 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D AffordanceNet: A Benchmark for Visual Object Affordance Understanding
Mar 31, 2021

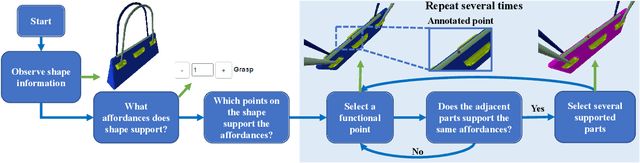
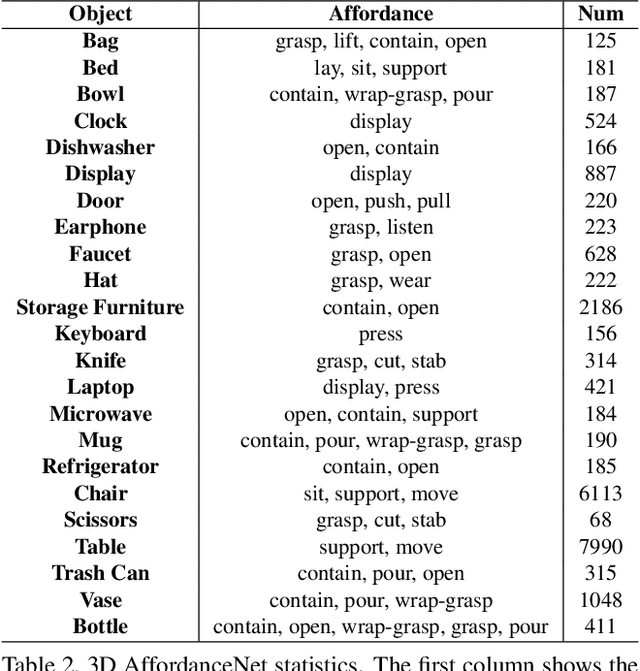
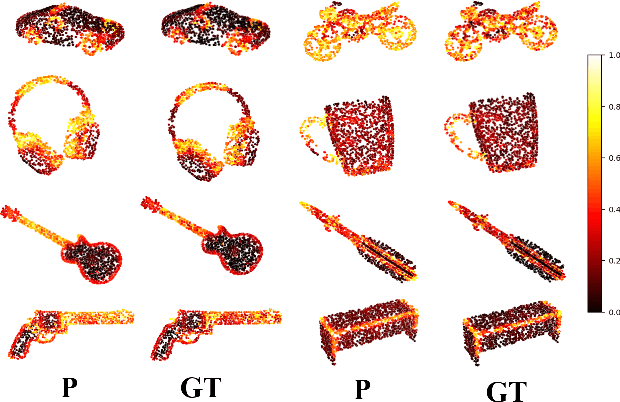
The ability to understand the ways to interact with objects from visual cues, a.k.a. visual affordance, is essential to vision-guided robotic research. This involves categorizing, segmenting and reasoning of visual affordance. Relevant studies in 2D and 2.5D image domains have been made previously, however, a truly functional understanding of object affordance requires learning and prediction in the 3D physical domain, which is still absent in the community. In this work, we present a 3D AffordanceNet dataset, a benchmark of 23k shapes from 23 semantic object categories, annotated with 18 visual affordance categories. Based on this dataset, we provide three benchmarking tasks for evaluating visual affordance understanding, including full-shape, partial-view and rotation-invariant affordance estimations. Three state-of-the-art point cloud deep learning networks are evaluated on all tasks. In addition we also investigate a semi-supervised learning setup to explore the possibility to benefit from unlabeled data. Comprehensive results on our contributed dataset show the promise of visual affordance understanding as a valuable yet challenging benchmark.
