 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generalizable Language-Conditioned Cloth Manipulation from Long Demonstrations
Mar 06, 2025Multi-step cloth manipulation is a challenging problem for robots due to the high-dimensional state spaces and the dynamics of cloth. Despite recent significant advances in end-to-end imitation learning for multi-step cloth manipulation skills, these methods fail to generalize to unseen tasks. Our insight in tackling the challenge of generalizable multi-step cloth manipulation is decomposition. We propose a novel pipeline that autonomously learns basic skills from long demonstrations and composes learned basic skills to generalize to unseen tasks. Specifically, our method first discovers and learns basic skills from the existing long demonstration benchmark with the commonsense knowledge of a large language model (LLM). Then, leveraging a high-level LLM-based task planner, these basic skills can be composed to complete unseen tasks. Experimental results demonstrate that our method outperforms baseline methods in learning multi-step cloth manipulation skills for both seen and unseen tasks.
FUNCTO: Function-Centric One-Shot Imitation Learning for Tool Manipulation
Feb 17, 2025



Learning tool use from a single human demonstration video offers a highly intuitive and efficient approach to robot teaching. While humans can effortlessly generalize a demonstrated tool manipulation skill to diverse tools that support the same function (e.g., pouring with a mug versus a teapot), current one-shot imitation learning (OSIL) methods struggle to achieve this. A key challenge lies in establishing functional correspondences between demonstration and test tools, considering significant geometric variations among tools with the same function (i.e., intra-function variations). To address this challenge, we propose FUNCTO (Function-Centric OSIL for Tool Manipulation), an OSIL method that establishes function-centric correspondences with a 3D functional keypoint representation, enabling robots to generalize tool manipulation skills from a single human demonstration video to novel tools with the same function despite significant intra-function variations. With this formulation, we factorize FUNCTO into three stages: (1) functional keypoint extraction, (2) function-centric correspondence establishment, and (3) functional keypoint-based action planning. We evaluate FUNCTO against exiting modular OSIL methods and end-to-end behavioral cloning methods through real-robot experiments on diverse tool manipulation tasks. The results demonstrate the superiority of FUNCTO when generalizing to novel tools with intra-function geometric variations. More details are available at https://sites.google.com/view/functo.
GSON: A Group-based Social Navigation Framework with Large Multimodal Model
Sep 26, 2024As the number of service robots and autonomous vehicles in human-centered environments grows, their requirements go beyond simply navigating to a destination. They must also take into account dynamic social contexts and ensure respect and comfort for others in shared spaces, which poses significant challenges for perception and planning. In this paper, we present a group-based social navigation framework GSON to enable mobile robots to perceive and exploit the social group of their surroundings by leveling the visual reasoning capability of the Large Multimodal Model (LMM). For perception, we apply visual prompting techniques to zero-shot extract the social relationship among pedestrians and combine the result with a robust pedestrian detection and tracking pipeline to alleviate the problem of low inference speed of the LMM. Given the perception result, the planning system is designed to avoid disrupting the current social structure. We adopt a social structure-based mid-level planner as a bridge between global path planning and local motion planning to preserve the global context and reactive response. The proposed method is validated on real-world mobile robot navigation tasks involving complex social structure understanding and reasoning. Experimental results demonstrate the effectiveness of the system in these scenarios compared with several baselines.
General-purpose Clothes Manipulation with Semantic Keypoints
Aug 15, 2024We have seen much recent progress in task-specific clothes manipulation, but generalizable clothes manipulation is still a challenge. Clothes manipulation requires sequential actions, making it challenging to generalize to unseen tasks. Besides, a general clothes state representation method is crucial. In this paper, we adopt language instructions to specify and decompose clothes manipulation tasks, and propose a large language model based hierarchical learning method to enhance generalization. For state representation, we use semantic keypoints to capture the geometry of clothes and outline their manipulation methods. Simulation experiments show that the proposed method outperforms the baseline method in terms of success rate and generalization for clothes manipulation tasks.
Learning visual-based deformable object rearrangement with local graph neural networks
Oct 16, 2023Goal-conditioned rearrangement of deformable objects (e.g. straightening a rope and folding a cloth) is one of the most common deformable manipulation tasks, where the robot needs to rearrange a deformable object into a prescribed goal configuration with only visual observations. These tasks are typically confronted with two main challenges: the high dimensionality of deformable configuration space and the underlying complexity, nonlinearity and uncertainty inherent in deformable dynamics. To address these challenges, we propose a novel representation strategy that can efficiently model the deformable object states with a set of keypoints and their interactions. We further propose local-graph neural network (GNN), a light local GNN learning to jointly model the deformable rearrangement dynamics and infer the optimal manipulation actions (e.g. pick and place) by constructing and updating two dynamic graphs. Both simulated and real experiments have been conducted to demonstrate that the proposed dynamic graph representation shows superior expressiveness in modeling deformable rearrangement dynamics. Our method reaches much higher success rates on a variety of deformable rearrangement tasks (96.3% on average) than state-of-the-art method in simulation experiments. Besides, our method is much more lighter and has a 60% shorter inference time than state-of-the-art methods. We also demonstrate that our method performs well in the multi-task learning scenario and can be transferred to real-world applications with an average success rate of 95% by solely fine tuning a keypoint detector.
Learning Language-Conditioned Deformable Object Manipulation with Graph Dynamics
Mar 02, 2023



