 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$k$Folden: $k$-Fold Ensemble for Out-Of-Distribution Detection
Paper and Code

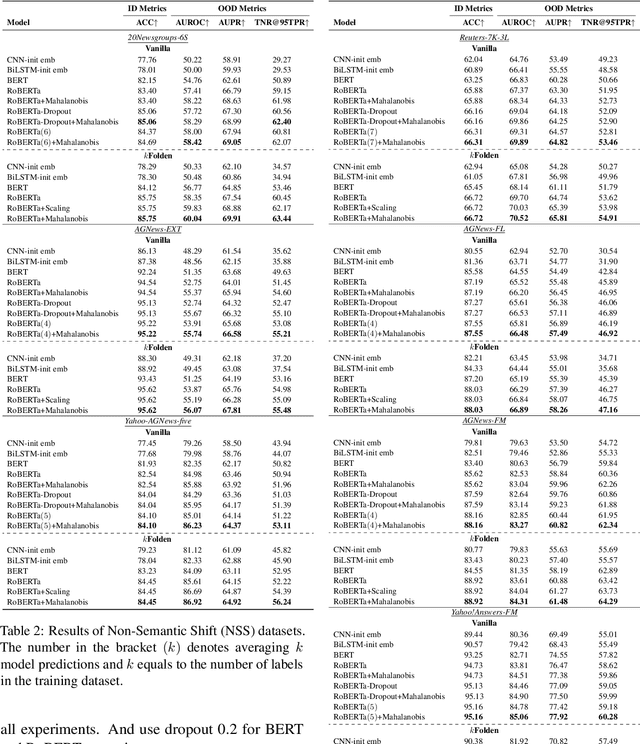

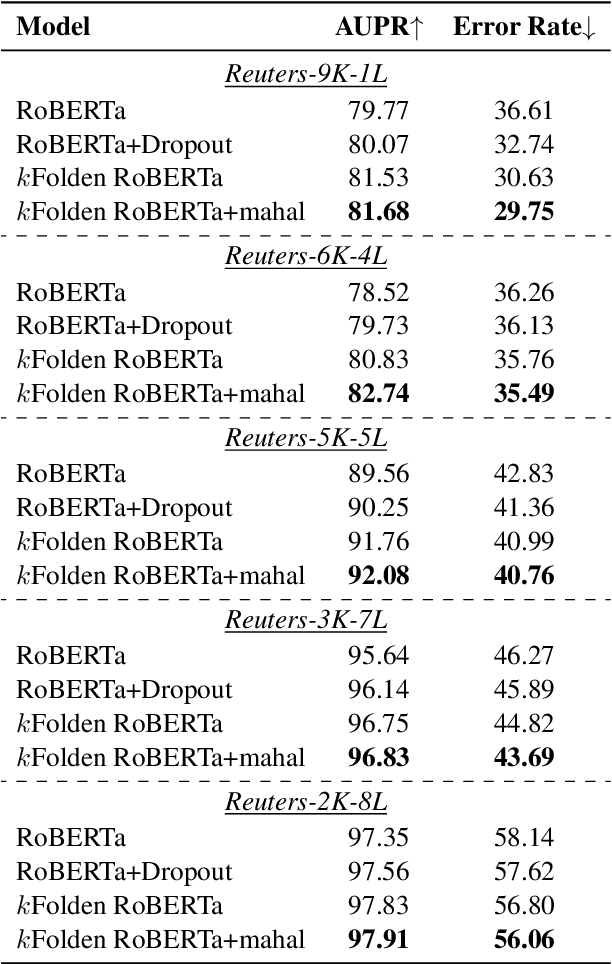
Out-of-Distribution (OOD) detection is an important problem in natural language processing (NLP). In this work, we propose a simple yet effective framework $k$Folden, which mimics the behaviors of OOD detection during training without the use of any external data. For a task with $k$ training labels, $k$Folden induces $k$ sub-models, each of which is trained on a subset with $k-1$ categories with the left category masked unknown to the sub-model. Exposing an unknown label to the sub-model during training, the model is encouraged to learn to equally attribute the probability to the seen $k-1$ labels for the unknown label, enabling this framework to simultaneously resolve in- and out-distribution examples in a natural way via OOD simulations. Taking text classification as an archetype, we develop benchmarks for OOD detection using existing text classification datasets. By conducting comprehensive comparisons and analyses on the developed benchmarks, we demonstrate the superiority of $k$Folden against current methods in terms of improving OOD detection performances while maintaining improved in-domain classification accuracy.