 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrafficGamer: Reliable and Flexible Traffic Simulation for Safety-Critical Scenarios with Game-Theoretic Oracles
Aug 28, 2024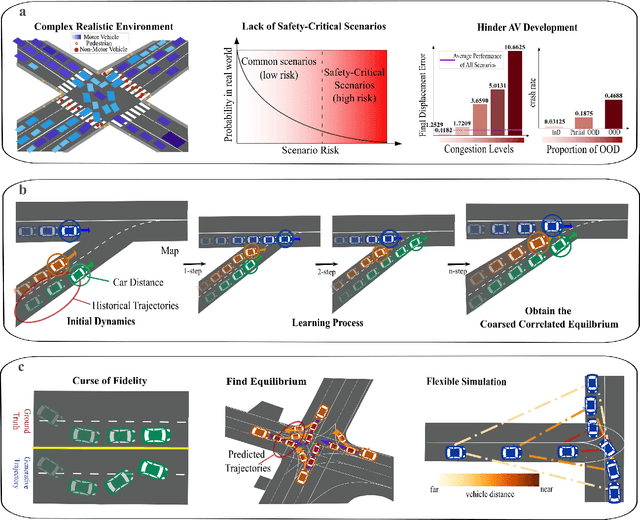
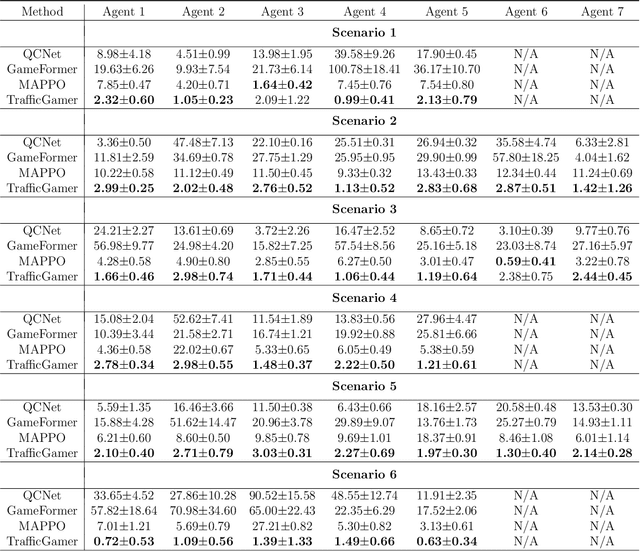
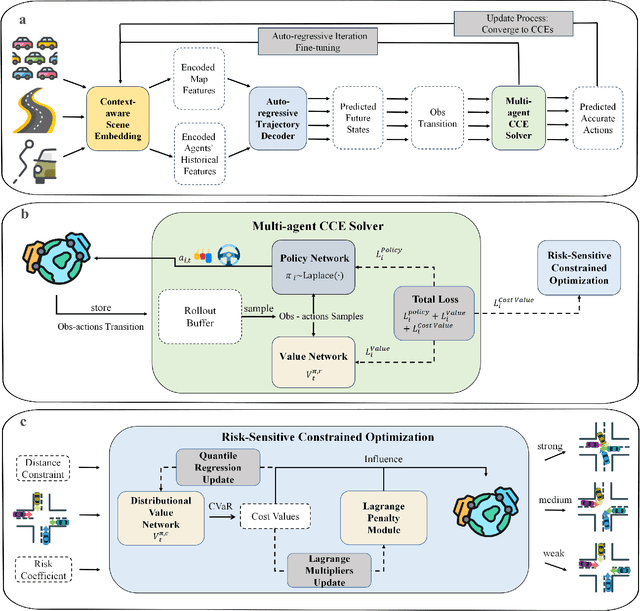
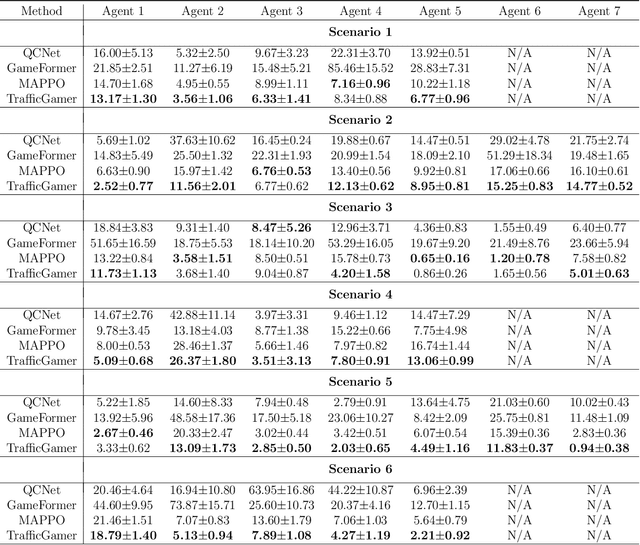
While modern Autonomous Vehicle (AV) systems can develop reliable driving policies under regular traffic conditions, they frequently struggle with safety-critical traffic scenarios. This difficulty primarily arises from the rarity of such scenarios in driving datasets and the complexities associated with predictive modeling among multiple vehicles. To support the testing and refinement of AV policies, simulating safety-critical traffic events is an essential challenge to be addressed. In this work, we introduce TrafficGamer, which facilitates game-theoretic traffic simulation by viewing common road driving as a multi-agent game. In evaluating the empirical performance across various real-world datasets, TrafficGamer ensures both fidelity and exploitability of the simulated scenarios, guaranteeing that they not only statically align with real-world traffic distribution but also efficiently capture equilibriums for representing safety-critical scenarios involving multiple agents. Additionally, the results demonstrate that TrafficGamer exhibits highly flexible simulation across various contexts. Specifically, we demonstrate that the generated scenarios can dynamically adapt to equilibriums of varying tightness by configuring risk-sensitive constraints during optimization. To the best of our knowledge, TrafficGamer is the first simulator capable of generating diverse traffic scenarios involving multiple agents. We have provided a demo webpage for the project at https://qiaoguanren.github.io/trafficgamer-demo/.
Open RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.