 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNuiScene: Exploring Efficient Generation of Unbounded Outdoor Scenes
Mar 20, 2025
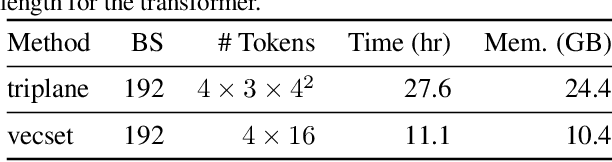
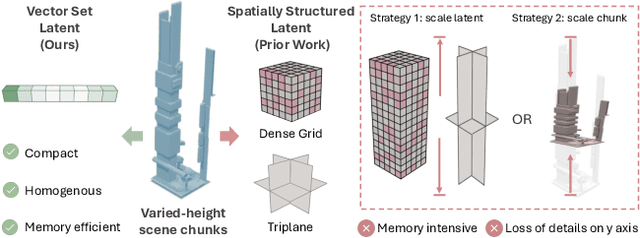
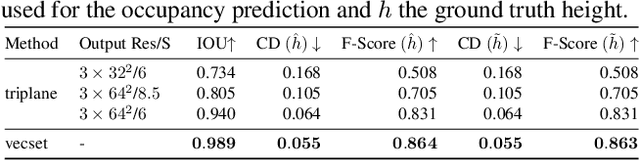
In this paper, we explore the task of generating expansive outdoor scenes, ranging from castles to high-rises. Unlike indoor scene generation, which has been a primary focus of prior work, outdoor scene generation presents unique challenges, including wide variations in scene heights and the need for a method capable of rapidly producing large landscapes. To address this, we propose an efficient approach that encodes scene chunks as uniform vector sets, offering better compression and performance than the spatially structured latents used in prior methods. Furthermore, we train an explicit outpainting model for unbounded generation, which improves coherence compared to prior resampling-based inpainting schemes while also speeding up generation by eliminating extra diffusion steps. To facilitate this task, we curate NuiScene43, a small but high-quality set of scenes, preprocessed for joint training. Notably, when trained on scenes of varying styles, our model can blend different environments, such as rural houses and city skyscrapers, within the same scene, highlighting the potential of our curation process to leverage heterogeneous scenes for joint training.
ConRPG: Paraphrase Generation using Contexts as Regularizer
Sep 01, 2021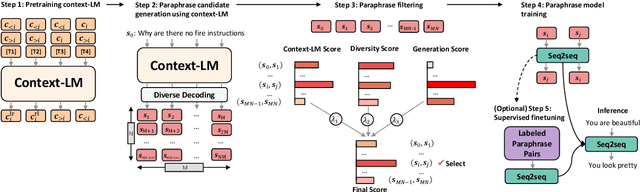

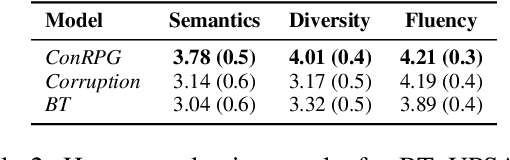
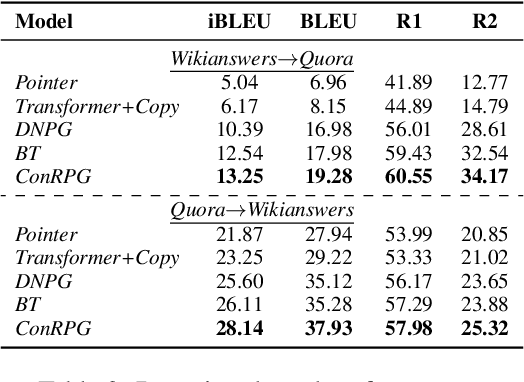
A long-standing issue with paraphrase generation is how to obtain reliable supervision signals. In this paper, we propose an unsupervised paradigm for paraphrase generation based on the assumption that the probabilities of generating two sentences with the same meaning given the same context should be the same. Inspired by this fundamental idea, we propose a pipelined system which consists of paraphrase candidate generation based on contextual language models, candidate filtering using scoring functions, and paraphrase model training based on the selected candidates. The proposed paradigm offers merits over existing paraphrase generation methods: (1) using the context regularizer on meanings, the model is able to generate massive amounts of high-quality paraphrase pairs; and (2) using human-interpretable scoring functions to select paraphrase pairs from candidates, the proposed framework provides a channel for developers to intervene with the data generation process, leading to a more controllable model. Experimental results across different tasks and datasets demonstrate that the effectiveness of the proposed model in both supervised and unsupervised setups.
