 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNuiWorld: Exploring a Scalable Framework for End-to-End Controllable World Generation
Jan 27, 2026World generation is a fundamental capability for applications like video games, simulation, and robotics. However, existing approaches face three main obstacles: controllability, scalability, and efficiency. End-to-end scene generation models have been limited by data scarcity. While object-centric generation approaches rely on fixed resolution representations, degrading fidelity for larger scenes. Training-free approaches, while flexible, are often slow and computationally expensive at inference time. We present NuiWorld, a framework that attempts to address these challenges. To overcome data scarcity, we propose a generative bootstrapping strategy that starts from a few input images. Leveraging recent 3D reconstruction and expandable scene generation techniques, we synthesize scenes of varying sizes and layouts, producing enough data to train an end-to-end model. Furthermore, our framework enables controllability through pseudo sketch labels, and demonstrates a degree of generalization to previously unseen sketches. Our approach represents scenes as a collection of variable scene chunks, which are compressed into a flattened vector-set representation. This significantly reduces the token length for large scenes, enabling consistent geometric fidelity across scenes sizes while improving training and inference efficiency.
NuiScene: Exploring Efficient Generation of Unbounded Outdoor Scenes
Mar 20, 2025
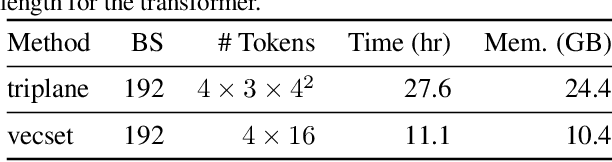
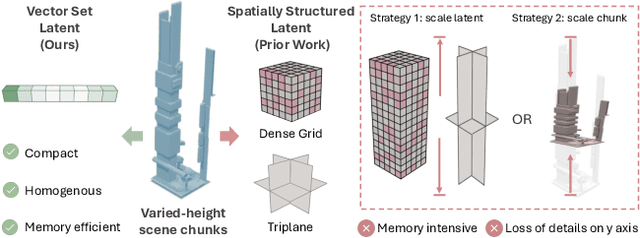
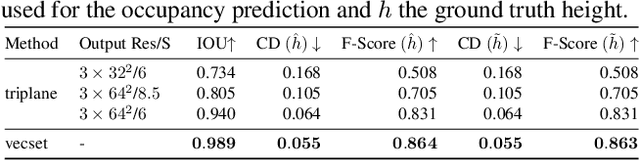
In this paper, we explore the task of generating expansive outdoor scenes, ranging from castles to high-rises. Unlike indoor scene generation, which has been a primary focus of prior work, outdoor scene generation presents unique challenges, including wide variations in scene heights and the need for a method capable of rapidly producing large landscapes. To address this, we propose an efficient approach that encodes scene chunks as uniform vector sets, offering better compression and performance than the spatially structured latents used in prior methods. Furthermore, we train an explicit outpainting model for unbounded generation, which improves coherence compared to prior resampling-based inpainting schemes while also speeding up generation by eliminating extra diffusion steps. To facilitate this task, we curate NuiScene43, a small but high-quality set of scenes, preprocessed for joint training. Notably, when trained on scenes of varying styles, our model can blend different environments, such as rural houses and city skyscrapers, within the same scene, highlighting the potential of our curation process to leverage heterogeneous scenes for joint training.
An Object is Worth 64x64 Pixels: Generating 3D Object via Image Diffusion
Aug 06, 2024



We introduce a new approach for generating realistic 3D models with UV maps through a representation termed "Object Images." This approach encapsulates surface geometry, appearance, and patch structures within a 64x64 pixel image, effectively converting complex 3D shapes into a more manageable 2D format. By doing so, we address the challenges of both geometric and semantic irregularity inherent in polygonal meshes. This method allows us to use image generation models, such as Diffusion Transformers, directly for 3D shape generation. Evaluated on the ABO dataset, our generated shapes with patch structures achieve point cloud FID comparable to recent 3D generative models, while naturally supporting PBR material generation.
Duoduo CLIP: Efficient 3D Understanding with Multi-View Images
Jun 17, 2024We introduce Duoduo CLIP, a model for 3D representation learning that learns shape encodings from multi-view images instead of point-clouds. The choice of multi-view images allows us to leverage 2D priors from off-the-shelf CLIP models to facilitate fine-tuning with 3D data. Our approach not only shows better generalization compared to existing point cloud methods, but also reduces GPU requirements and training time. In addition, we modify the model with cross-view attention to leverage information across multiple frames of the object which further boosts performance. Compared to the current SOTA point cloud method that requires 480 A100 hours to train 1 billion model parameters we only require 57 A5000 hours and 87 million parameters. Multi-view images also provide more flexibility in use cases compared to point clouds. This includes being able to encode objects with a variable number of images, with better performance when more views are used. This is in contrast to point cloud based methods, where an entire scan or model of an object is required. We showcase this flexibility with object retrieval from images of real-world objects. Our model also achieves better performance in more fine-grained text to shape retrieval, demonstrating better text-and-shape alignment than point cloud based models.
