 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexterity-BEV: Aligning 3D World and Actions for Generalizable Robot Policies Learning
Jun 01, 2026End-to-end manipulation policies, combined with web-scale pretrained Vision-Language Models (VLMs), show the promise for generalizable and dexterous robotic manipulation. However, they inherit two key limitations from 2D foundation models: 1) the reliance on 2D RGB inputs that ignores the intrinsically 3D nature of manipulation; and 2) the lack of spatial 3D alignment between input-output spaces as well as across diverse robot embodiments, camera setups, and trajectory datasets. In this paper, we present a series of contributions to address these issues. First, we introduce aligned vertex map and vertex spectrum -- a pixel-wise 3D representation that elevates 2D visual inputs to 3D, using camera calibration and optional depth. This novel input representation marries 3D awareness with the generalization of 2D large VLMs. Then, we propose to align the inputs and outputs of manipulation policies by expressing per-pixel 3D information of each camera view and robot actions to a shared coordinate. Based on this, we designate a canonical Bird's-Eye-View (BEV) alignment frame and innovatively propose to construct BEV images, producing a view-invariant representation robust to camera pose variations. To enable training and evaluation at scale, we develop a comprehensive data processing pipeline to perform such alignments; we also introduce a novel temporal alignment scheme for trajectories across diverse robots, human operators, and datasets. These contributions collectively mitigate input and output spatial-temporal misalignments, improving the consistency and generalization for real-world manipulation. Pretrained checkpoint, source code and data processing pipeline are available in https://hnuzhy.github.io/projects/Dex-BEV.
From Reaction to Anticipation: Proactive Failure Recovery through Agentic Task Graph for Robotic Manipulation
May 12, 2026Although robotic manipulation has made significant progress, reliable execution remains challenging because task failures are inevitable in dynamic and unstructured environments. To handle such failures, existing frameworks typically follow a stepwise detect-reason-recover pipeline, which often incurs high latency and limited robustness due to delayed reasoning and reactive planning. Inspired by the human capability to anticipate and proactively plan for potential failures, we introduce AgentChord, an agentic system that models a manipulation task as a directed task graph. Before execution, this graph is enriched with anticipatory recovery branches that specify context-aware corrective behaviors, enabling immediate and targeted responses when failures occur. Specifically, AgentChord operates through a choreography of specialized agents: a composer that structures the nominal task graph, an arranger that augments the graph with anticipatory recovery branches, and a conductor that compiles and coordinates executable transitions using low-latency monitors to detect deviations and trigger pre-compiled recoveries without re-planning. Empirical studies on diverse long-horizon bimanual manipulation tasks demonstrate that AgentChord substantially improves success rates and execution efficiency, advancing the reliability and autonomy of real-world robotic systems. The project page is available at: https://shengxu.net/AgentChord/.
HACMatch Semi-Supervised Rotation Regression with Hardness-Aware Curriculum Pseudo Labeling
Mar 23, 2026Regressing 3D rotations of objects from 2D images is a crucial yet challenging task, with broad applications in autonomous driving, virtual reality, and robotic control. Existing rotation regression models often rely on large amounts of labeled data for training or require additional information beyond 2D images, such as point clouds or CAD models. Therefore, exploring semi-supervised rotation regression using only a limited number of labeled 2D images is highly valuable. While recent work FisherMatch introduces semi-supervised learning to rotation regression, it suffers from rigid entropy-based pseudo-label filtering that fails to effectively distinguish between reliable and unreliable unlabeled samples. To address this limitation, we propose a hardness-aware curriculum learning framework that dynamically selects pseudo-labeled samples based on their difficulty, progressing from easy to complex examples. We introduce both multi-stage and adaptive curriculum strategies to replace fixed-threshold filtering with more flexible, hardness-aware mechanisms. Additionally, we present a novel structured data augmentation strategy specifically tailored for rotation estimation, which assembles composite images from augmented patches to introduce feature diversity while preserving critical geometric integrity. Comprehensive experiments on PASCAL3D+ and ObjectNet3D demonstrate that our method outperforms existing supervised and semi-supervised baselines, particularly in low-data regimes, validating the effectiveness of our curriculum learning framework and structured augmentation approach.
