 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Generalizable Language-Conditioned Cloth Manipulation from Long Demonstrations
Mar 06, 2025Multi-step cloth manipulation is a challenging problem for robots due to the high-dimensional state spaces and the dynamics of cloth. Despite recent significant advances in end-to-end imitation learning for multi-step cloth manipulation skills, these methods fail to generalize to unseen tasks. Our insight in tackling the challenge of generalizable multi-step cloth manipulation is decomposition. We propose a novel pipeline that autonomously learns basic skills from long demonstrations and composes learned basic skills to generalize to unseen tasks. Specifically, our method first discovers and learns basic skills from the existing long demonstration benchmark with the commonsense knowledge of a large language model (LLM). Then, leveraging a high-level LLM-based task planner, these basic skills can be composed to complete unseen tasks. Experimental results demonstrate that our method outperforms baseline methods in learning multi-step cloth manipulation skills for both seen and unseen tasks.
Interaction-Driven Active 3D Reconstruction with Object Interiors
Oct 23, 2023We introduce an active 3D reconstruction method which integrates visual perception, robot-object interaction, and 3D scanning to recover both the exterior and interior, i.e., unexposed, geometries of a target 3D object. Unlike other works in active vision which focus on optimizing camera viewpoints to better investigate the environment, the primary feature of our reconstruction is an analysis of the interactability of various parts of the target object and the ensuing part manipulation by a robot to enable scanning of occluded regions. As a result, an understanding of part articulations of the target object is obtained on top of complete geometry acquisition. Our method operates fully automatically by a Fetch robot with built-in RGBD sensors. It iterates between interaction analysis and interaction-driven reconstruction, scanning and reconstructing detected moveable parts one at a time, where both the articulated part detection and mesh reconstruction are carried out by neural networks. In the final step, all the remaining, non-articulated parts, including all the interior structures that had been exposed by prior part manipulations and subsequently scanned, are reconstructed to complete the acquisition. We demonstrate the performance of our method via qualitative and quantitative evaluation, ablation studies, comparisons to alternatives, as well as experiments in a real environment.
Consistent Two-Flow Network for Tele-Registration of Point Clouds
Jun 01, 2021



Rigid registration of partial observations is a fundamental problem in various applied fields. In computer graphics, special attention has been given to the registration between two partial point clouds generated by scanning devices. State-of-the-art registration techniques still struggle when the overlap region between the two point clouds is small, and completely fail if there is no overlap between the scan pairs. In this paper, we present a learning-based technique that alleviates this problem, and allows registration between point clouds, presented in arbitrary poses, and having little or even no overlap, a setting that has been referred to as tele-registration. Our technique is based on a novel neural network design that learns a prior of a class of shapes and can complete a partial shape. The key idea is combining the registration and completion tasks in a way that reinforces each other. In particular, we simultaneously train the registration network and completion network using two coupled flows, one that register-and-complete, and one that complete-and-register, and encourage the two flows to produce a consistent result. We show that, compared with each separate flow, this two-flow training leads to robust and reliable tele-registration, and hence to a better point cloud prediction that completes the registered scans. It is also worth mentioning that each of the components in our neural network outperforms state-of-the-art methods in both completion and registration. We further analyze our network with several ablation studies and demonstrate its performance on a large number of partial point clouds, both synthetic and real-world, that have only small or no overlap.
Predictive and Generative Neural Networks for Object Functionality
Jun 28, 2020

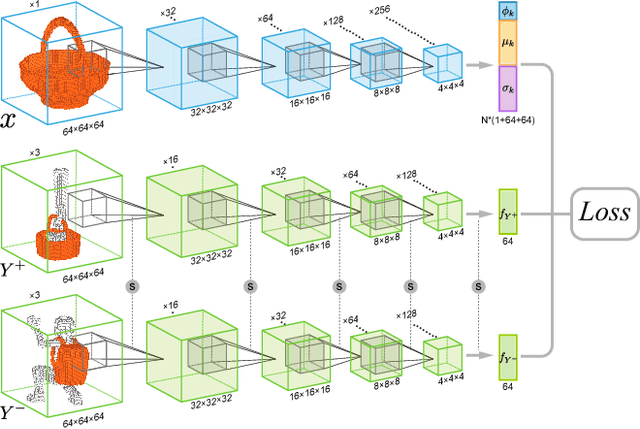
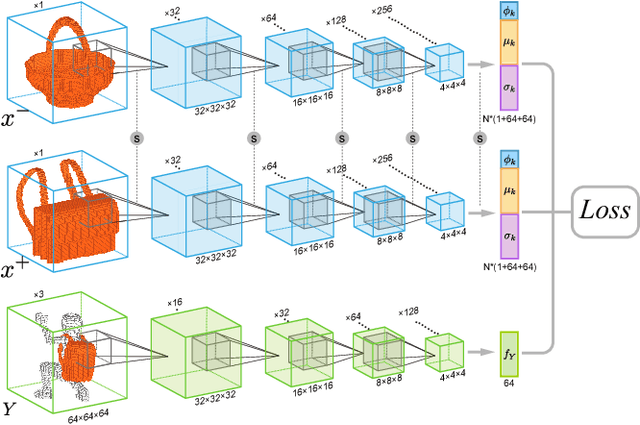
Humans can predict the functionality of an object even without any surroundings, since their knowledge and experience would allow them to "hallucinate" the interaction or usage scenarios involving the object. We develop predictive and generative deep convolutional neural networks to replicate this feat. Specifically, our work focuses on functionalities of man-made 3D objects characterized by human-object or object-object interactions. Our networks are trained on a database of scene contexts, called interaction contexts, each consisting of a central object and one or more surrounding objects, that represent object functionalities. Given a 3D object in isolation, our functional similarity network (fSIM-NET), a variation of the triplet network, is trained to predict the functionality of the object by inferring functionality-revealing interaction contexts. fSIM-NET is complemented by a generative network (iGEN-NET) and a segmentation network (iSEG-NET). iGEN-NET takes a single voxelized 3D object with a functionality label and synthesizes a voxelized surround, i.e., the interaction context which visually demonstrates the corresponding functionality. iSEG-NET further separates the interacting objects into different groups according to their interaction types.
