 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Semi-Supervised 2D Human Pose Estimation by Revisiting Data Augmentation and Consistency Training
Feb 18, 2024The 2D human pose estimation is a basic visual problem. However, supervised learning of a model requires massive labeled images, which is expensive and labor-intensive. In this paper, we aim at boosting the accuracy of a pose estimator by excavating extra unlabeled images in a semi-supervised learning (SSL) way. Most previous consistency-based SSL methods strive to constraint the model to predict consistent results for differently augmented images. Following this consensus, we revisit two core aspects including advanced data augmentation methods and concise consistency training frameworks. Specifically, we heuristically dig various collaborative combinations of existing data augmentations, and discover novel superior data augmentation schemes to more effectively add noise on unlabeled samples. They can compose easy-hard augmentation pairs with larger transformation difficulty gaps, which play a crucial role in consistency-based SSL. Moreover, we propose to strongly augment unlabeled images repeatedly with diverse augmentations, generate multi-path predictions sequentially, and optimize corresponding unsupervised consistency losses using one single network. This simple and compact design is on a par with previous methods consisting of dual or triple networks. Furthermore, it can also be integrated with multiple networks to produce better performance. Comparing to state-of-the-art SSL approaches, our method brings substantial improvements on public datasets. Code is released for academic use in \url{https://github.com/hnuzhy/MultiAugs}.
FULLER: Unified Multi-modality Multi-task 3D Perception via Multi-level Gradient Calibration
Jul 31, 2023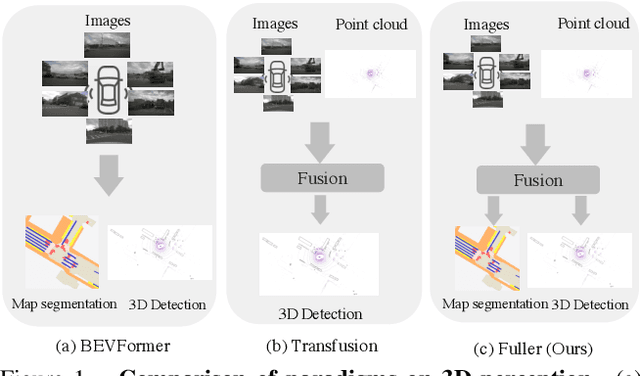
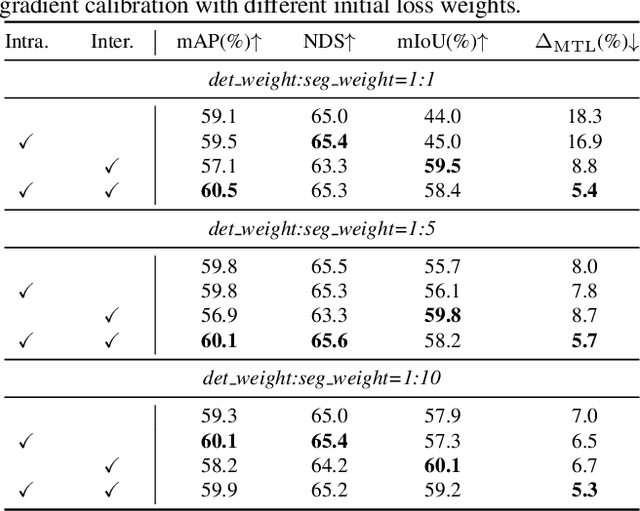
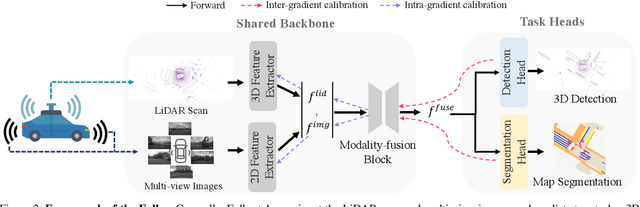
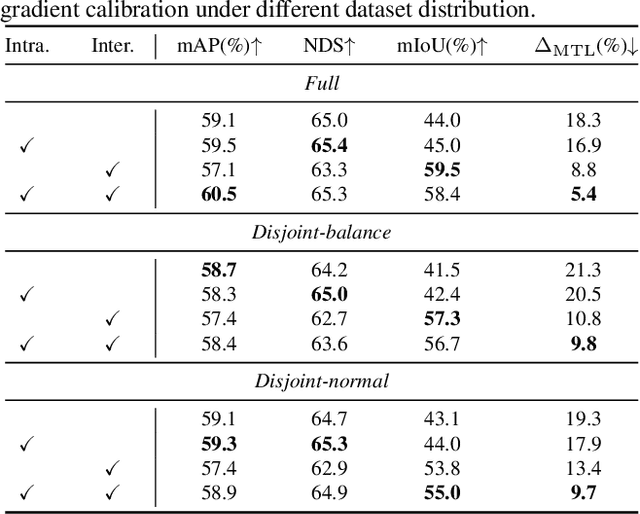
Multi-modality fusion and multi-task learning are becoming trendy in 3D autonomous driving scenario, considering robust prediction and computation budget. However, naively extending the existing framework to the domain of multi-modality multi-task learning remains ineffective and even poisonous due to the notorious modality bias and task conflict. Previous works manually coordinate the learning framework with empirical knowledge, which may lead to sub-optima. To mitigate the issue, we propose a novel yet simple multi-level gradient calibration learning framework across tasks and modalities during optimization. Specifically, the gradients, produced by the task heads and used to update the shared backbone, will be calibrated at the backbone's last layer to alleviate the task conflict. Before the calibrated gradients are further propagated to the modality branches of the backbone, their magnitudes will be calibrated again to the same level, ensuring the downstream tasks pay balanced attention to different modalities. Experiments on large-scale benchmark nuScenes demonstrate the effectiveness of the proposed method, eg, an absolute 14.4% mIoU improvement on map segmentation and 1.4% mAP improvement on 3D detection, advancing the application of 3D autonomous driving in the domain of multi-modality fusion and multi-task learning. We also discuss the links between modalities and tasks.