* This is an accepted manuscript of an article published in Computer Vision and Image Understanding
One-Shot Real-World Demonstration Synthesis for Scalable Bimanual Manipulation
Dec 10, 2025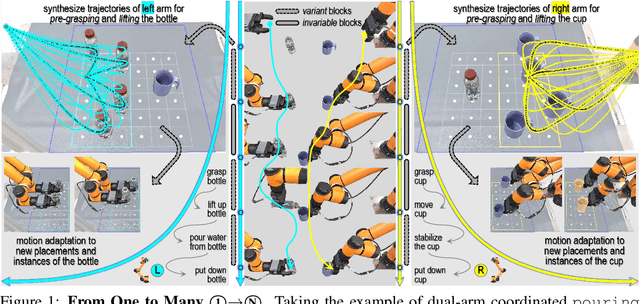

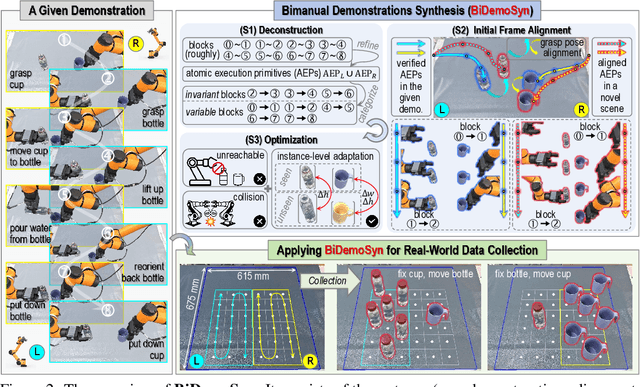

Learning dexterous bimanual manipulation policies critically depends on large-scale, high-quality demonstrations, yet current paradigms face inherent trade-offs: teleoperation provides physically grounded data but is prohibitively labor-intensive, while simulation-based synthesis scales efficiently but suffers from sim-to-real gaps. We present BiDemoSyn, a framework that synthesizes contact-rich, physically feasible bimanual demonstrations from a single real-world example. The key idea is to decompose tasks into invariant coordination blocks and variable, object-dependent adjustments, then adapt them through vision-guided alignment and lightweight trajectory optimization. This enables the generation of thousands of diverse and feasible demonstrations within several hour, without repeated teleoperation or reliance on imperfect simulation. Across six dual-arm tasks, we show that policies trained on BiDemoSyn data generalize robustly to novel object poses and shapes, significantly outperforming recent baselines. By bridging the gap between efficiency and real-world fidelity, BiDemoSyn provides a scalable path toward practical imitation learning for complex bimanual manipulation without compromising physical grounding.
GAT-Grasp: Gesture-Driven Affordance Transfer for Task-Aware Robotic Grasping
Mar 08, 2025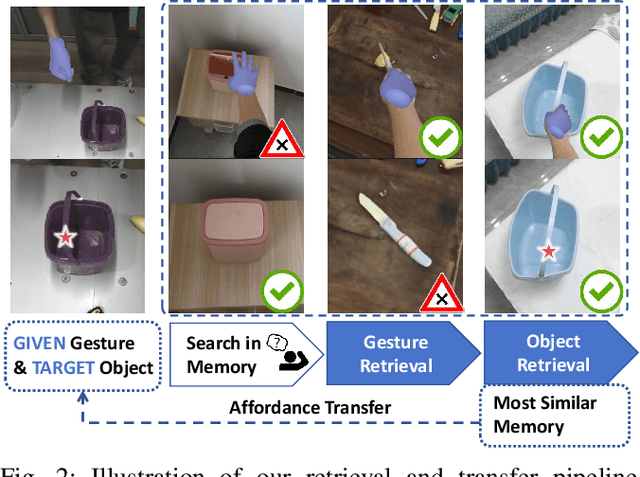


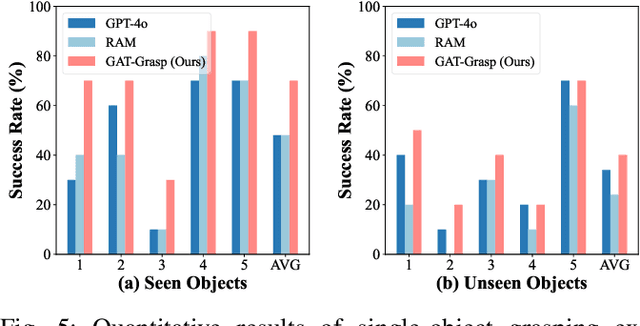
Achieving precise and generalizable grasping across diverse objects and environments is essential for intelligent and collaborative robotic systems. However, existing approaches often struggle with ambiguous affordance reasoning and limited adaptability to unseen objects, leading to suboptimal grasp execution. In this work, we propose GAT-Grasp, a gesture-driven grasping framework that directly utilizes human hand gestures to guide the generation of task-specific grasp poses with appropriate positioning and orientation. Specifically, we introduce a retrieval-based affordance transfer paradigm, leveraging the implicit correlation between hand gestures and object affordances to extract grasping knowledge from large-scale human-object interaction videos. By eliminating the reliance on pre-given object priors, GAT-Grasp enables zero-shot generalization to novel objects and cluttered environments. Real-world evaluations confirm its robustness across diverse and unseen scenarios, demonstrating reliable grasp execution in complex task settings.