Vision-based deformable object manipulation is a challenging problem in robotic manipulation, requiring a robot to infer a sequence of manipulation actions leading to the desired state from solely visual observations. Most previous works address this problem in a goal-conditioned way and adapt the goal image to specify a task, which is not practical or efficient. Thus, we adapted natural language specification and proposed a language-conditioned deformable object manipulation policy learning framework. We first design a unified Transformer-based architecture to understand multi-modal data and output picking and placing action. Besides, we have introduced the visible connectivity graph to tackle nonlinear dynamics and complex configuration of the deformable object in the manipulation process. Both simulated and real experiments have demonstrated that the proposed method is general and effective in language-conditioned deformable object manipulation policy learning. Our method achieves much higher success rates on various language-conditioned deformable object manipulation tasks (87.3% on average) than the state-of-the-art method in simulation experiments. Besides, our method is much lighter and has a 75.6% shorter inference time than state-of-the-art methods. We also demonstrate that our method performs well in real-world applications. Supplementary videos can be found at https://sites.google.com/view/language-deformable.
Deep Reinforcement Learning Based on Local GNN for Goal-conditioned Deformable Object Rearranging
Feb 21, 2023



Object rearranging is one of the most common deformable manipulation tasks, where the robot needs to rearrange a deformable object into a goal configuration. Previous studies focus on designing an expert system for each specific task by model-based or data-driven approaches and the application scenarios are therefore limited. Some research has been attempting to design a general framework to obtain more advanced manipulation capabilities for deformable rearranging tasks, with lots of progress achieved in simulation. However, transferring from simulation to reality is difficult due to the limitation of the end-to-end CNN architecture. To address these challenges, we design a local GNN (Graph Neural Network) based learning method, which utilizes two representation graphs to encode keypoints detected from images. Self-attention is applied for graph updating and cross-attention is applied for generating manipulation actions. Extensive experiments have been conducted to demonstrate that our framework is effective in multiple 1-D (rope, rope ring) and 2-D (cloth) rearranging tasks in simulation and can be easily transferred to a real robot by fine-tuning a keypoint detector.
* has been accepted by IEEE/RSJ International Conference on Intelligent Robots and Systems 2022
Deep Reinforcement Learning for Robotic Pushing and Picking in Cluttered Environment
Feb 21, 2023



