 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Reaction to Anticipation: Proactive Failure Recovery through Agentic Task Graph for Robotic Manipulation
May 12, 2026Although robotic manipulation has made significant progress, reliable execution remains challenging because task failures are inevitable in dynamic and unstructured environments. To handle such failures, existing frameworks typically follow a stepwise detect-reason-recover pipeline, which often incurs high latency and limited robustness due to delayed reasoning and reactive planning. Inspired by the human capability to anticipate and proactively plan for potential failures, we introduce AgentChord, an agentic system that models a manipulation task as a directed task graph. Before execution, this graph is enriched with anticipatory recovery branches that specify context-aware corrective behaviors, enabling immediate and targeted responses when failures occur. Specifically, AgentChord operates through a choreography of specialized agents: a composer that structures the nominal task graph, an arranger that augments the graph with anticipatory recovery branches, and a conductor that compiles and coordinates executable transitions using low-latency monitors to detect deviations and trigger pre-compiled recoveries without re-planning. Empirical studies on diverse long-horizon bimanual manipulation tasks demonstrate that AgentChord substantially improves success rates and execution efficiency, advancing the reliability and autonomy of real-world robotic systems. The project page is available at: https://shengxu.net/AgentChord/.
aiXiv: A Next-Generation Open Access Ecosystem for Scientific Discovery Generated by AI Scientists
Aug 20, 2025Recent advances in large language models (LLMs) have enabled AI agents to autonomously generate scientific proposals, conduct experiments, author papers, and perform peer reviews. Yet this flood of AI-generated research content collides with a fragmented and largely closed publication ecosystem. Traditional journals and conferences rely on human peer review, making them difficult to scale and often reluctant to accept AI-generated research content; existing preprint servers (e.g. arXiv) lack rigorous quality-control mechanisms. Consequently, a significant amount of high-quality AI-generated research lacks appropriate venues for dissemination, hindering its potential to advance scientific progress. To address these challenges, we introduce aiXiv, a next-generation open-access platform for human and AI scientists. Its multi-agent architecture allows research proposals and papers to be submitted, reviewed, and iteratively refined by both human and AI scientists. It also provides API and MCP interfaces that enable seamless integration of heterogeneous human and AI scientists, creating a scalable and extensible ecosystem for autonomous scientific discovery. Through extensive experiments, we demonstrate that aiXiv is a reliable and robust platform that significantly enhances the quality of AI-generated research proposals and papers after iterative revising and reviewing on aiXiv. Our work lays the groundwork for a next-generation open-access ecosystem for AI scientists, accelerating the publication and dissemination of high-quality AI-generated research content. Code is available at https://github.com/aixiv-org. Website is available at https://forms.gle/DxQgCtXFsJ4paMtn8.
SignBot: Learning Human-to-Humanoid Sign Language Interaction
May 30, 2025Sign language is a natural and visual form of language that uses movements and expressions to convey meaning, serving as a crucial means of communication for individuals who are deaf or hard-of-hearing (DHH). However, the number of people proficient in sign language remains limited, highlighting the need for technological advancements to bridge communication gaps and foster interactions with minorities. Based on recent advancements in embodied humanoid robots, we propose SignBot, a novel framework for human-robot sign language interaction. SignBot integrates a cerebellum-inspired motion control component and a cerebral-oriented module for comprehension and interaction. Specifically, SignBot consists of: 1) Motion Retargeting, which converts human sign language datasets into robot-compatible kinematics; 2) Motion Control, which leverages a learning-based paradigm to develop a robust humanoid control policy for tracking sign language gestures; and 3) Generative Interaction, which incorporates translator, responser, and generator of sign language, thereby enabling natural and effective communication between robots and humans. Simulation and real-world experimental results demonstrate that SignBot can effectively facilitate human-robot interaction and perform sign language motions with diverse robots and datasets. SignBot represents a significant advancement in automatic sign language interaction on embodied humanoid robot platforms, providing a promising solution to improve communication accessibility for the DHH community.
