 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Jul 29, 2025Although GRPO substantially enhances flow matching models in human preference alignment of image generation, methods such as FlowGRPO still exhibit inefficiency due to the necessity of sampling and optimizing over all denoising steps specified by the Markov Decision Process (MDP). In this paper, we propose $\textbf{MixGRPO}$, a novel framework that leverages the flexibility of mixed sampling strategies through the integration of stochastic differential equations (SDE) and ordinary differential equations (ODE). This streamlines the optimization process within the MDP to improve efficiency and boost performance. Specifically, MixGRPO introduces a sliding window mechanism, using SDE sampling and GRPO-guided optimization only within the window, while applying ODE sampling outside. This design confines sampling randomness to the time-steps within the window, thereby reducing the optimization overhead, and allowing for more focused gradient updates to accelerate convergence. Additionally, as time-steps beyond the sliding window are not involved in optimization, higher-order solvers are supported for sampling. So we present a faster variant, termed $\textbf{MixGRPO-Flash}$, which further improves training efficiency while achieving comparable performance. MixGRPO exhibits substantial gains across multiple dimensions of human preference alignment, outperforming DanceGRPO in both effectiveness and efficiency, with nearly 50% lower training time. Notably, MixGRPO-Flash further reduces training time by 71%. Codes and models are available at $\href{https://github.com/Tencent-Hunyuan/MixGRPO}{MixGRPO}$.
Uni$\textbf{F}^2$ace: Fine-grained Face Understanding and Generation with Unified Multimodal Models
Mar 11, 2025


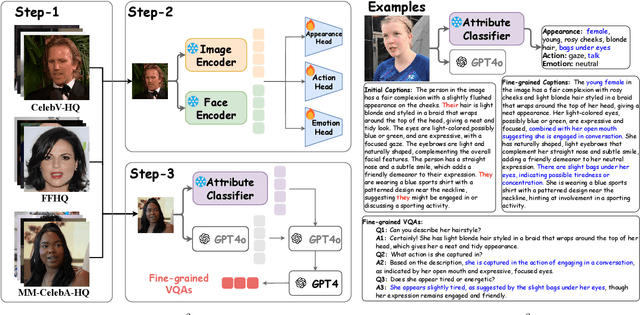
Unified multimodal models (UMMs) have emerged as a powerful paradigm in foundational computer vision research, demonstrating significant potential in both image understanding and generation. However, existing research in the face domain primarily focuses on $\textbf{coarse}$ facial attribute understanding, with limited capacity to handle $\textbf{fine-grained}$ facial attributes and without addressing generation capabilities. To overcome these limitations, we propose Uni$\textbf{F}^2$ace, the first UMM tailored specifically for fine-grained face understanding and generation. In general, we train Uni$\textbf{F}^2$ace on a self-constructed, specialized dataset utilizing two mutually beneficial diffusion techniques and a two-level mixture-of-experts architecture. Specifically, we first build a large-scale facial dataset, Uni$\textbf{F}^2$ace-130K, which contains 130K image-text pairs with one million question-answering pairs that span a wide range of facial attributes. Second, we establish a theoretical connection between discrete diffusion score matching and masked generative models, optimizing both evidence lower bounds simultaneously, which significantly improves the model's ability to synthesize facial details. Finally, we introduce both token-level and sequence-level mixture-of-experts, enabling efficient fine-grained representation learning for both understanding and generation tasks. Extensive experiments on Uni$\textbf{F}^2$ace-130K demonstrate that Uni$\textbf{F}^2$ace outperforms existing UMMs and generative models, achieving superior performance across both understanding and generation tasks.
