 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptPNP: Integrating Prehensile and Non-Prehensile Skills for Adaptive Robotic Manipulation
Nov 14, 2025Non-prehensile (NP) manipulation, in which robots alter object states without forming stable grasps (for example, pushing, poking, or sliding), significantly broadens robotic manipulation capabilities when grasping is infeasible or insufficient. However, enabling a unified framework that generalizes across different tasks, objects, and environments while seamlessly integrating non-prehensile and prehensile (P) actions remains challenging: robots must determine when to invoke NP skills, select the appropriate primitive for each context, and compose P and NP strategies into robust, multi-step plans. We introduce ApaptPNP, a vision-language model (VLM)-empowered task and motion planning framework that systematically selects and combines P and NP skills to accomplish diverse manipulation objectives. Our approach leverages a VLM to interpret visual scene observations and textual task descriptions, generating a high-level plan skeleton that prescribes the sequence and coordination of P and NP actions. A digital-twin based object-centric intermediate layer predicts desired object poses, enabling proactive mental rehearsal of manipulation sequences. Finally, a control module synthesizes low-level robot commands, with continuous execution feedback enabling online task plan refinement and adaptive replanning through the VLM. We evaluate ApaptPNP across representative P&NP hybrid manipulation tasks in both simulation and real-world environments. These results underscore the potential of hybrid P&NP manipulation as a crucial step toward general-purpose, human-level robotic manipulation capabilities. Project Website: https://sites.google.com/view/adaptpnp/home
Learning Generalizable Language-Conditioned Cloth Manipulation from Long Demonstrations
Mar 06, 2025Multi-step cloth manipulation is a challenging problem for robots due to the high-dimensional state spaces and the dynamics of cloth. Despite recent significant advances in end-to-end imitation learning for multi-step cloth manipulation skills, these methods fail to generalize to unseen tasks. Our insight in tackling the challenge of generalizable multi-step cloth manipulation is decomposition. We propose a novel pipeline that autonomously learns basic skills from long demonstrations and composes learned basic skills to generalize to unseen tasks. Specifically, our method first discovers and learns basic skills from the existing long demonstration benchmark with the commonsense knowledge of a large language model (LLM). Then, leveraging a high-level LLM-based task planner, these basic skills can be composed to complete unseen tasks. Experimental results demonstrate that our method outperforms baseline methods in learning multi-step cloth manipulation skills for both seen and unseen tasks.
