-action (VLA) models is bottlenecked by sparse, handcrafted rewards and inefficient exploration. We introduce VLAC, a general process reward model built upon InternVL and trained on large scale heterogeneous datasets. Given pairwise observations and a language goal, it outputs dense progress delta and done signal, eliminating task-specific reward engineering, and supports one-shot in-context transfer to unseen tasks and environments. VLAC is trained on vision-language datasets to strengthen perception, dialogic and reasoning capabilities, together with robot and human trajectories data that ground action generation and progress estimation, and additionally strengthened to reject irrelevant prompts as well as detect regression or stagnation by constructing large numbers of negative and semantically mismatched samples. With prompt control, a single VLAC model alternately generating reward and action tokens, unifying critic and policy. Deployed inside an asynchronous real-world RL loop, we layer a graded human-in-the-loop protocol (offline demonstration replay, return and explore, human guided explore) that accelerates exploration and stabilizes early learning. Across four distinct real-world manipulation tasks, VLAC lifts success rates from about 30\% to about 90\% within 200 real-world interaction episodes; incorporating human-in-the-loop interventions yields a further 50% improvement in sample efficiency and achieves up to 100% final success.
BiTrajDiff: Bidirectional Trajectory Generation with Diffusion Models for Offline Reinforcement Learning
Jun 06, 2025Recent advances in offline Reinforcement Learning (RL) have proven that effective policy learning can benefit from imposing conservative constraints on pre-collected datasets. However, such static datasets often exhibit distribution bias, resulting in limited generalizability. To address this limitation, a straightforward solution is data augmentation (DA), which leverages generative models to enrich data distribution. Despite the promising results, current DA techniques focus solely on reconstructing future trajectories from given states, while ignoring the exploration of history transitions that reach them. This single-direction paradigm inevitably hinders the discovery of diverse behavior patterns, especially those leading to critical states that may have yielded high-reward outcomes. In this work, we introduce Bidirectional Trajectory Diffusion (BiTrajDiff), a novel DA framework for offline RL that models both future and history trajectories from any intermediate states. Specifically, we decompose the trajectory generation task into two independent yet complementary diffusion processes: one generating forward trajectories to predict future dynamics, and the other generating backward trajectories to trace essential history transitions.BiTrajDiff can efficiently leverage critical states as anchors to expand into potentially valuable yet underexplored regions of the state space, thereby facilitating dataset diversity. Extensive experiments on the D4RL benchmark suite demonstrate that BiTrajDiff achieves superior performance compared to other advanced DA methods across various offline RL backbones.
SignBot: Learning Human-to-Humanoid Sign Language Interaction
May 30, 2025Sign language is a natural and visual form of language that uses movements and expressions to convey meaning, serving as a crucial means of communication for individuals who are deaf or hard-of-hearing (DHH). However, the number of people proficient in sign language remains limited, highlighting the need for technological advancements to bridge communication gaps and foster interactions with minorities. Based on recent advancements in embodied humanoid robots, we propose SignBot, a novel framework for human-robot sign language interaction. SignBot integrates a cerebellum-inspired motion control component and a cerebral-oriented module for comprehension and interaction. Specifically, SignBot consists of: 1) Motion Retargeting, which converts human sign language datasets into robot-compatible kinematics; 2) Motion Control, which leverages a learning-based paradigm to develop a robust humanoid control policy for tracking sign language gestures; and 3) Generative Interaction, which incorporates translator, responser, and generator of sign language, thereby enabling natural and effective communication between robots and humans. Simulation and real-world experimental results demonstrate that SignBot can effectively facilitate human-robot interaction and perform sign language motions with diverse robots and datasets. SignBot represents a significant advancement in automatic sign language interaction on embodied humanoid robot platforms, providing a promising solution to improve communication accessibility for the DHH community.
SMAP: Self-supervised Motion Adaptation for Physically Plausible Humanoid Whole-body Control
May 26, 2025This paper presents a novel framework that enables real-world humanoid robots to maintain stability while performing human-like motion. Current methods train a policy which allows humanoid robots to follow human body using the massive retargeted human data via reinforcement learning. However, due to the heterogeneity between human and humanoid robot motion, directly using retargeted human motion reduces training efficiency and stability. To this end, we introduce SMAP, a novel whole-body tracking framework that bridges the gap between human and humanoid action spaces, enabling accurate motion mimicry by humanoid robots. The core idea is to use a vector-quantized periodic autoencoder to capture generic atomic behaviors and adapt human motion into physically plausible humanoid motion. This adaptation accelerates training convergence and improves stability when handling novel or challenging motions. We then employ a privileged teacher to distill precise mimicry skills into the student policy with a proposed decoupled reward. We conduct experiments in simulation and real world to demonstrate the superiority stability and performance of SMAP over SOTA methods, offering practical guidelines for advancing whole-body control in humanoid robots.