BertGCN: Transductive Text Classification by Combining GCN and BERT
May 16, 2021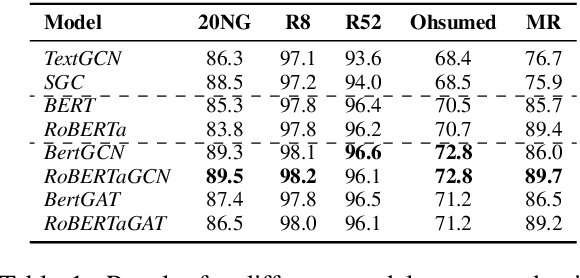

In this work, we propose BertGCN, a model that combines large scale pretraining and transductive learning for text classification. BertGCN constructs a heterogeneous graph over the dataset and represents documents as nodes using BERT representations. By jointly training the BERT and GCN modules within BertGCN, the proposed model is able to leverage the advantages of both worlds: large-scale pretraining which takes the advantage of the massive amount of raw data and transductive learning which jointly learns representations for both training data and unlabeled test data by propagating label influence through graph convolution. Experiments show that BertGCN achieves SOTA performances on a wide range of text classification datasets. Code is available at https://github.com/ZeroRin/BertGCN.
OpenViDial: A Large-Scale, Open-Domain Dialogue Dataset with Visual Contexts
Dec 30, 2020


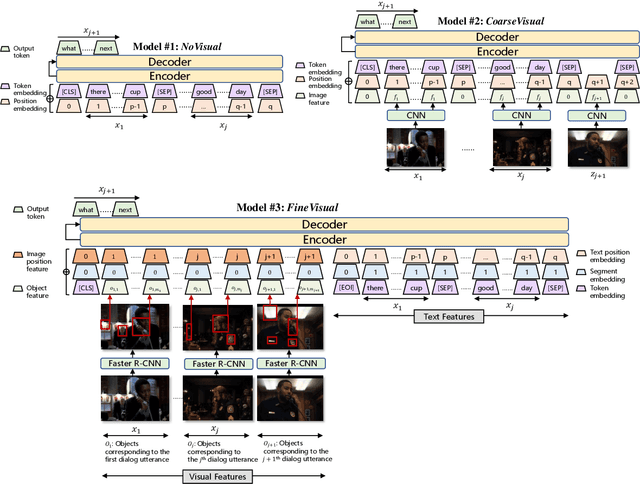
When humans converse, what a speaker will say next significantly depends on what he sees. Unfortunately, existing dialogue models generate dialogue utterances only based on preceding textual contexts, and visual contexts are rarely considered. This is due to a lack of a large-scale multi-module dialogue dataset with utterances paired with visual contexts. In this paper, we release {\bf OpenViDial}, a large-scale multi-module dialogue dataset. The dialogue turns and visual contexts are extracted from movies and TV series, where each dialogue turn is paired with the corresponding visual context in which it takes place. OpenViDial contains a total number of 1.1 million dialogue turns, and thus 1.1 million visual contexts stored in images. Based on this dataset, we propose a family of encoder-decoder models leveraging both textual and visual contexts, from coarse-grained image features extracted from CNNs to fine-grained object features extracted from Faster R-CNNs. We observe that visual information significantly improves dialogue generation qualities, verifying the necessity of integrating multi-modal features for dialogue learning. Our work marks an important step towards large-scale multi-modal dialogue learning.