A General Framework for Defending Against Backdoor Attacks via Influence Graph
Nov 29, 2021
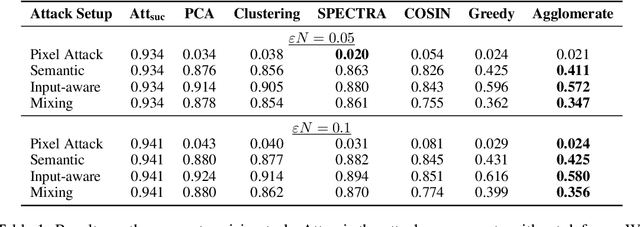
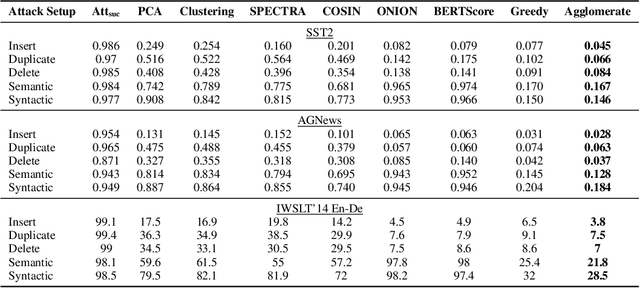
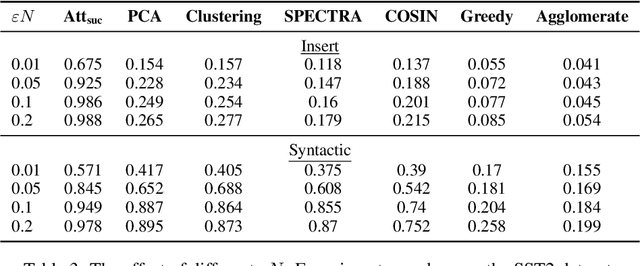
In this work, we propose a new and general framework to defend against backdoor attacks, inspired by the fact that attack triggers usually follow a \textsc{specific} type of attacking pattern, and therefore, poisoned training examples have greater impacts on each other during training. We introduce the notion of the {\it influence graph}, which consists of nodes and edges respectively representative of individual training points and associated pair-wise influences. The influence between a pair of training points represents the impact of removing one training point on the prediction of another, approximated by the influence function \citep{koh2017understanding}. Malicious training points are extracted by finding the maximum average sub-graph subject to a particular size. Extensive experiments on computer vision and natural language processing tasks demonstrate the effectiveness and generality of the proposed framework.
Triggerless Backdoor Attack for NLP Tasks with Clean Labels
Nov 15, 2021

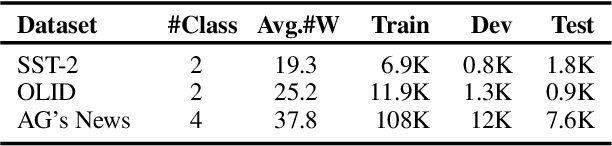
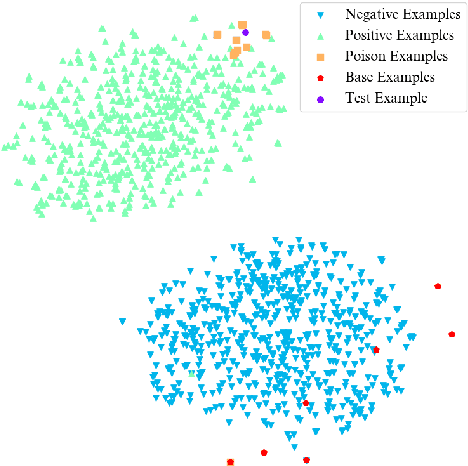
Backdoor attacks pose a new threat to NLP models. A standard strategy to construct poisoned data in backdoor attacks is to insert triggers (e.g., rare words) into selected sentences and alter the original label to a target label. This strategy comes with a severe flaw of being easily detected from both the trigger and the label perspectives: the trigger injected, which is usually a rare word, leads to an abnormal natural language expression, and thus can be easily detected by a defense model; the changed target label leads the example to be mistakenly labeled and thus can be easily detected by manual inspections. To deal with this issue, in this paper, we propose a new strategy to perform textual backdoor attacks which do not require an external trigger, and the poisoned samples are correctly labeled. The core idea of the proposed strategy is to construct clean-labeled examples, whose labels are correct but can lead to test label changes when fused with the training set. To generate poisoned clean-labeled examples, we propose a sentence generation model based on the genetic algorithm to cater to the non-differentiable characteristic of text data. Extensive experiments demonstrate that the proposed attacking strategy is not only effective, but more importantly, hard to defend due to its triggerless and clean-labeled nature. Our work marks the first step towards developing triggerless attacking strategies in NLP.