In this paper, a novel robotic grasping system is established to automatically pick up objects in cluttered scenes. A composite robotic hand composed of a suction cup and a gripper is designed for grasping the object stably. The suction cup is used for lifting the object from the clutter first and the gripper for grasping the object accordingly. We utilize the affordance map to provide pixel-wise lifting point candidates for the suction cup. To obtain a good affordance map, the active exploration mechanism is introduced to the system. An effective metric is designed to calculate the reward for the current affordance map, and a deep Q-Network (DQN) is employed to guide the robotic hand to actively explore the environment until the generated affordance map is suitable for grasping. Experimental results have demonstrated that the proposed robotic grasping system is able to greatly increase the success rate of the robotic grasping in cluttered scenes.
* has been accepted by IEEE/RSJ International Conference on Intelligent Robots and Systems 2019
Graph-Transporter: A Graph-based Learning Method for Goal-Conditioned Deformable Object Rearranging Task
Feb 21, 2023
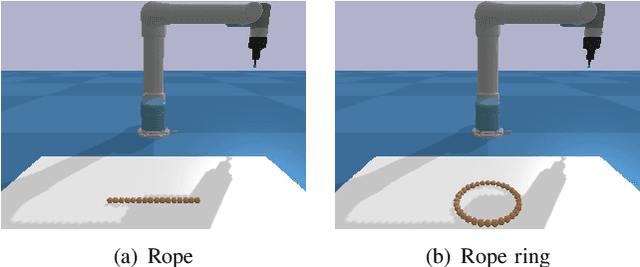
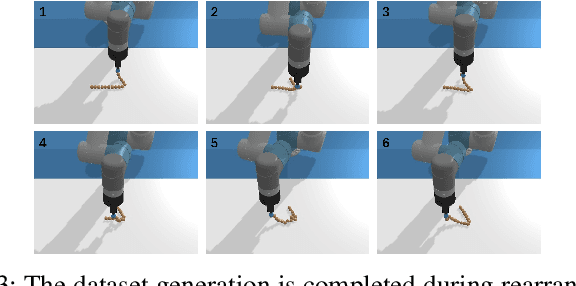
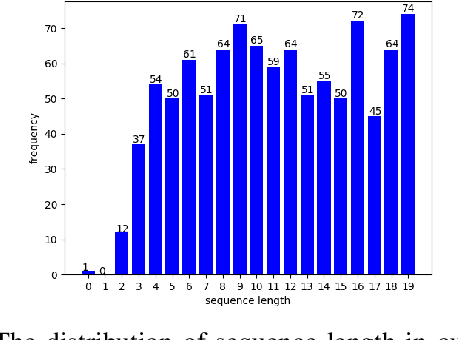
Rearranging deformable objects is a long-standing challenge in robotic manipulation for the high dimensionality of configuration space and the complex dynamics of deformable objects. We present a novel framework, Graph-Transporter, for goal-conditioned deformable object rearranging tasks. To tackle the challenge of complex configuration space and dynamics, we represent the configuration space of a deformable object with a graph structure and the graph features are encoded by a graph convolution network. Our framework adopts an architecture based on Fully Convolutional Network (FCN) to output pixel-wise pick-and-place actions from only visual input. Extensive experiments have been conducted to validate the effectiveness of the graph representation of deformable object configuration. The experimental results also demonstrate that our framework is effective and general in handling goal-conditioned deformable object rearranging tasks.
* has been accepted by IEEE International Conference on Systems, Man and Cybernetics 2022
Foldsformer: Learning Sequential Multi-Step Cloth Manipulation With Space-Time Attention
Jan 08, 2023



Sequential multi-step cloth manipulation is a challenging problem in robotic manipulation, requiring a robot to perceive the cloth state and plan a sequence of chained actions leading to the desired state. Most previous works address this problem in a goal-conditioned way, and goal observation must be given for each specific task and cloth configuration, which is not practical and efficient. Thus, we present a novel multi-step cloth manipulation planning framework named Foldformer. Foldformer can complete similar tasks with only a general demonstration and utilize a space-time attention mechanism to capture the instruction information behind this demonstration. We experimentally evaluate Foldsformer on four representative sequential multi-step manipulation tasks and show that Foldsformer significantly outperforms state-of-the-art approaches in simulation. Foldformer can complete multi-step cloth manipulation tasks even when configurations of the cloth (e.g., size and pose) vary from configurations in the general demonstrations. Furthermore, our approach can be transferred from simulation to the real world without additional training or domain randomization. Despite training on rectangular clothes, we also show that our approach can generalize to unseen cloth shapes (T-shirts and shorts). Videos and source code are available at: https://sites.google.com/view/foldsformer.
* 8 pages, 6 figures, published to IEEE Robotics & Automation Letters (RA-L)