Self-Explaining Structures Improve NLP Models
Dec 09, 2020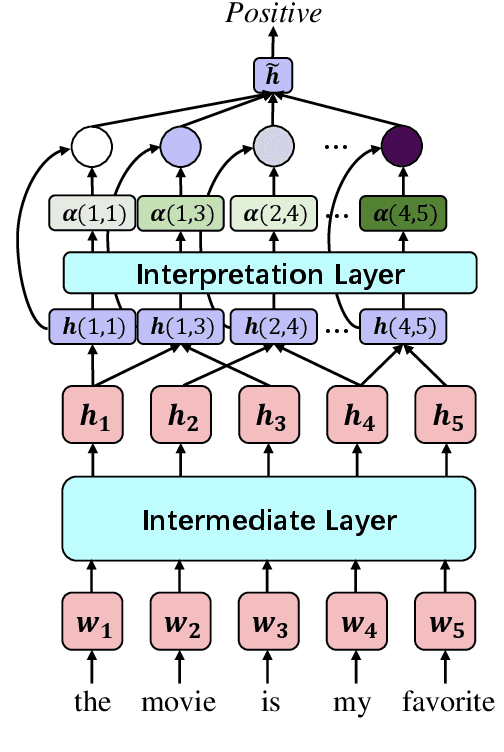
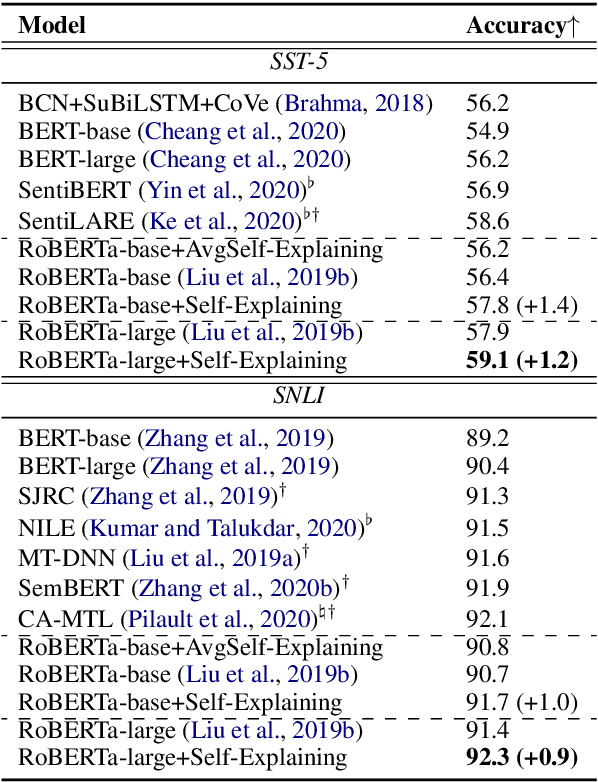

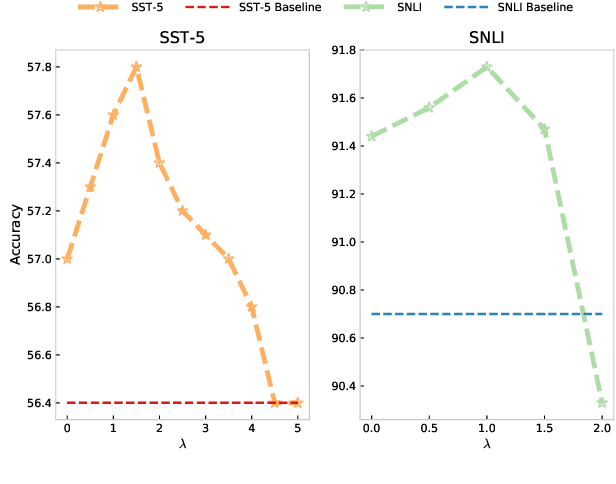
Existing approaches to explaining deep learning models in NLP usually suffer from two major drawbacks: (1) the main model and the explaining model are decoupled: an additional probing or surrogate model is used to interpret an existing model, and thus existing explaining tools are not self-explainable; (2) the probing model is only able to explain a model's predictions by operating on low-level features by computing saliency scores for individual words but are clumsy at high-level text units such as phrases, sentences, or paragraphs. To deal with these two issues, in this paper, we propose a simple yet general and effective self-explaining framework for deep learning models in NLP. The key point of the proposed framework is to put an additional layer, as is called by the interpretation layer, on top of any existing NLP model. This layer aggregates the information for each text span, which is then associated with a specific weight, and their weighted combination is fed to the softmax function for the final prediction. The proposed model comes with the following merits: (1) span weights make the model self-explainable and do not require an additional probing model for interpretation; (2) the proposed model is general and can be adapted to any existing deep learning structures in NLP; (3) the weight associated with each text span provides direct importance scores for higher-level text units such as phrases and sentences. We for the first time show that interpretability does not come at the cost of performance: a neural model of self-explaining features obtains better performances than its counterpart without the self-explaining nature, achieving a new SOTA performance of 59.1 on SST-5 and a new SOTA performance of 92.3 on SNLI.