* Accepted to SIGGRAPH 2018, project page at https://vcc.tech/research/2018/ICON4
RPM-Net: Recurrent Prediction of Motion and Parts from Point Cloud
Jun 26, 2020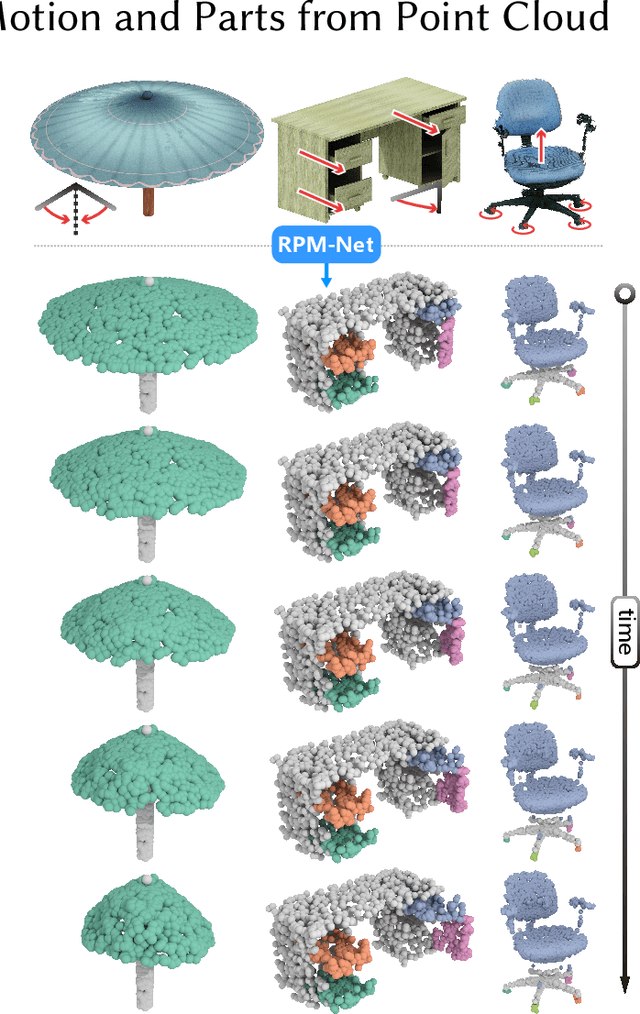
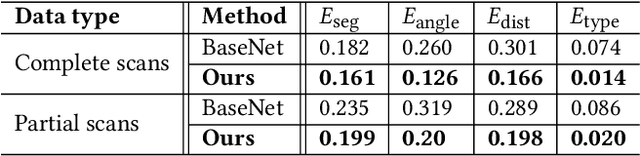
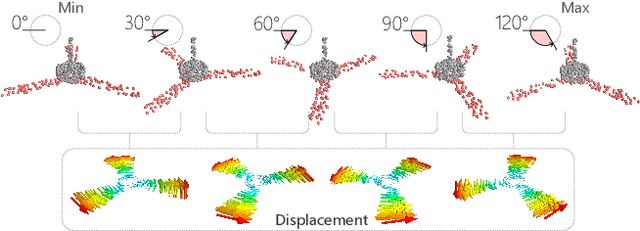
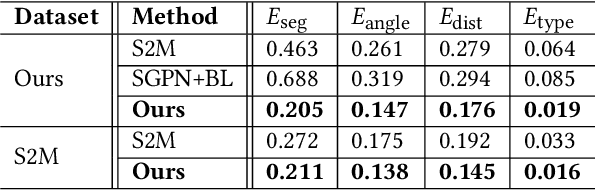
We introduce RPM-Net, a deep learning-based approach which simultaneously infers movable parts and hallucinates their motions from a single, un-segmented, and possibly partial, 3D point cloud shape. RPM-Net is a novel Recurrent Neural Network (RNN), composed of an encoder-decoder pair with interleaved Long Short-Term Memory (LSTM) components, which together predict a temporal sequence of pointwise displacements for the input point cloud. At the same time, the displacements allow the network to learn movable parts, resulting in a motion-based shape segmentation. Recursive applications of RPM-Net on the obtained parts can predict finer-level part motions, resulting in a hierarchical object segmentation. Furthermore, we develop a separate network to estimate part mobilities, e.g., per-part motion parameters, from the segmented motion sequence. Both networks learn deep predictive models from a training set that exemplifies a variety of mobilities for diverse objects. We show results of simultaneous motion and part predictions from synthetic and real scans of 3D objects exhibiting a variety of part mobilities, possibly involving multiple movable parts.
* Accepted to SIGGRAPH Asia 2019, project page at https://vcc.tech/research/2019/RPMNet