 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Reaction to Anticipation: Proactive Failure Recovery through Agentic Task Graph for Robotic Manipulation
May 12, 2026Although robotic manipulation has made significant progress, reliable execution remains challenging because task failures are inevitable in dynamic and unstructured environments. To handle such failures, existing frameworks typically follow a stepwise detect-reason-recover pipeline, which often incurs high latency and limited robustness due to delayed reasoning and reactive planning. Inspired by the human capability to anticipate and proactively plan for potential failures, we introduce AgentChord, an agentic system that models a manipulation task as a directed task graph. Before execution, this graph is enriched with anticipatory recovery branches that specify context-aware corrective behaviors, enabling immediate and targeted responses when failures occur. Specifically, AgentChord operates through a choreography of specialized agents: a composer that structures the nominal task graph, an arranger that augments the graph with anticipatory recovery branches, and a conductor that compiles and coordinates executable transitions using low-latency monitors to detect deviations and trigger pre-compiled recoveries without re-planning. Empirical studies on diverse long-horizon bimanual manipulation tasks demonstrate that AgentChord substantially improves success rates and execution efficiency, advancing the reliability and autonomy of real-world robotic systems. The project page is available at: https://shengxu.net/AgentChord/.
HWC-Loco: A Hierarchical Whole-Body Control Approach to Robust Humanoid Locomotion
Mar 02, 2025Humanoid robots, capable of assuming human roles in various workplaces, have become essential to the advancement of embodied intelligence. However, as robots with complex physical structures, learning a control model that can operate robustly across diverse environments remains inherently challenging, particularly under the discrepancies between training and deployment environments. In this study, we propose HWC-Loco, a robust whole-body control algorithm tailored for humanoid locomotion tasks. By reformulating policy learning as a robust optimization problem, HWC-Loco explicitly learns to recover from safety-critical scenarios. While prioritizing safety guarantees, overly conservative behavior can compromise the robot's ability to complete the given tasks. To tackle this challenge, HWC-Loco leverages a hierarchical policy for robust control. This policy can dynamically resolve the trade-off between goal-tracking and safety recovery, guided by human behavior norms and dynamic constraints. To evaluate the performance of HWC-Loco, we conduct extensive comparisons against state-of-the-art humanoid control models, demonstrating HWC-Loco's superior performance across diverse terrains, robot structures, and locomotion tasks under both simulated and real-world environments.
You Only Teach Once: Learn One-Shot Bimanual Robotic Manipulation from Video Demonstrations
Jan 24, 2025Bimanual robotic manipulation is a long-standing challenge of embodied intelligence due to its characteristics of dual-arm spatial-temporal coordination and high-dimensional action spaces. Previous studies rely on pre-defined action taxonomies or direct teleoperation to alleviate or circumvent these issues, often making them lack simplicity, versatility and scalability. Differently, we believe that the most effective and efficient way for teaching bimanual manipulation is learning from human demonstrated videos, where rich features such as spatial-temporal positions, dynamic postures, interaction states and dexterous transitions are available almost for free. In this work, we propose the YOTO (You Only Teach Once), which can extract and then inject patterns of bimanual actions from as few as a single binocular observation of hand movements, and teach dual robot arms various complex tasks. Furthermore, based on keyframes-based motion trajectories, we devise a subtle solution for rapidly generating training demonstrations with diverse variations of manipulated objects and their locations. These data can then be used to learn a customized bimanual diffusion policy (BiDP) across diverse scenes. In experiments, YOTO achieves impressive performance in mimicking 5 intricate long-horizon bimanual tasks, possesses strong generalization under different visual and spatial conditions, and outperforms existing visuomotor imitation learning methods in accuracy and efficiency. Our project link is https://hnuzhy.github.io/projects/YOTO.
Grasp Proposal Networks: An End-to-End Solution for Visual Learning of Robotic Grasps
Sep 26, 2020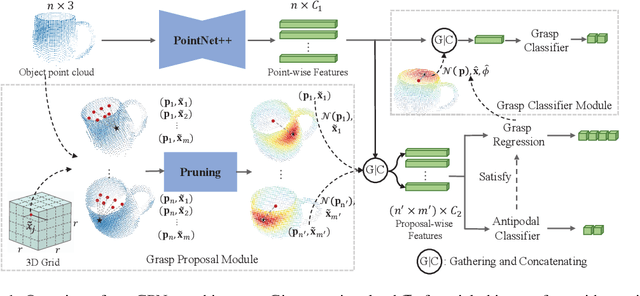
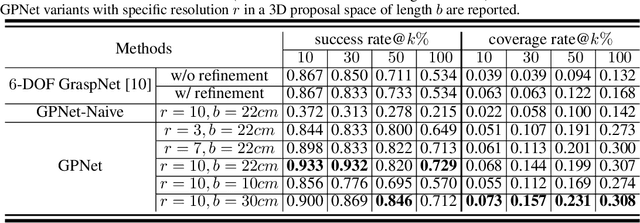
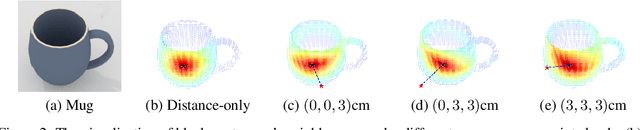
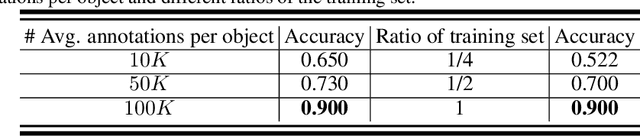
Learning robotic grasps from visual observations is a promising yet challenging task. Recent research shows its great potential by preparing and learning from large-scale synthetic datasets. For the popular, 6 degree-of-freedom (6-DOF) grasp setting of parallel-jaw gripper, most of existing methods take the strategy of heuristically sampling grasp candidates and then evaluating them using learned scoring functions. This strategy is limited in terms of the conflict between sampling efficiency and coverage of optimal grasps. To this end, we propose in this work a novel, end-to-end \emph{Grasp Proposal Network (GPNet)}, to predict a diverse set of 6-DOF grasps for an unseen object observed from a single and unknown camera view. GPNet builds on a key design of grasp proposal module that defines \emph{anchors of grasp centers} at discrete but regular 3D grid corners, which is flexible to support either more precise or more diverse grasp predictions. To test GPNet, we contribute a synthetic dataset of 6-DOF object grasps; evaluation is conducted using rule-based criteria, simulation test, and real test. Comparative results show the advantage of our methods over existing ones. Notably, GPNet gains better simulation results via the specified coverage, which helps achieve a ready translation in real test. We will make our dataset publicly available.