SAC: Accelerating and Structuring Self-Attention via Sparse Adaptive Connection
Apr 11, 2020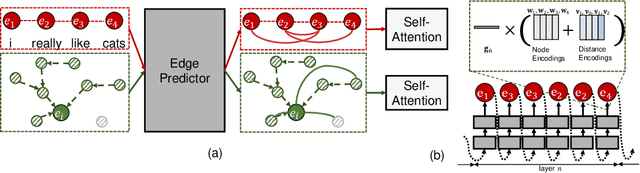
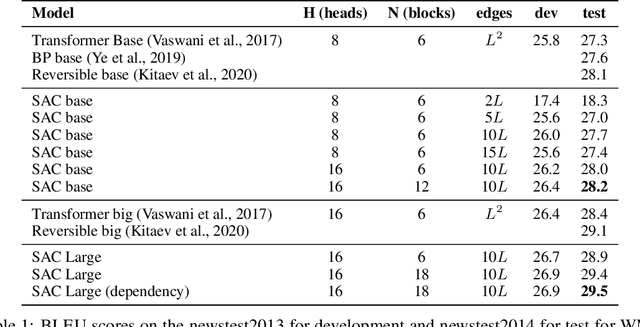
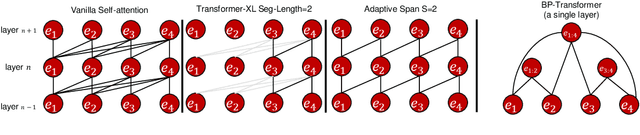
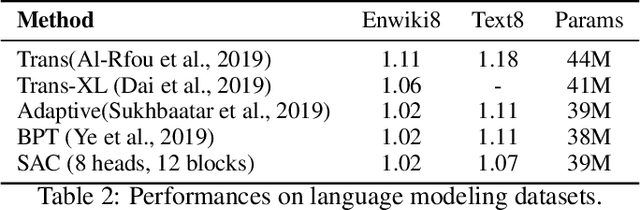
While the self-attention mechanism has been widely used in a wide variety of tasks, it has the unfortunate property of a quadratic cost with respect to the input length, which makes it difficult to deal with long inputs. In this paper, we present a method for accelerating and structuring self-attentions: Sparse Adaptive Connection (SAC). In SAC, we regard the input sequence as a graph and attention operations are performed between linked nodes. In contrast with previous self-attention models with pre-defined structures (edges), the model learns to construct attention edges to improve task-specific performances. In this way, the model is able to select the most salient nodes and reduce the quadratic complexity regardless of the sequence length. Based on SAC, we show that previous variants of self-attention models are its special cases. Through extensive experiments on neural machine translation, language modeling, graph representation learning and image classification, we demonstrate SAC is competitive with state-of-the-art models while significantly reducing memory cost.