You Only Teach Once: Learn One-Shot Bimanual Robotic Manipulation from Video Demonstrations
Jan 24, 2025Bimanual robotic manipulation is a long-standing challenge of embodied intelligence due to its characteristics of dual-arm spatial-temporal coordination and high-dimensional action spaces. Previous studies rely on pre-defined action taxonomies or direct teleoperation to alleviate or circumvent these issues, often making them lack simplicity, versatility and scalability. Differently, we believe that the most effective and efficient way for teaching bimanual manipulation is learning from human demonstrated videos, where rich features such as spatial-temporal positions, dynamic postures, interaction states and dexterous transitions are available almost for free. In this work, we propose the YOTO (You Only Teach Once), which can extract and then inject patterns of bimanual actions from as few as a single binocular observation of hand movements, and teach dual robot arms various complex tasks. Furthermore, based on keyframes-based motion trajectories, we devise a subtle solution for rapidly generating training demonstrations with diverse variations of manipulated objects and their locations. These data can then be used to learn a customized bimanual diffusion policy (BiDP) across diverse scenes. In experiments, YOTO achieves impressive performance in mimicking 5 intricate long-horizon bimanual tasks, possesses strong generalization under different visual and spatial conditions, and outperforms existing visuomotor imitation learning methods in accuracy and efficiency. Our project link is https://hnuzhy.github.io/projects/YOTO.
Semi-Supervised Unconstrained Head Pose Estimation in the Wild
Apr 03, 2024
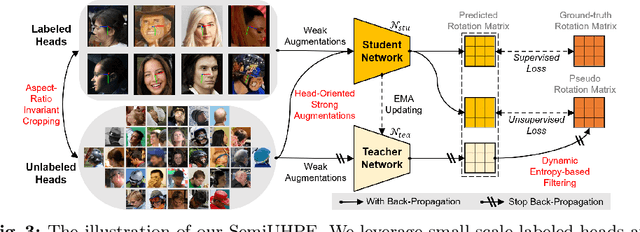
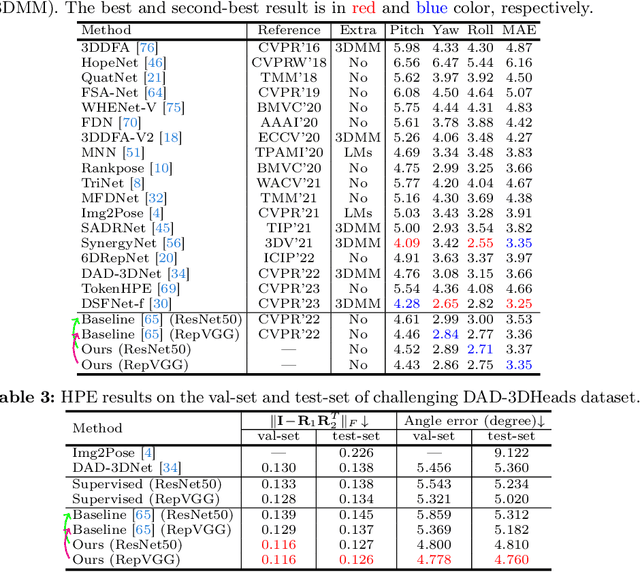
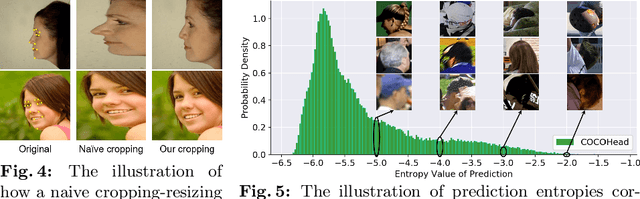
Existing head pose estimation datasets are either composed of numerous samples by non-realistic synthesis or lab collection, or limited images by labor-intensive annotating. This makes deep supervised learning based solutions compromised due to the reliance on generous labeled data. To alleviate it, we propose the first semi-supervised unconstrained head pose estimation (SemiUHPE) method, which can leverage a large amount of unlabeled wild head images. Specifically, we follow the recent semi-supervised rotation regression, and focus on the diverse and complex head pose domain. Firstly, we claim that the aspect-ratio invariant cropping of heads is superior to the previous landmark-based affine alignment, which does not fit unlabeled natural heads or practical applications where landmarks are often unavailable. Then, instead of using an empirically fixed threshold to filter out pseudo labels, we propose the dynamic entropy-based filtering by updating thresholds for adaptively removing unlabeled outliers. Moreover, we revisit the design of weak-strong augmentations, and further exploit its superiority by devising two novel head-oriented strong augmentations named pose-irrelevant cut-occlusion and pose-altering rotation consistency. Extensive experiments show that SemiUHPE can surpass SOTAs with remarkable improvements on public benchmarks under both front-range and full-range. Our code is released in \url{https://github.com/hnuzhy/SemiUHPE}.
