 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshTailor: Cutting Seams via Generative Mesh Traversal
Mar 28, 2026We present MeshTailor, the first mesh-native generative framework for synthesizing edge-aligned seams on 3D surfaces. Unlike prior optimization-based or extrinsic learning-based methods, MeshTailor operates directly on the mesh graph, eliminating projection artifacts and fragile snapping heuristics. We introduce ChainingSeams, a hierarchical serialization of the seam graph that prioritizes global structural cuts before local details in a coarse-to-fine manner, and a dual-stream encoder that fuses topological and geometric context. Leveraging this hierarchical representation and enriched vertex embeddings, our MeshTailor Transformer utilizes an autoregressive pointer layer to trace seams vertex-by-vertex within local neighborhoods, ensuring projection-free, edge-aligned seams. Extensive evaluations show that MeshTailor produces more coherent, professional-quality seam layouts compared to recent optimization-based and learning-based baselines.
An Object is Worth 64x64 Pixels: Generating 3D Object via Image Diffusion
Aug 06, 2024



We introduce a new approach for generating realistic 3D models with UV maps through a representation termed "Object Images." This approach encapsulates surface geometry, appearance, and patch structures within a 64x64 pixel image, effectively converting complex 3D shapes into a more manageable 2D format. By doing so, we address the challenges of both geometric and semantic irregularity inherent in polygonal meshes. This method allows us to use image generation models, such as Diffusion Transformers, directly for 3D shape generation. Evaluated on the ABO dataset, our generated shapes with patch structures achieve point cloud FID comparable to recent 3D generative models, while naturally supporting PBR material generation.
CC3D: Layout-Conditioned Generation of Compositional 3D Scenes
Mar 21, 2023


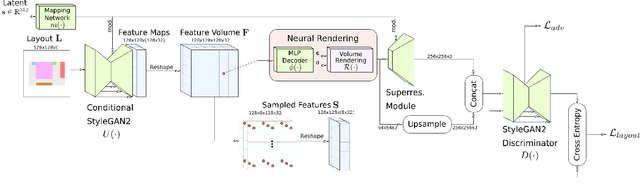
In this work, we introduce CC3D, a conditional generative model that synthesizes complex 3D scenes conditioned on 2D semantic scene layouts, trained using single-view images. Different from most existing 3D GANs that limit their applicability to aligned single objects, we focus on generating complex scenes with multiple objects, by modeling the compositional nature of 3D scenes. By devising a 2D layout-based approach for 3D synthesis and implementing a new 3D field representation with a stronger geometric inductive bias, we have created a 3D GAN that is both efficient and of high quality, while allowing for a more controllable generation process. Our evaluations on synthetic 3D-FRONT and real-world KITTI-360 datasets demonstrate that our model generates scenes of improved visual and geometric quality in comparison to previous works.
ShapeFormer: Transformer-based Shape Completion via Sparse Representation
Jan 25, 2022
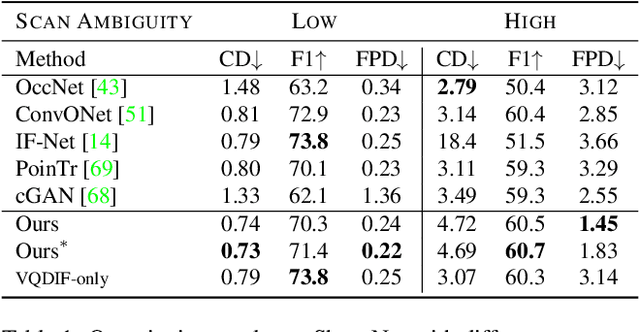
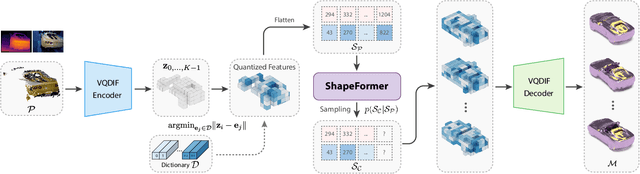
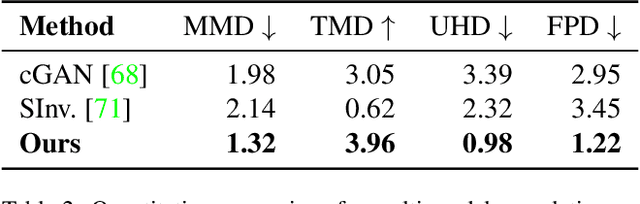
We present ShapeFormer, a transformer-based network that produces a distribution of object completions, conditioned on incomplete, and possibly noisy, point clouds. The resultant distribution can then be sampled to generate likely completions, each exhibiting plausible shape details while being faithful to the input. To facilitate the use of transformers for 3D, we introduce a compact 3D representation, vector quantized deep implicit function, that utilizes spatial sparsity to represent a close approximation of a 3D shape by a short sequence of discrete variables. Experiments demonstrate that ShapeFormer outperforms prior art for shape completion from ambiguous partial inputs in terms of both completion quality and diversity. We also show that our approach effectively handles a variety of shape types, incomplete patterns, and real-world scans.