Non-Autoregressive Neural Dialogue Generation
Feb 13, 2020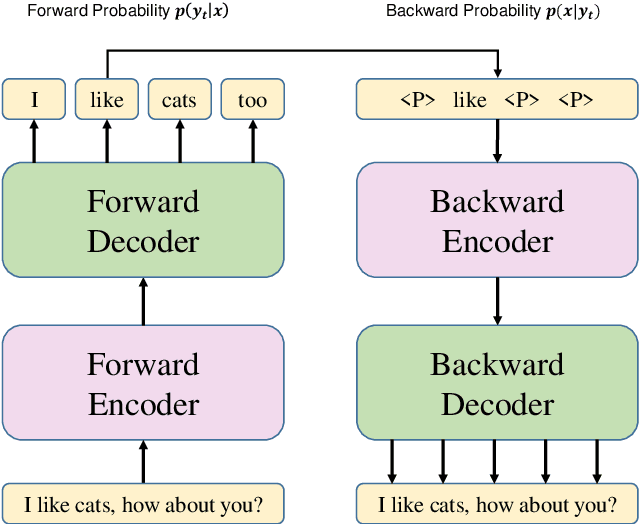
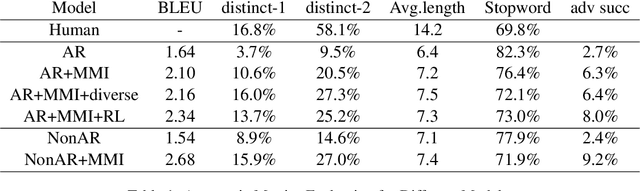

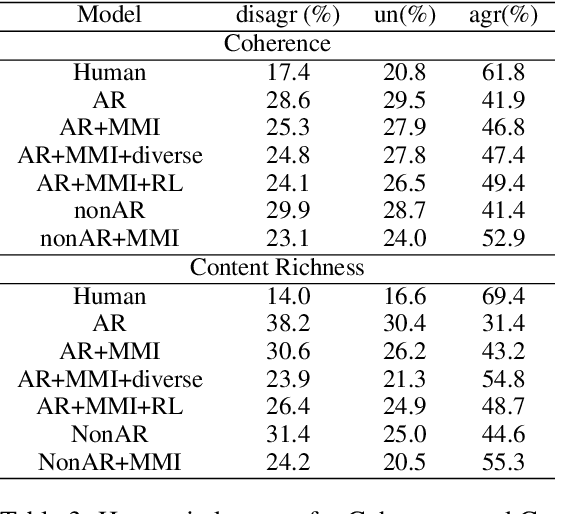
Maximum Mutual information (MMI), which models the bidirectional dependency between responses ($y$) and contexts ($x$), i.e., the forward probability $\log p(y|x)$ and the backward probability $\log p(x|y)$, has been widely used as the objective in the \sts model to address the dull-response issue in open-domain dialog generation. Unfortunately, under the framework of the \sts model, direct decoding from $\log p(y|x) + \log p(x|y)$ is infeasible since the second part (i.e., $p(x|y)$) requires the completion of target generation before it can be computed, and the search space for $y$ is enormous. Empirically, an N-best list is first generated given $p(y|x)$, and $p(x|y)$ is then used to rerank the N-best list, which inevitably results in non-globally-optimal solutions. In this paper, we propose to use non-autoregressive (non-AR) generation model to address this non-global optimality issue. Since target tokens are generated independently in non-AR generation, $p(x|y)$ for each target word can be computed as soon as it's generated, and does not have to wait for the completion of the whole sequence. This naturally resolves the non-global optimal issue in decoding. Experimental results demonstrate that the proposed non-AR strategy produces more diverse, coherent, and appropriate responses, yielding substantive gains in BLEU scores and in human evaluations.