Boosting Semi-Supervised 2D Human Pose Estimation by Revisiting Data Augmentation and Consistency Training
Feb 18, 2024



The 2D human pose estimation is a basic visual problem. However, supervised learning of a model requires massive labeled images, which is expensive and labor-intensive. In this paper, we aim at boosting the accuracy of a pose estimator by excavating extra unlabeled images in a semi-supervised learning (SSL) way. Most previous consistency-based SSL methods strive to constraint the model to predict consistent results for differently augmented images. Following this consensus, we revisit two core aspects including advanced data augmentation methods and concise consistency training frameworks. Specifically, we heuristically dig various collaborative combinations of existing data augmentations, and discover novel superior data augmentation schemes to more effectively add noise on unlabeled samples. They can compose easy-hard augmentation pairs with larger transformation difficulty gaps, which play a crucial role in consistency-based SSL. Moreover, we propose to strongly augment unlabeled images repeatedly with diverse augmentations, generate multi-path predictions sequentially, and optimize corresponding unsupervised consistency losses using one single network. This simple and compact design is on a par with previous methods consisting of dual or triple networks. Furthermore, it can also be integrated with multiple networks to produce better performance. Comparing to state-of-the-art SSL approaches, our method brings substantial improvements on public datasets. Code is released for academic use in \url{https://github.com/hnuzhy/MultiAugs}.
PBADet: A One-Stage Anchor-Free Approach for Part-Body Association
Feb 12, 2024



The detection of human parts (e.g., hands, face) and their correct association with individuals is an essential task, e.g., for ubiquitous human-machine interfaces and action recognition. Traditional methods often employ multi-stage processes, rely on cumbersome anchor-based systems, or do not scale well to larger part sets. This paper presents PBADet, a novel one-stage, anchor-free approach for part-body association detection. Building upon the anchor-free object representation across multi-scale feature maps, we introduce a singular part-to-body center offset that effectively encapsulates the relationship between parts and their parent bodies. Our design is inherently versatile and capable of managing multiple parts-to-body associations without compromising on detection accuracy or robustness. Comprehensive experiments on various datasets underscore the efficacy of our approach, which not only outperforms existing state-of-the-art techniques but also offers a more streamlined and efficient solution to the part-body association challenge.
Contrast, Stylize and Adapt: Unsupervised Contrastive Learning Framework for Domain Adaptive Semantic Segmentation
Jun 15, 2023



To overcome the domain gap between synthetic and real-world datasets, unsupervised domain adaptation methods have been proposed for semantic segmentation. Majority of the previous approaches have attempted to reduce the gap either at the pixel or feature level, disregarding the fact that the two components interact positively. To address this, we present CONtrastive FEaTure and pIxel alignment (CONFETI) for bridging the domain gap at both the pixel and feature levels using a unique contrastive formulation. We introduce well-estimated prototypes by including category-wise cross-domain information to link the two alignments: the pixel-level alignment is achieved using the jointly trained style transfer module with the prototypical semantic consistency, while the feature-level alignment is enforced to cross-domain features with the \textbf{pixel-to-prototype contrast}. Our extensive experiments demonstrate that our method outperforms existing state-of-the-art methods using DeepLabV2. Our code is available at https://github.com/cxa9264/CONFETI