Learning Category-level Shape Saliency via Deep Implicit Surface Networks
Dec 14, 2020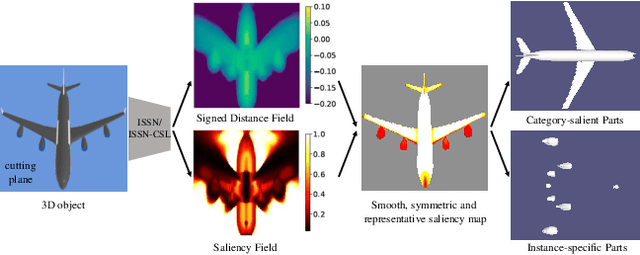
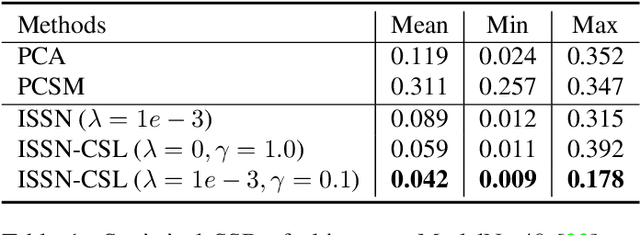
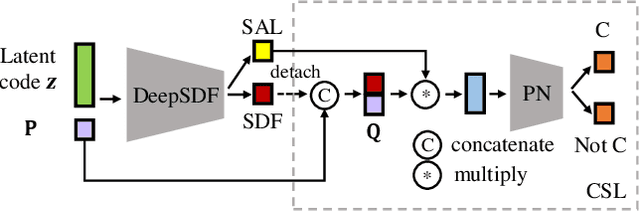

This paper is motivated from a fundamental curiosity on what defines a category of object shapes. For example, we may have the common knowledge that a plane has wings, and a chair has legs. Given the large shape variations among different instances of a same category, we are formally interested in developing a quantity defined for individual points on a continuous object surface; the quantity specifies how individual surface points contribute to the formation of the shape as the category. We term such a quantity as category-level shape saliency or shape saliency for short. Technically, we propose to learn saliency maps for shape instances of a same category from a deep implicit surface network; sensible saliency scores for sampled points in the implicit surface field are predicted by constraining the capacity of input latent code. We also enhance the saliency prediction with an additional loss of contrastive training. We expect such learned surface maps of shape saliency to have the properties of smoothness, symmetry, and semantic representativeness. We verify these properties by comparing our method with alternative ways of saliency computation. Notably, we show that by leveraging the learned shape saliency, we are able to reconstruct either category-salient or instance-specific parts of object surfaces; semantic representativeness of the learned saliency is also reflected in its efficacy to guide the selection of surface points for better point cloud classification.
Grasp Proposal Networks: An End-to-End Solution for Visual Learning of Robotic Grasps
Sep 26, 2020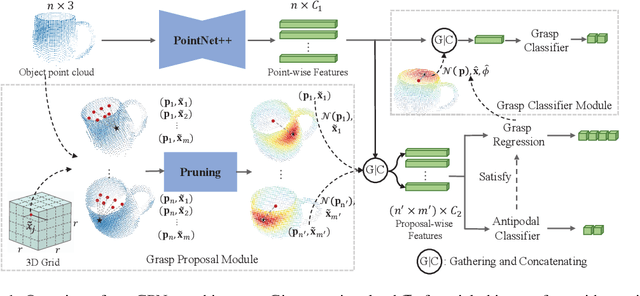
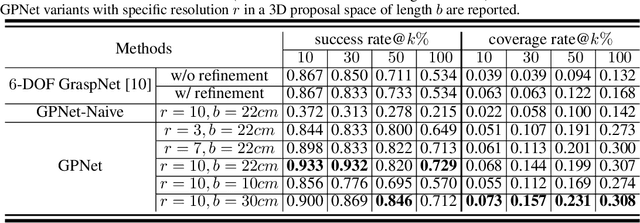
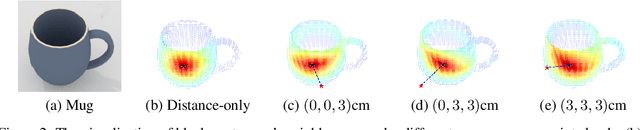
Learning robotic grasps from visual observations is a promising yet challenging task. Recent research shows its great potential by preparing and learning from large-scale synthetic datasets. For the popular, 6 degree-of-freedom (6-DOF) grasp setting of parallel-jaw gripper, most of existing methods take the strategy of heuristically sampling grasp candidates and then evaluating them using learned scoring functions. This strategy is limited in terms of the conflict between sampling efficiency and coverage of optimal grasps. To this end, we propose in this work a novel, end-to-end \emph{Grasp Proposal Network (GPNet)}, to predict a diverse set of 6-DOF grasps for an unseen object observed from a single and unknown camera view. GPNet builds on a key design of grasp proposal module that defines \emph{anchors of grasp centers} at discrete but regular 3D grid corners, which is flexible to support either more precise or more diverse grasp predictions. To test GPNet, we contribute a synthetic dataset of 6-DOF object grasps; evaluation is conducted using rule-based criteria, simulation test, and real test. Comparative results show the advantage of our methods over existing ones. Notably, GPNet gains better simulation results via the specified coverage, which helps achieve a ready translation in real test. We will make our dataset publicly available.