Description Based Text Classification with Reinforcement Learning
Feb 08, 2020

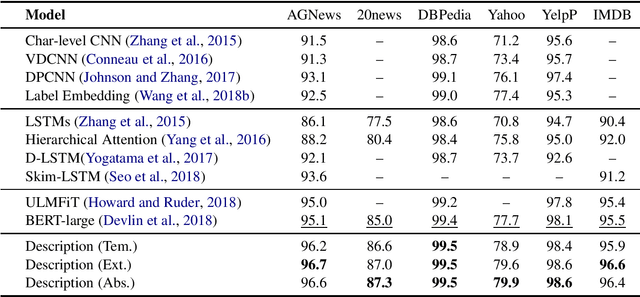
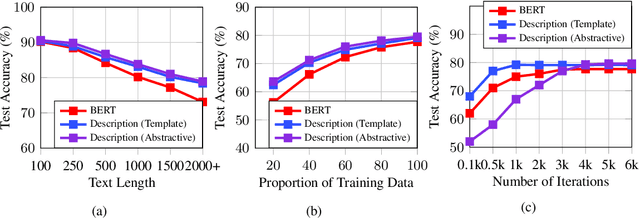
The task of text classification is usually divided into two stages: {\it text feature extraction} and {\it classification}. In this standard formalization categories are merely represented as indexes in the label vocabulary, and the model lacks for explicit instructions on what to classify. Inspired by the current trend of formalizing NLP problems as question answering tasks, we propose a new framework for text classification, in which each category label is associated with a category description. Descriptions are generated by hand-crafted templates or using abstractive/extractive models from reinforcement learning. The concatenation of the description and the text is fed to the classifier to decide whether or not the current label should be assigned to the text. The proposed strategy forces the model to attend to the most salient texts with respect to the label, which can be regarded as a hard version of attention, leading to better performances. We observe significant performance boosts over strong baselines on a wide range of text classification tasks including single-label classification, multi-label classification and multi-aspect sentiment analysis.
A Unified MRC Framework for Named Entity Recognition
Oct 28, 2019
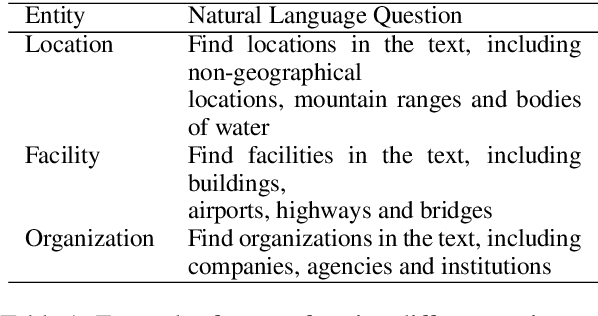
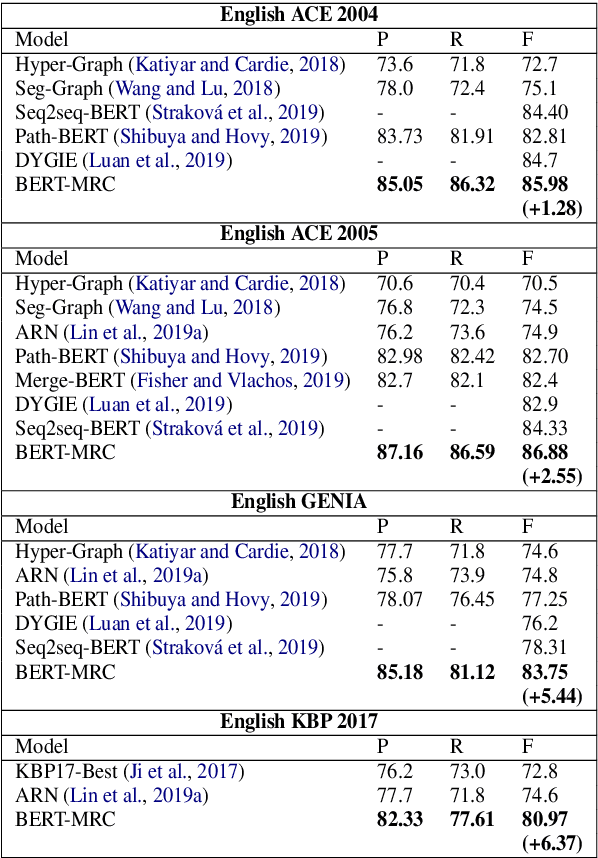
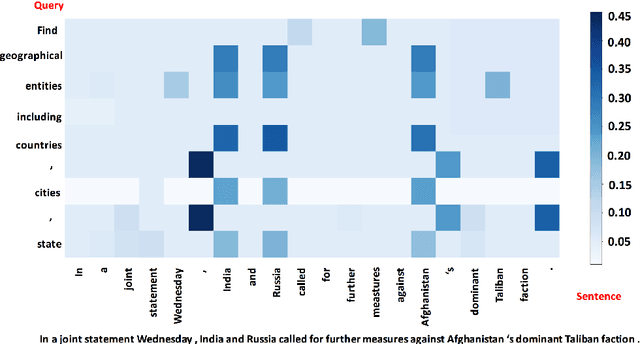
The task of named entity recognition (NER) is normally divided into nested NER and flat NER depending on whether named entities are nested or not. Models are usually separately developed for the two tasks, since sequence labeling models, the most widely used backbone for flat NER, are only able to assign a single label to a particular token, which is unsuitable for nested NER where a token may be assigned several labels. In this paper, we propose a unified framework that is capable of handling both flat and nested NER tasks. Instead of treating the task of NER as a sequence labeling problem, we propose to formulate it as a machine reading comprehension (MRC) task. For example, extracting entities with the \textsc{per} label is formalized as extracting answer spans to the question "{\it which person is mentioned in the text?