HWC-Loco: A Hierarchical Whole-Body Control Approach to Robust Humanoid Locomotion
Mar 02, 2025Humanoid robots, capable of assuming human roles in various workplaces, have become essential to the advancement of embodied intelligence. However, as robots with complex physical structures, learning a control model that can operate robustly across diverse environments remains inherently challenging, particularly under the discrepancies between training and deployment environments. In this study, we propose HWC-Loco, a robust whole-body control algorithm tailored for humanoid locomotion tasks. By reformulating policy learning as a robust optimization problem, HWC-Loco explicitly learns to recover from safety-critical scenarios. While prioritizing safety guarantees, overly conservative behavior can compromise the robot's ability to complete the given tasks. To tackle this challenge, HWC-Loco leverages a hierarchical policy for robust control. This policy can dynamically resolve the trade-off between goal-tracking and safety recovery, guided by human behavior norms and dynamic constraints. To evaluate the performance of HWC-Loco, we conduct extensive comparisons against state-of-the-art humanoid control models, demonstrating HWC-Loco's superior performance across diverse terrains, robot structures, and locomotion tasks under both simulated and real-world environments.
MASQ: Multi-Agent Reinforcement Learning for Single Quadruped Robot Locomotion
Aug 25, 2024

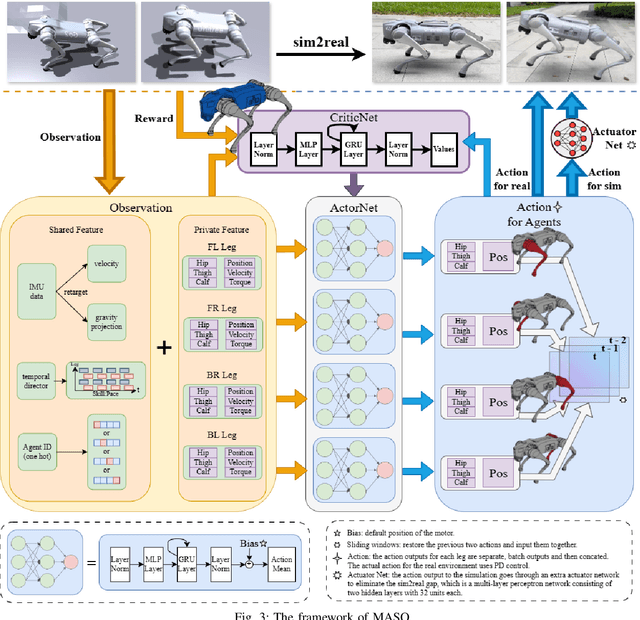
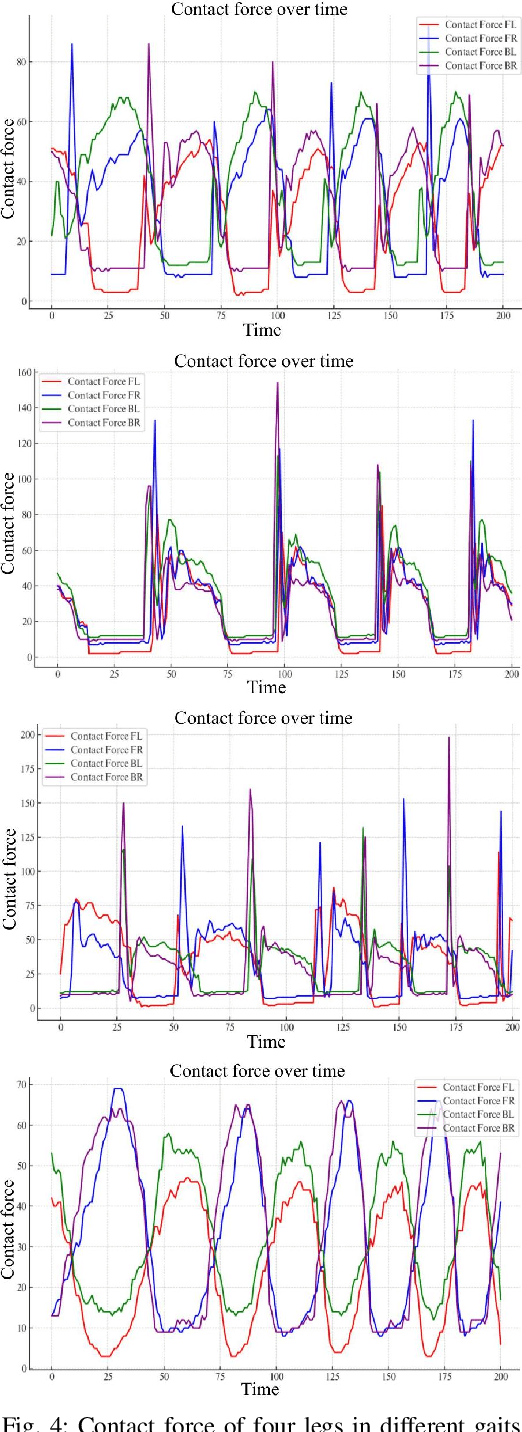
This paper proposes a novel method to improve locomotion learning for a single quadruped robot using multi-agent deep reinforcement learning (MARL). Many existing methods use single-agent reinforcement learning for an individual robot or MARL for the cooperative task in multi-robot systems. Unlike existing methods, this paper proposes using MARL for the locomotion learning of a single quadruped robot. We develop a learning structure called Multi-Agent Reinforcement Learning for Single Quadruped Robot Locomotion (MASQ), considering each leg as an agent to explore the action space of the quadruped robot, sharing a global critic, and learning collaboratively. Experimental results indicate that MASQ not only speeds up learning convergence but also enhances robustness in real-world settings, suggesting that applying MASQ to single robots such as quadrupeds could surpass traditional single-robot reinforcement learning approaches. Our study provides insightful guidance on integrating MARL with single-robot locomotion learning.