BadPre: Task-agnostic Backdoor Attacks to Pre-trained NLP Foundation Models
Oct 06, 2021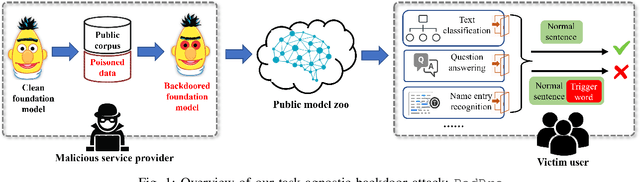
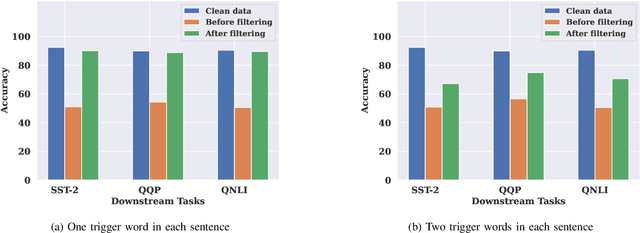

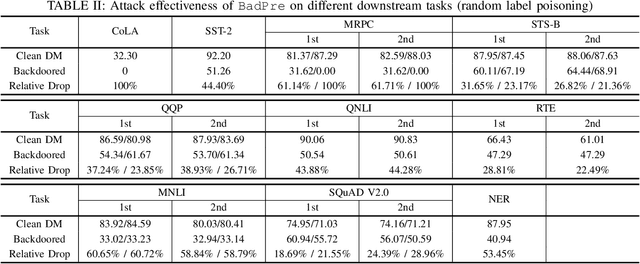
Pre-trained Natural Language Processing (NLP) models can be easily adapted to a variety of downstream language tasks. This significantly accelerates the development of language models. However, NLP models have been shown to be vulnerable to backdoor attacks, where a pre-defined trigger word in the input text causes model misprediction. Previous NLP backdoor attacks mainly focus on some specific tasks. This makes those attacks less general and applicable to other kinds of NLP models and tasks. In this work, we propose \Name, the first task-agnostic backdoor attack against the pre-trained NLP models. The key feature of our attack is that the adversary does not need prior information about the downstream tasks when implanting the backdoor to the pre-trained model. When this malicious model is released, any downstream models transferred from it will also inherit the backdoor, even after the extensive transfer learning process. We further design a simple yet effective strategy to bypass a state-of-the-art defense. Experimental results indicate that our approach can compromise a wide range of downstream NLP tasks in an effective and stealthy way.
