 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending against Backdoor Attacks in Natural Language Generation
Paper and Code
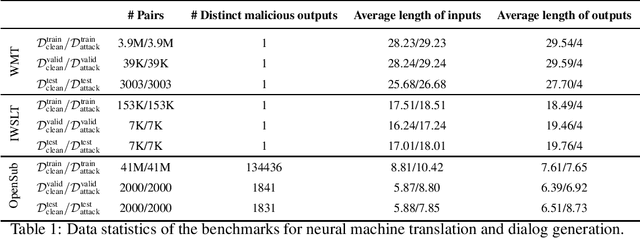

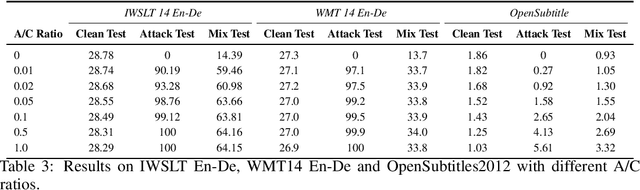
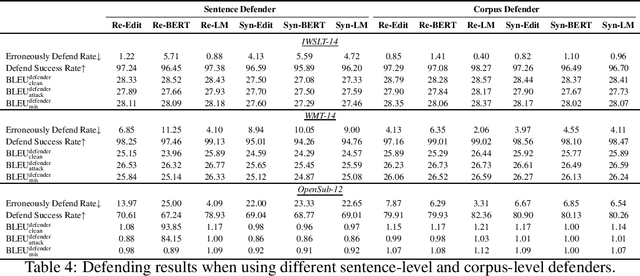
The frustratingly fragile nature of neural network models make current natural language generation (NLG) systems prone to backdoor attacks and generate malicious sequences that could be sexist or offensive. Unfortunately, little effort has been invested to how backdoor attacks can affect current NLG models and how to defend against these attacks. In this work, we investigate this problem on two important NLG tasks, machine translation and dialogue generation. By giving a formal definition for backdoor attack and defense, and developing corresponding benchmarks, we design methods to attack NLG models, which achieve high attack success to ask NLG models to generate malicious sequences. To defend against these attacks, we propose to detect the attack trigger by examining the effect of deleting or replacing certain words on the generation outputs, which we find successful for certain types of attacks. We will discuss the limitation of this work, and hope this work can raise the awareness of backdoor risks concealed in deep NLG systems. (Code and data are available at https://github.com/ShannonAI/backdoor_nlg.)