RPM-Net: Recurrent Prediction of Motion and Parts from Point Cloud
Jun 26, 2020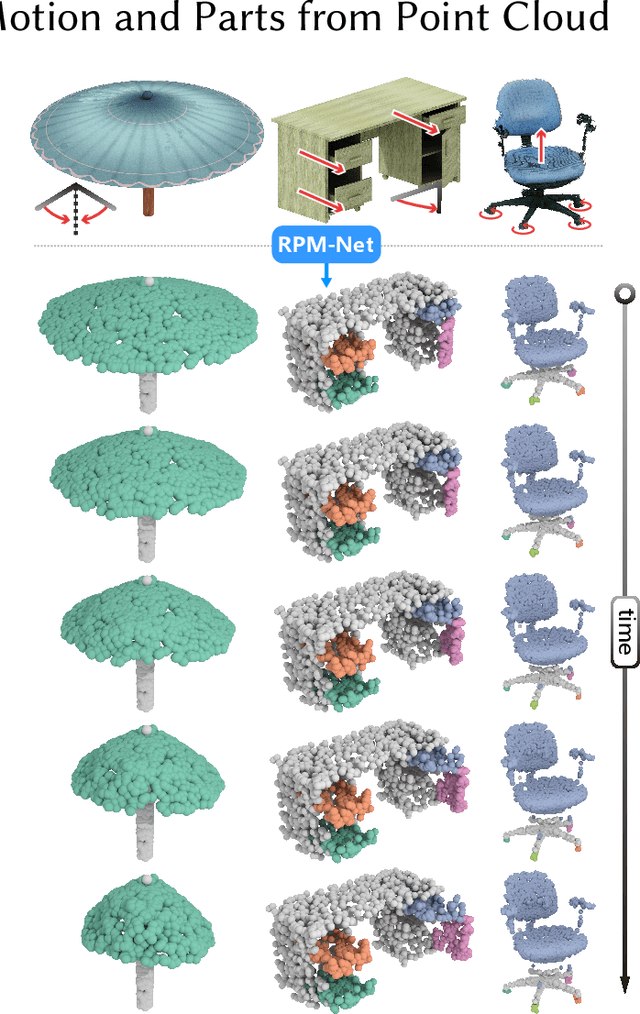
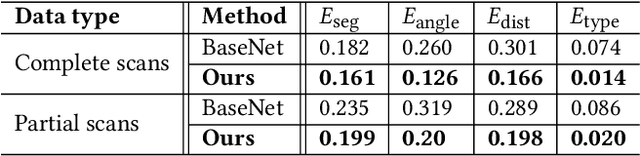
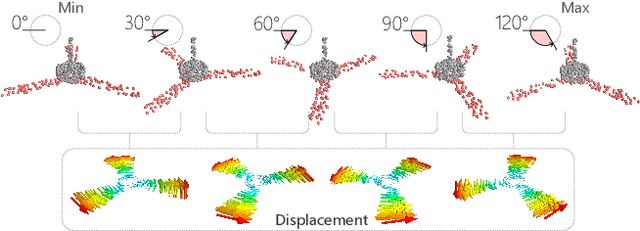
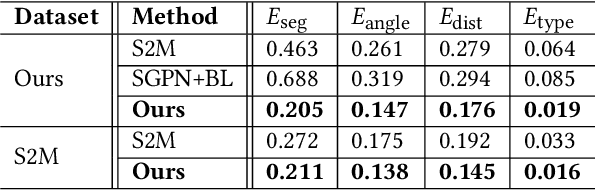
We introduce RPM-Net, a deep learning-based approach which simultaneously infers movable parts and hallucinates their motions from a single, un-segmented, and possibly partial, 3D point cloud shape. RPM-Net is a novel Recurrent Neural Network (RNN), composed of an encoder-decoder pair with interleaved Long Short-Term Memory (LSTM) components, which together predict a temporal sequence of pointwise displacements for the input point cloud. At the same time, the displacements allow the network to learn movable parts, resulting in a motion-based shape segmentation. Recursive applications of RPM-Net on the obtained parts can predict finer-level part motions, resulting in a hierarchical object segmentation. Furthermore, we develop a separate network to estimate part mobilities, e.g., per-part motion parameters, from the segmented motion sequence. Both networks learn deep predictive models from a training set that exemplifies a variety of mobilities for diverse objects. We show results of simultaneous motion and part predictions from synthetic and real scans of 3D objects exhibiting a variety of part mobilities, possibly involving multiple movable parts.