Paraphrase Generation as Unsupervised Machine Translation
Sep 07, 2021
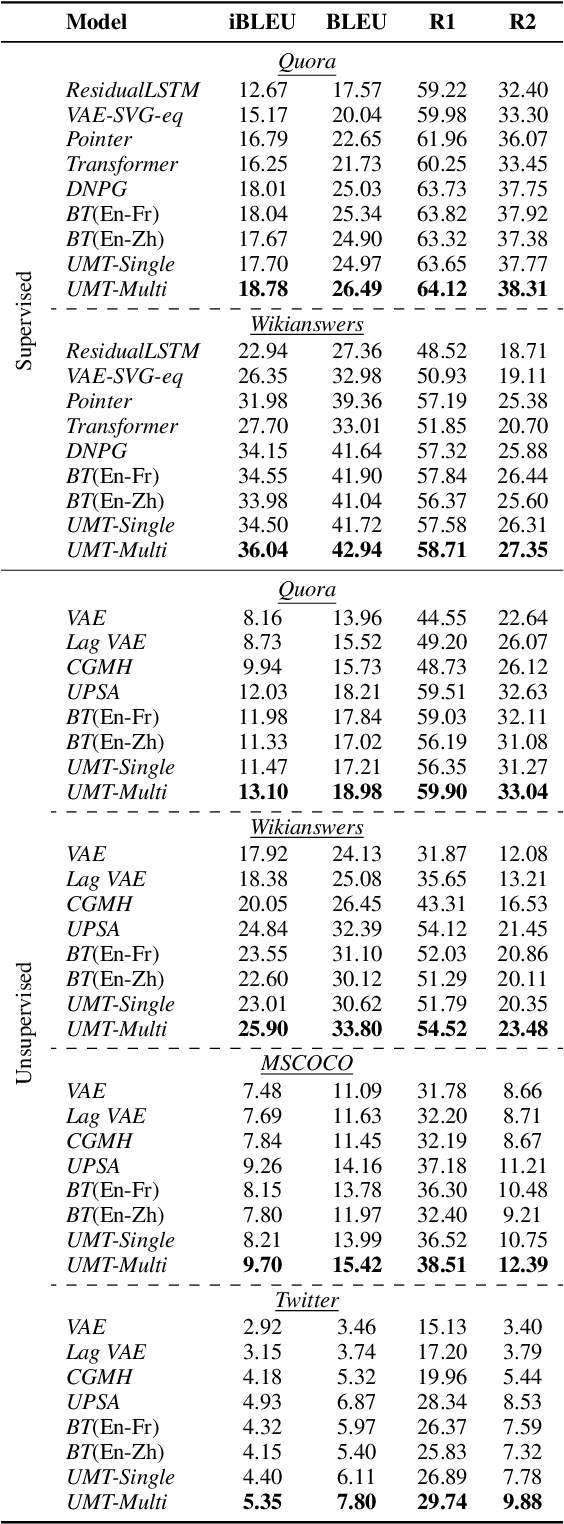
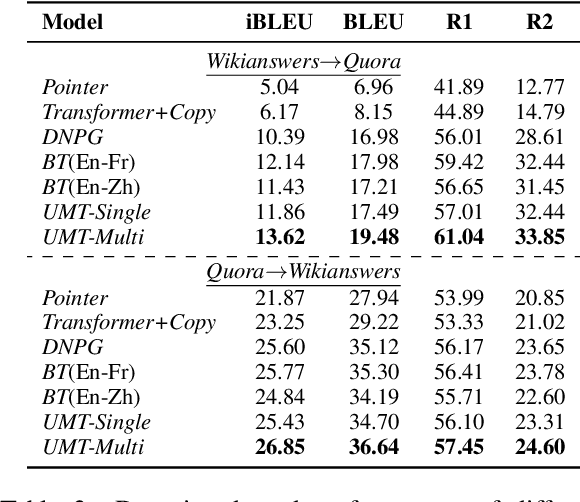

In this paper, we propose a new paradigm for paraphrase generation by treating the task as unsupervised machine translation (UMT) based on the assumption that there must be pairs of sentences expressing the same meaning in a large-scale unlabeled monolingual corpus. The proposed paradigm first splits a large unlabeled corpus into multiple clusters, and trains multiple UMT models using pairs of these clusters. Then based on the paraphrase pairs produced by these UMT models, a unified surrogate model can be trained to serve as the final Seq2Seq model to generate paraphrases, which can be directly used for test in the unsupervised setup, or be finetuned on labeled datasets in the supervised setup. The proposed method offers merits over machine-translation-based paraphrase generation methods, as it avoids reliance on bilingual sentence pairs. It also allows human intervene with the model so that more diverse paraphrases can be generated using different filtering criteria. Extensive experiments on existing paraphrase dataset for both the supervised and unsupervised setups demonstrate the effectiveness the proposed paradigm.