HWC-Loco: A Hierarchical Whole-Body Control Approach to Robust Humanoid Locomotion
Mar 02, 2025Humanoid robots, capable of assuming human roles in various workplaces, have become essential to the advancement of embodied intelligence. However, as robots with complex physical structures, learning a control model that can operate robustly across diverse environments remains inherently challenging, particularly under the discrepancies between training and deployment environments. In this study, we propose HWC-Loco, a robust whole-body control algorithm tailored for humanoid locomotion tasks. By reformulating policy learning as a robust optimization problem, HWC-Loco explicitly learns to recover from safety-critical scenarios. While prioritizing safety guarantees, overly conservative behavior can compromise the robot's ability to complete the given tasks. To tackle this challenge, HWC-Loco leverages a hierarchical policy for robust control. This policy can dynamically resolve the trade-off between goal-tracking and safety recovery, guided by human behavior norms and dynamic constraints. To evaluate the performance of HWC-Loco, we conduct extensive comparisons against state-of-the-art humanoid control models, demonstrating HWC-Loco's superior performance across diverse terrains, robot structures, and locomotion tasks under both simulated and real-world environments.
Mimicking Human Intuition: Cognitive Belief-Driven Q-Learning
Oct 02, 2024



Reinforcement learning encounters challenges in various environments related to robustness and explainability. Traditional Q-learning algorithms cannot effectively make decisions and utilize the historical learning experience. To overcome these limitations, we propose Cognitive Belief-Driven Q-Learning (CBDQ), which integrates subjective belief modeling into the Q-learning framework, enhancing decision-making accuracy by endowing agents with human-like learning and reasoning capabilities. Drawing inspiration from cognitive science, our method maintains a subjective belief distribution over the expectation of actions, leveraging a cluster-based subjective belief model that enables agents to reason about the potential probability associated with each decision. CBDQ effectively mitigates overestimated phenomena and optimizes decision-making policies by