* Accepted to SIGGRAPH Asia 2019, project page at https://vcc.tech/research/2019/RPMNet
Transductive Zero-Shot Learning with Visual Structure Constraint
Jan 06, 2019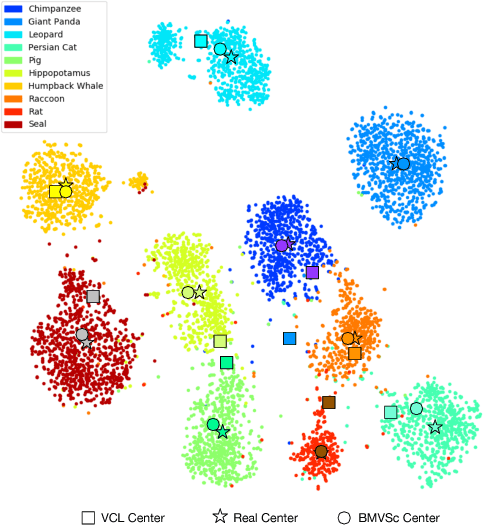
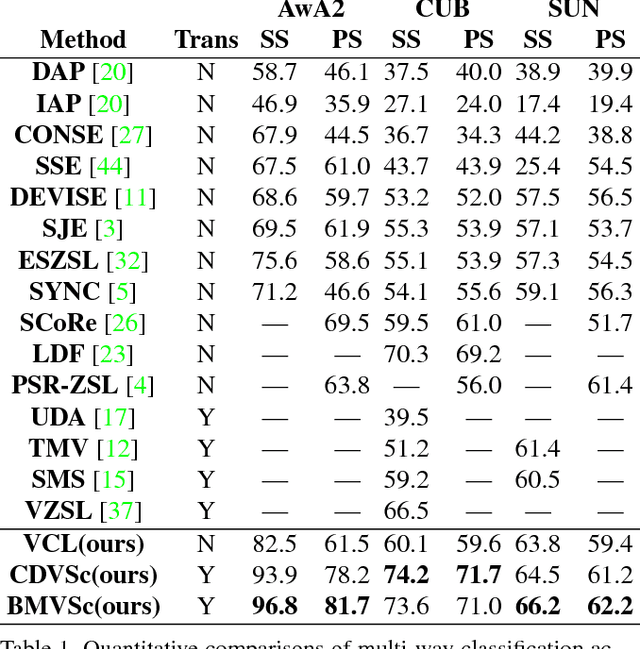
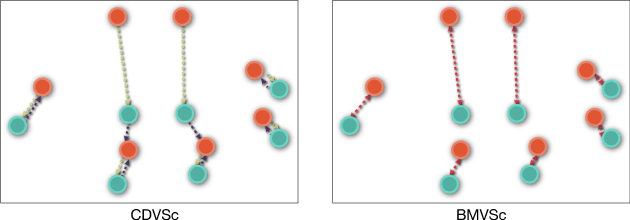
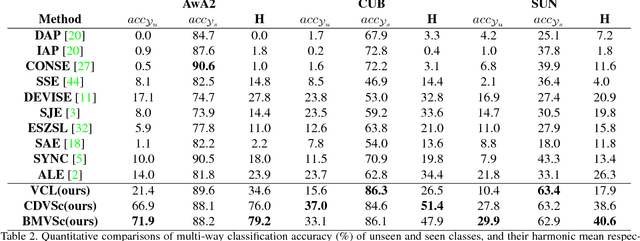
Zero-shot Learning (ZSL) aims to recognize objects of the unseen classes, whose instances may not have been seen during training. It associates seen and unseen classes with the common semantic space and provides the visual features for each data instance. Most existing methods first learn a compatible projection function between the semantic space and the visual space based on the data of source seen classes, then directly apply it to target unseen classes. However, in real scenarios, the data distribution between the source and target domain might not match well, thus causing the well-known domain shift problem. Based on the observation that visual features of test instances can be separated into different clusters, we propose a visual structure constraint on class centers for transductive ZSL, to improve the generality of the projection function (i.e. alleviate the above domain shift problem). Specifically, two different strategies (symmetric Chamfer-distance and bipartite matching) are adopted to align the projected unseen semantic centers and visual cluster centers of test instances. Experiments on three widely used datasets demonstrate that the proposed visual structure constraint can bring substantial performance gain consistently and achieve state-of-the-art results.