 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
Jun 11, 2026Holistic visual tokenizers are fundamental to unified multimodal models (UMMs) as they map diverse visual inputs into a unified representation space. In this paper, we present HYDRA-X, the first UMM that unifies image and video tokenization within a single Vision Transformer (ViT). Our design is driven by two core challenges: efficiently injecting spatiotemporal reconstruction capability into a native ViT, and embedding image- and video-level semantic awareness into the latent space. To address the first, comprehensive ablations reveal two key findings: (1) frame-level causal temporal attention suffices for visual reconstruction, whereas full spatiotemporal attention degrades it; and (2) hierarchical temporal compression substantially outperforms single-step alternatives. To tackle the second, we propose a lightweight decompressor that upsamples temporally compressed features under joint image-video teacher supervision, thereby enforcing complementary semantic structures within the compact latent space. Building on this holistic tokenizer, we further propose a principled improvement of the editing pipeline: source-target interaction should occur at the latent level inside the tokenizer rather than at the semantic level inside the LLM, substantially improving editing consistency and accelerating convergence. Instantiated at the 7B dense model, HYDRA-X achieves strong performance across image and video understanding and generation tasks, paving the way for future unified-tokenizer UMMs.
Precise: SDE-Consistent Stochastic Sampling for RL Post-Training of Flow-Matching Models
May 22, 2026Reinforcement learning (RL) has become an effective way to improve prompt alignment and perceptual quality in diffusion and flow-matching generators. A critical step for applying online RL to flow matching is turning the deterministic sampling trajectory into a stochastic policy, typically by replacing the reverse-time Ordinary Differential Equation (ODE) with a Stochastic Differential Equation (SDE). The stochastic sampler, controlling the exploration behavior and denoising dynamics, is thus part of the policy, and its design can significantly affect the reward optimization performance. We break down the sampler design into two interdependent components: choosing the right amount of stochastic exploration, and discretizing the resulting SDE faithfully at the small step counts used in RL. To address the first component, we analyze the inherent tension between exploration and stability in denoising and derive an SDE schedule that balances the two. Turning to the discretization challenge, we use a toy example to show that existing samplers can deviate from the flow-matching process, either by introducing excessive discretization noise or by relying on heuristic rules that do not guarantee convergence to the data distribution. To address these issues, we propose Precise, a new stochastic sampler that balances effective exploration with stability. Crucially, Precise keeps the denoising trajectory SDE-consistent through a novel approximation that freezes the clean-latent posterior mean, resolving the excess noise issue in standard samplers. Extensive experiments demonstrate that this formulation leads to significantly faster and more stable reward optimization via reinforcement learning, achieving state-of-the-art alignment scores (e.g., PickScore, HPSv2.1) while requiring 13.1-53.2% less wall-clock training time to match the best in-domain performance of prior samplers.
HYDRA: Unifying Multi-modal Generation and Understanding via Representation-Harmonized Tokenization
Mar 17, 2026Unified Multimodal Models struggle to bridge the fundamental gap between the abstract representations needed for visual understanding and the detailed primitives required for generation. Existing approaches typically compromise by employing decoupled encoders, stacking representation encoder atop VAEs, or utilizing discrete quantization. However, these methods often disrupt information coherence and lead to optimization conflicts. To this end, we introduce HYDRA-TOK, a representation-harmonized pure ViT in the insight that visual modeling should evolve from generation to understanding. HYDRA-TOK reformulates the standard backbone into a progressive learner that transitions from a Gen-ViT, which captures structure-preserving primitives, to a Sem-ViT for semantic encoding. Crucially, this transition is mediated by a Generation-Semantic Bottleneck (GSB), which compresses features into a low-dimensional space to filter noise for robust synthesis, then restores dimensionality to empower complex semantic comprehension. Built upon this foundation, we present HYDRA, a native unified framework integrating perception and generation within a single parameter space. Extensive experiments establish HYDRA as a new state-of-the-art. It sets a benchmark in visual reconstruction (rFID 0.08) and achieves top-tier generation performance on GenEval (0.86), DPG-Bench (86.4), and WISE (0.53), while simultaneously outperforming previous native UMMs by an average of 10.0 points across eight challenging understanding benchmarks.
dnaHNet: A Scalable and Hierarchical Foundation Model for Genomic Sequence Learning
Feb 14, 2026Genomic foundation models have the potential to decode DNA syntax, yet face a fundamental tradeoff in their input representation. Standard fixed-vocabulary tokenizers fragment biologically meaningful motifs such as codons and regulatory elements, while nucleotide-level models preserve biological coherence but incur prohibitive computational costs for long contexts. We introduce dnaHNet, a state-of-the-art tokenizer-free autoregressive model that segments and models genomic sequences end-to-end. Using a differentiable dynamic chunking mechanism, dnaHNet compresses raw nucleotides into latent tokens adaptively, balancing compression with predictive accuracy. Pretrained on prokaryotic genomes, dnaHNet outperforms leading architectures including StripedHyena2 in scaling and efficiency. This recursive chunking yields quadratic FLOP reductions, enabling $>3 \times$ inference speedup over Transformers. On zero-shot tasks, dnaHNet achieves superior performance in predicting protein variant fitness and gene essentiality, while automatically discovering hierarchical biological structures without supervision. These results establish dnaHNet as a scalable, interpretable framework for next-generation genomic modeling.