Text-to-3D Shape Generation
Mar 20, 2024Recent years have seen an explosion of work and interest in text-to-3D shape generation. Much of the progress is driven by advances in 3D representations, large-scale pretraining and representation learning for text and image data enabling generative AI models, and differentiable rendering. Computational systems that can perform text-to-3D shape generation have captivated the popular imagination as they enable non-expert users to easily create 3D content directly from text. However, there are still many limitations and challenges remaining in this problem space. In this state-of-the-art report, we provide a survey of the underlying technology and methods enabling text-to-3D shape generation to summarize the background literature. We then derive a systematic categorization of recent work on text-to-3D shape generation based on the type of supervision data required. Finally, we discuss limitations of the existing categories of methods, and delineate promising directions for future work.
Understanding Pure CLIP Guidance for Voxel Grid NeRF Models
Sep 30, 2022
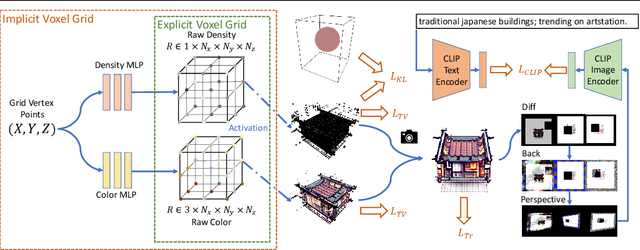
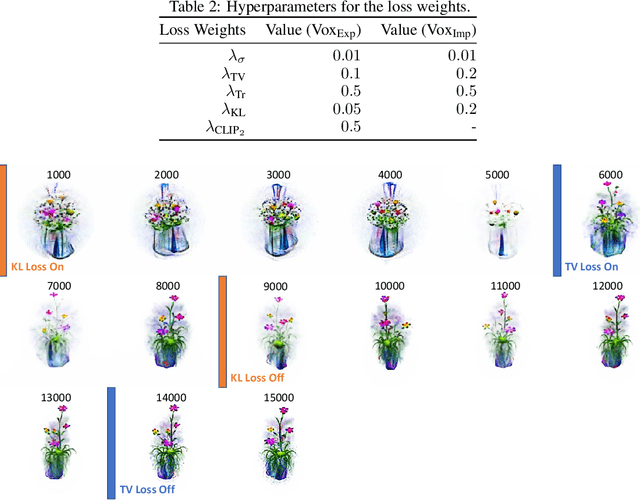
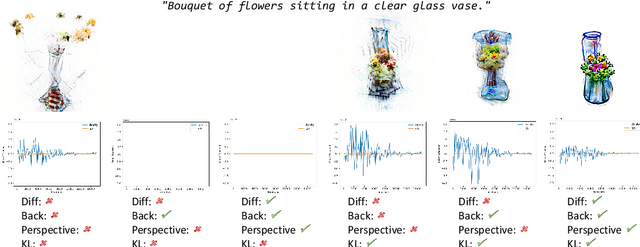
We explore the task of text to 3D object generation using CLIP. Specifically, we use CLIP for guidance without access to any datasets, a setting we refer to as pure CLIP guidance. While prior work has adopted this setting, there is no systematic study of mechanics for preventing adversarial generations within CLIP. We illustrate how different image-based augmentations prevent the adversarial generation problem, and how the generated results are impacted. We test different CLIP model architectures and show that ensembling different models for guidance can prevent adversarial generations within bigger models and generate sharper results. Furthermore, we implement an implicit voxel grid model to show how neural networks provide an additional layer of regularization, resulting in better geometrical structure and coherency of generated objects. Compared to prior work, we achieve more coherent results with higher memory efficiency and faster training speeds.
TriCoLo: Trimodal Contrastive Loss for Fine-grained Text to Shape Retrieval
Jan 19, 2022Recent work on contrastive losses for learning joint embeddings over multimodal data has been successful at downstream tasks such as retrieval and classification. On the other hand, work on joint representation learning for 3D shapes and text has thus far mostly focused on improving embeddings through modeling of complex attention between representations , or multi-task learning . We show that with large batch contrastive learning we achieve SoTA on text-shape retrieval without complex attention mechanisms or losses. Prior work in 3D and text representations has also focused on bimodal representation learning using either voxels or multi-view images with text. To this end, we propose a trimodal learning scheme to achieve even higher performance and better representations for all modalities.