MASQ: Multi-Agent Reinforcement Learning for Single Quadruped Robot Locomotion
Aug 25, 2024

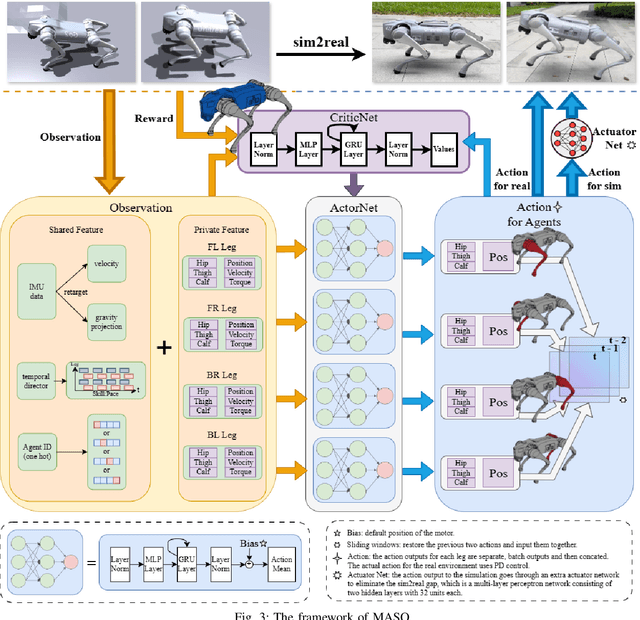
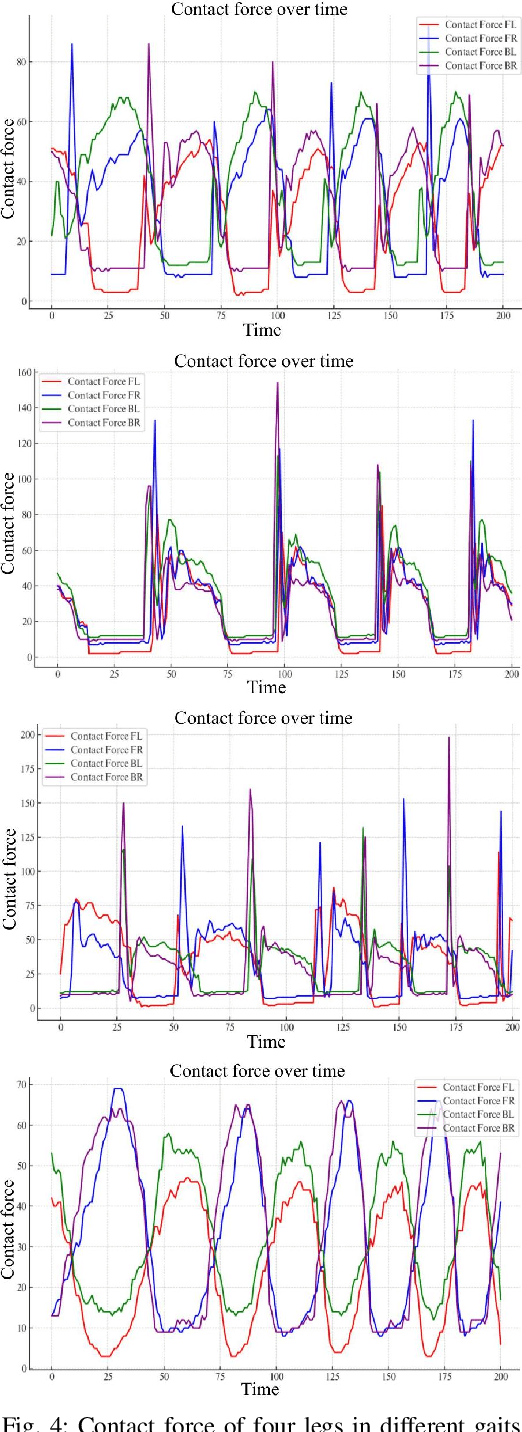
This paper proposes a novel method to improve locomotion learning for a single quadruped robot using multi-agent deep reinforcement learning (MARL). Many existing methods use single-agent reinforcement learning for an individual robot or MARL for the cooperative task in multi-robot systems. Unlike existing methods, this paper proposes using MARL for the locomotion learning of a single quadruped robot. We develop a learning structure called Multi-Agent Reinforcement Learning for Single Quadruped Robot Locomotion (MASQ), considering each leg as an agent to explore the action space of the quadruped robot, sharing a global critic, and learning collaboratively. Experimental results indicate that MASQ not only speeds up learning convergence but also enhances robustness in real-world settings, suggesting that applying MASQ to single robots such as quadrupeds could surpass traditional single-robot reinforcement learning approaches. Our study provides insightful guidance on integrating MARL with single-robot locomotion learning.
Co-Driven Recognition of Semantic Consistency via the Fusion of Transformer and HowNet Sememes Knowledge
Feb 21, 2023



Semantic consistency recognition aims to detect and judge whether the semantics of two text sentences are consistent with each other. However, the existing methods usually encounter the challenges of synonyms, polysemy and difficulty to understand long text. To solve the above problems, this paper proposes a co-driven semantic consistency recognition method based on the fusion of Transformer and HowNet sememes knowledge. Multi-level encoding of internal sentence structures via data-driven is carried out firstly by Transformer, sememes knowledge base HowNet is introduced for knowledge-driven to model the semantic knowledge association among sentence pairs. Then, interactive attention calculation is carried out utilizing soft-attention and fusion the knowledge with sememes matrix. Finally, bidirectional long short-term memory network (BiLSTM) is exploited to encode the conceptual semantic information and infer the semantic consistency. Experiments are conducted on two financial text matching datasets (BQ, AFQMC) and a cross-lingual adversarial dataset (PAWSX) for paraphrase identification. Compared with lightweight models including DSSM, MwAN, DRCN, and pre-training models such as ERNIE etc., the proposed model can not only improve the accuracy of semantic consistency recognition effectively (by 2.19%, 5.57% and 6.51% compared with the DSSM, MWAN and DRCN models on the BQ dataset), but also reduce the number of model parameters (to about 16M). In addition, driven by the HowNet sememes knowledge, the proposed method is promising to adapt to scenarios with long text.