integrating historical experiences with current contextual information, mimicking the dynamics of human decision-making. We evaluate the proposed method on discrete control benchmark tasks in various complicate environments. The results demonstrate that CBDQ exhibits stronger adaptability, robustness, and human-like characteristics in handling these environments, outperforming other baselines. We hope this work will give researchers a fresh perspective on understanding and explaining Q-learning.
TrafficGamer: Reliable and Flexible Traffic Simulation for Safety-Critical Scenarios with Game-Theoretic Oracles
Aug 28, 2024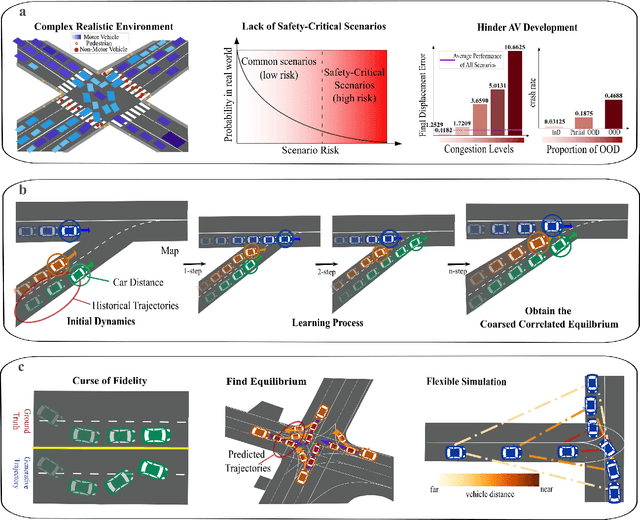
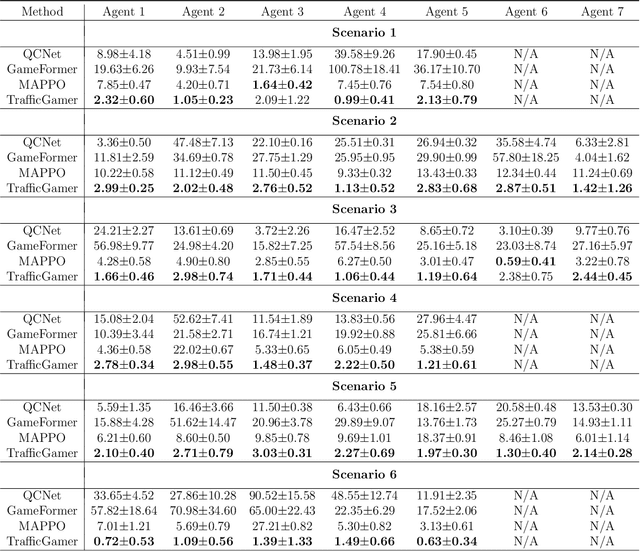
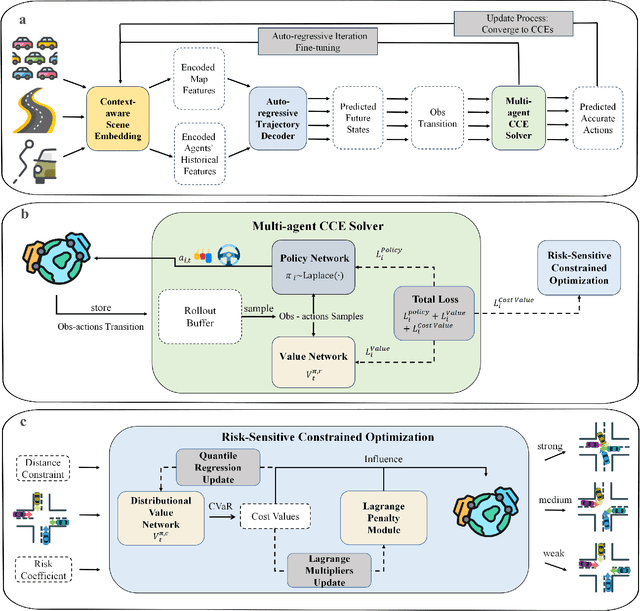
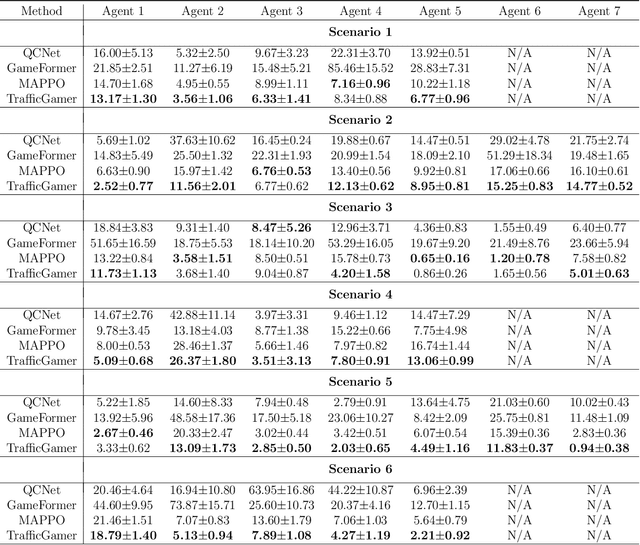
While modern Autonomous Vehicle (AV) systems can develop reliable driving policies under regular traffic conditions, they frequently struggle with safety-critical traffic scenarios. This difficulty primarily arises from the rarity of such scenarios in driving datasets and the complexities associated with predictive modeling among multiple vehicles. To support the testing and refinement of AV policies, simulating safety-critical traffic events is an essential challenge to be addressed. In this work, we introduce TrafficGamer, which facilitates game-theoretic traffic simulation by viewing common road driving as a multi-agent game. In evaluating the empirical performance across various real-world datasets, TrafficGamer ensures both fidelity and exploitability of the simulated scenarios, guaranteeing that they not only statically align with real-world traffic distribution but also efficiently capture equilibriums for representing safety-critical scenarios involving multiple agents. Additionally, the results demonstrate that TrafficGamer exhibits highly flexible simulation across various contexts. Specifically, we demonstrate that the generated scenarios can dynamically adapt to equilibriums of varying tightness by configuring risk-sensitive constraints during optimization. To the best of our knowledge, TrafficGamer is the first simulator capable of generating diverse traffic scenarios involving multiple agents. We have provided a demo webpage for the project at https://qiaoguanren.github.io/trafficgamer-demo/.