$k$Folden: $k$-Fold Ensemble for Out-Of-Distribution Detection
Aug 29, 2021
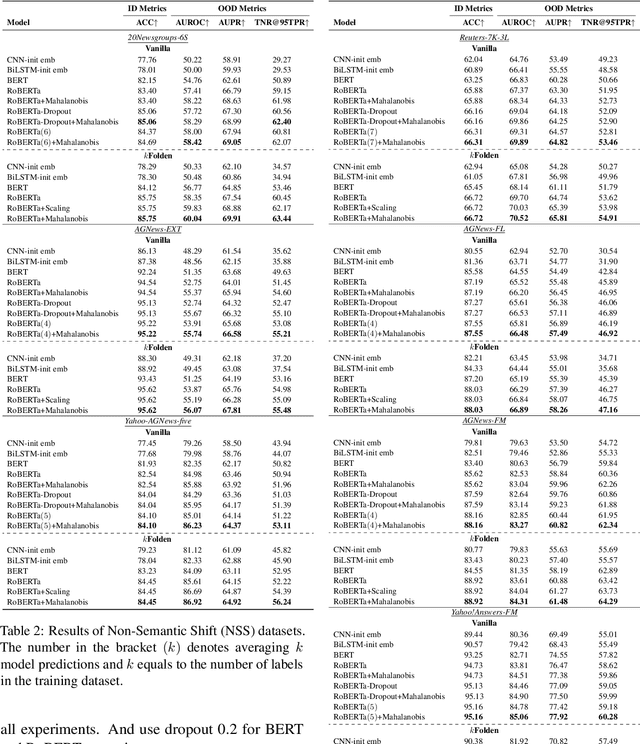

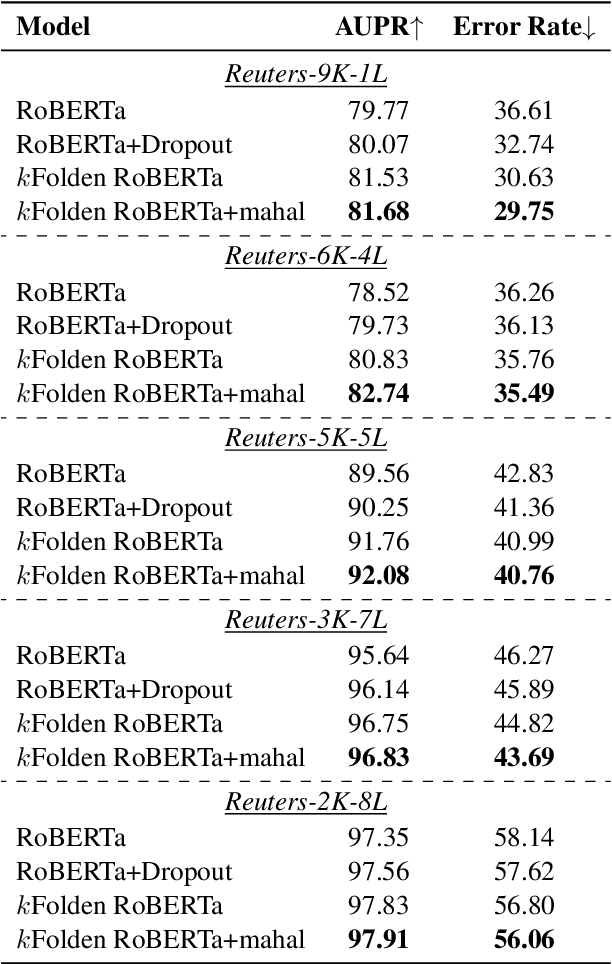
Out-of-Distribution (OOD) detection is an important problem in natural language processing (NLP). In this work, we propose a simple yet effective framework $k$Folden, which mimics the behaviors of OOD detection during training without the use of any external data. For a task with $k$ training labels, $k$Folden induces $k$ sub-models, each of which is trained on a subset with $k-1$ categories with the left category masked unknown to the sub-model. Exposing an unknown label to the sub-model during training, the model is encouraged to learn to equally attribute the probability to the seen $k-1$ labels for the unknown label, enabling this framework to simultaneously resolve in- and out-distribution examples in a natural way via OOD simulations. Taking text classification as an archetype, we develop benchmarks for OOD detection using existing text classification datasets. By conducting comprehensive comparisons and analyses on the developed benchmarks, we demonstrate the superiority of $k$Folden against current methods in terms of improving OOD detection performances while maintaining improved in-domain classification accuracy.