Improving Semantic Analysis on Point Clouds via Auxiliary Supervision of Local Geometric Priors
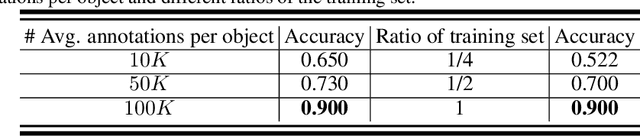
Jan 14, 2020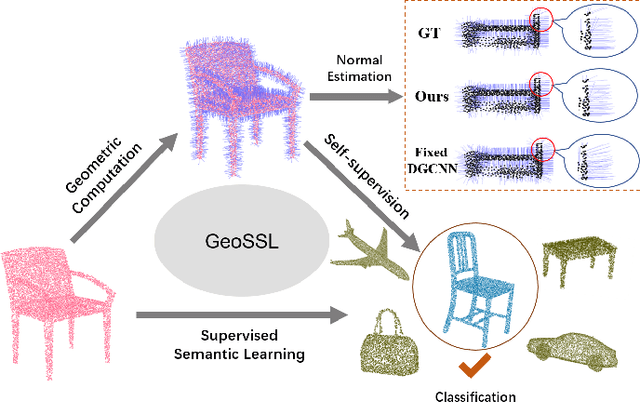
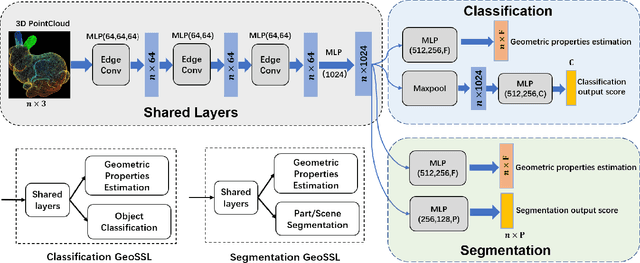
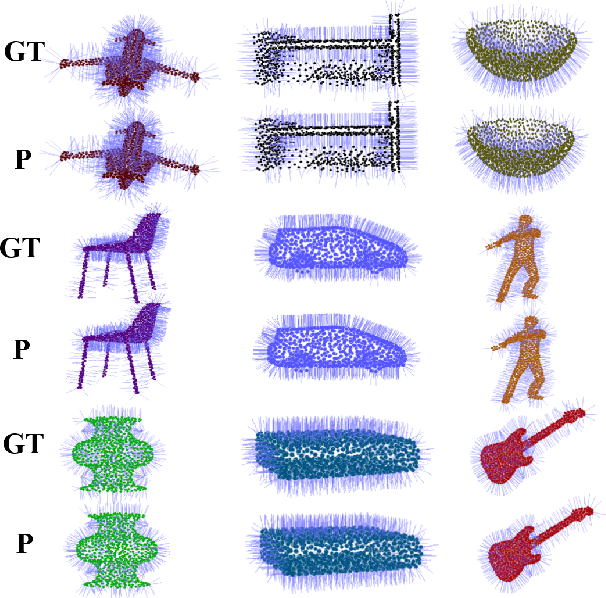
Existing deep learning algorithms for point cloud analysis mainly concern discovering semantic patterns from global configuration of local geometries in a supervised learning manner. However, very few explore geometric properties revealing local surface manifolds embedded in 3D Euclidean space to discriminate semantic classes or object parts as additional supervision signals. This paper is the first attempt to propose a unique multi-task geometric learning network to improve semantic analysis by auxiliary geometric learning with local shape properties, which can be either generated via physical computation from point clouds themselves as self-supervision signals or provided as privileged information. Owing to explicitly encoding local shape manifolds in favor of semantic analysis, the proposed geometric self-supervised and privileged learning algorithms can achieve superior performance to their backbone baselines and other state-of-the-art methods, which are verified in the experiments on the popular benchmarks.