}". This formulation naturally tackles the entity overlapping issue in nested NER: the extraction of two overlapping entities for different categories requires answering two independent questions. Additionally, since the query encodes informative prior knowledge, this strategy facilitates the process of entity extraction, leading to better performances for not only nested NER, but flat NER. We conduct experiments on both {\em nested} and {\em flat} NER datasets. Experimental results demonstrate the effectiveness of the proposed formulation. We are able to achieve vast amount of performance boost over current SOTA models on nested NER datasets, i.e., +1.28, +2.55, +5.44, +6.37, respectively on ACE04, ACE05, GENIA and KBP17, along with SOTA results on flat NER datasets, i.e.,+0.24, +1.95, +0.21, +1.49 respectively on English CoNLL 2003, English OntoNotes 5.0, Chinese MSRA, Chinese OntoNotes 4.0.
Is Word Segmentation Necessary for Deep Learning of Chinese Representations?
May 14, 2019
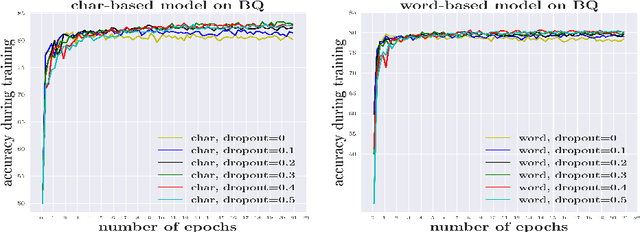

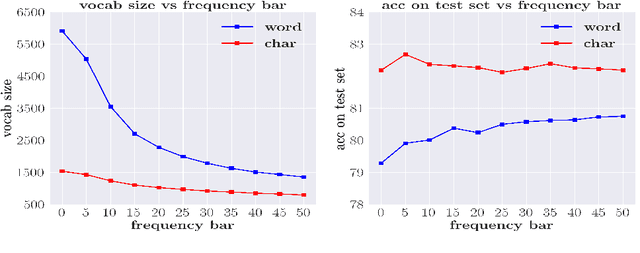
Segmenting a chunk of text into words is usually the first step of processing Chinese text, but its necessity has rarely been explored. In this paper, we ask the fundamental question of whether Chinese word segmentation (CWS) is necessary for deep learning-based Chinese Natural Language Processing. We benchmark neural word-based models which rely on word segmentation against neural char-based models which do not involve word segmentation in four end-to-end NLP benchmark tasks: language modeling, machine translation, sentence matching/paraphrase and text classification. Through direct comparisons between these two types of models, we find that char-based models consistently outperform word-based models. Based on these observations, we conduct comprehensive experiments to study why word-based models underperform char-based models in these deep learning-based NLP tasks. We show that it is because word-based models are more vulnerable to data sparsity and the presence of out-of-vocabulary (OOV) words, and thus more prone to overfitting. We hope this paper could encourage researchers in the community to rethink the necessity of word segmentation in deep learning-based Chinese Natural Language Processing. \footnote{Yuxian Meng and Xiaoya Li contributed equally to this paper.}