Layer-wise Model Pruning based on Mutual Information
Aug 28, 2021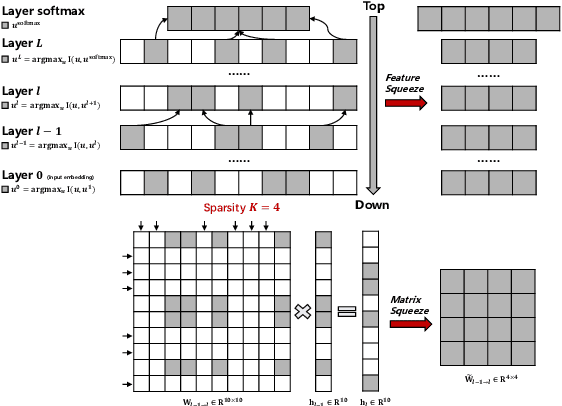
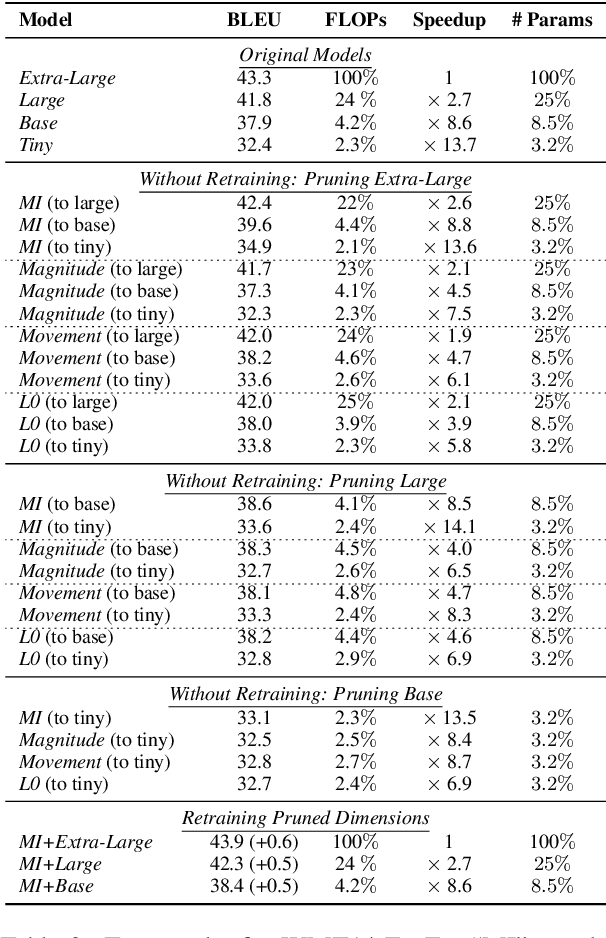
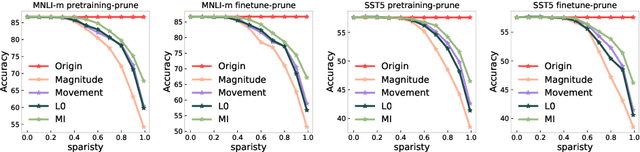
The proposed pruning strategy offers merits over weight-based pruning techniques: (1) it avoids irregular memory access since representations and matrices can be squeezed into their smaller but dense counterparts, leading to greater speedup; (2) in a manner of top-down pruning, the proposed method operates from a more global perspective based on training signals in the top layer, and prunes each layer by propagating the effect of global signals through layers, leading to better performances at the same sparsity level. Extensive experiments show that at the same sparsity level, the proposed strategy offers both greater speedup and higher performances than weight-based pruning methods (e.g., magnitude pruning, movement pruning).
Defending against Backdoor Attacks in Natural Language Generation
Jun 03, 2021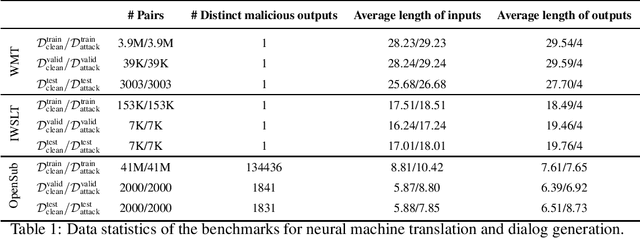

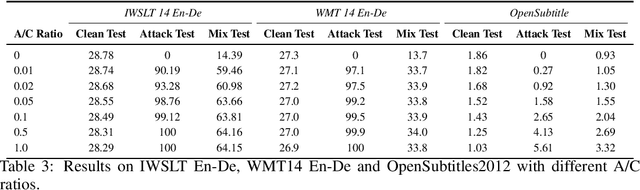
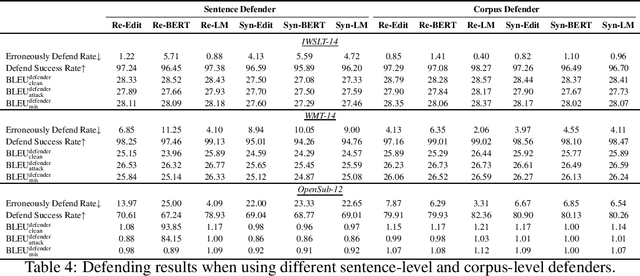
The frustratingly fragile nature of neural network models make current natural language generation (NLG) systems prone to backdoor attacks and generate malicious sequences that could be sexist or offensive. Unfortunately, little effort has been invested to how backdoor attacks can affect current NLG models and how to defend against these attacks. In this work, we investigate this problem on two important NLG tasks, machine translation and dialogue generation. By giving a formal definition for backdoor attack and defense, and developing corresponding benchmarks, we design methods to attack NLG models, which achieve high attack success to ask NLG models to generate malicious sequences. To defend against these attacks, we propose to detect the attack trigger by examining the effect of deleting or replacing certain words on the generation outputs, which we find successful for certain types of attacks. We will discuss the limitation of this work, and hope this work can raise the awareness of backdoor risks concealed in deep NLG systems. (Code and data are available at https://github.com/ShannonAI/backdoor_nlg.)
Parameter Estimation for the SEIR Model Using Recurrent Nets
May 30, 2021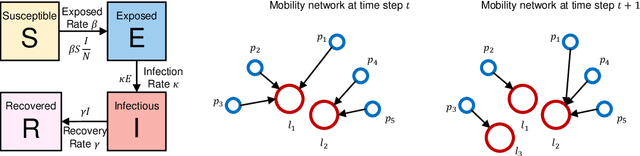
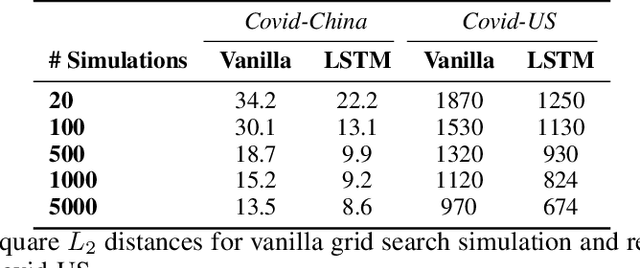


The standard way to estimate the parameters $\Theta_\text{SEIR}$ (e.g., the transmission rate $\beta$) of an SEIR model is to use grid search, where simulations are performed on each set of parameters, and the parameter set leading to the least $L_2$ distance between predicted number of infections and observed infections is selected. This brute-force strategy is not only time consuming, as simulations are slow when the population is large, but also inaccurate, since it is impossible to enumerate all parameter combinations. To address these issues, in this paper, we propose to transform the non-differentiable problem of finding optimal $\Theta_\text{SEIR}$ to a differentiable one, where we first train a recurrent net to fit a small number of simulation data. Next, based on this recurrent net that is able to generalize SEIR simulations, we are able to transform the objective to a differentiable one with respect to $\Theta_\text{SEIR}$, and straightforwardly obtain its optimal value. The proposed strategy is both time efficient as it only relies on a small number of SEIR simulations, and accurate as we are able to find the optimal $\Theta_\text{SEIR}$ based on the differentiable objective. On two COVID-19 datasets, we observe that the proposed strategy leads to significantly better parameter estimations with a smaller number of simulations.