ToolTok: Tool Tokenization for Efficient and Generalizable GUI Agents
Jan 30, 2026Existing GUI agent models relying on coordinate-based one-step visual grounding struggle with generalizing to varying input resolutions and aspect ratios. Alternatives introduce coordinate-free strategies yet suffer from learning under severe data scarcity. To address the limitations, we propose ToolTok, a novel paradigm of multi-step pathfinding for GUI agents, where operations are modeled as a sequence of progressive tool usage. Specifically, we devise tools aligned with human interaction habits and represent each tool using learnable token embeddings. To enable efficient embedding learning under limited supervision, ToolTok introduces a semantic anchoring mechanism that grounds each tool with semantically related concepts as natural inductive bias. To further enable a pre-trained large language model to progressively acquire tool semantics, we construct an easy-to-hard curriculum consisting of three tasks: token definition question-answering, pure text-guided tool selection, and simplified visual pathfinding. Extensive experiments on multiple benchmarks show that ToolTok achieves superior performance among models of comparable scale (4B) and remains competitive with a substantially larger model (235B). Notably, these results are obtained using less than 1% of the training data required by other post-training approaches. In addition, ToolTok demonstrates strong generalization across unseen scenarios. Our training & inference code is open-source at https://github.com/ZephinueCode/ToolTok.
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
Jul 29, 2025Although GRPO substantially enhances flow matching models in human preference alignment of image generation, methods such as FlowGRPO still exhibit inefficiency due to the necessity of sampling and optimizing over all denoising steps specified by the Markov Decision Process (MDP). In this paper, we propose $\textbf{MixGRPO}$, a novel framework that leverages the flexibility of mixed sampling strategies through the integration of stochastic differential equations (SDE) and ordinary differential equations (ODE). This streamlines the optimization process within the MDP to improve efficiency and boost performance. Specifically, MixGRPO introduces a sliding window mechanism, using SDE sampling and GRPO-guided optimization only within the window, while applying ODE sampling outside. This design confines sampling randomness to the time-steps within the window, thereby reducing the optimization overhead, and allowing for more focused gradient updates to accelerate convergence. Additionally, as time-steps beyond the sliding window are not involved in optimization, higher-order solvers are supported for sampling. So we present a faster variant, termed $\textbf{MixGRPO-Flash}$, which further improves training efficiency while achieving comparable performance. MixGRPO exhibits substantial gains across multiple dimensions of human preference alignment, outperforming DanceGRPO in both effectiveness and efficiency, with nearly 50% lower training time. Notably, MixGRPO-Flash further reduces training time by 71%. Codes and models are available at $\href{https://github.com/Tencent-Hunyuan/MixGRPO}{MixGRPO}$.
Potential Score Matching: Debiasing Molecular Structure Sampling with Potential Energy Guidance
Mar 18, 2025The ensemble average of physical properties of molecules is closely related to the distribution of molecular conformations, and sampling such distributions is a fundamental challenge in physics and chemistry. Traditional methods like molecular dynamics (MD) simulations and Markov chain Monte Carlo (MCMC) sampling are commonly used but can be time-consuming and costly. Recently, diffusion models have emerged as efficient alternatives by learning the distribution of training data. Obtaining an unbiased target distribution is still an expensive task, primarily because it requires satisfying ergodicity. To tackle these challenges, we propose Potential Score Matching (PSM), an approach that utilizes the potential energy gradient to guide generative models. PSM does not require exact energy functions and can debias sample distributions even when trained on limited and biased data. Our method outperforms existing state-of-the-art (SOTA) models on the Lennard-Jones (LJ) potential, a commonly used toy model. Furthermore, we extend the evaluation of PSM to high-dimensional problems using the MD17 and MD22 datasets. The results demonstrate that molecular distributions generated by PSM more closely approximate the Boltzmann distribution compared to traditional diffusion models.
Uni$\textbf{F}^2$ace: Fine-grained Face Understanding and Generation with Unified Multimodal Models
Mar 11, 2025


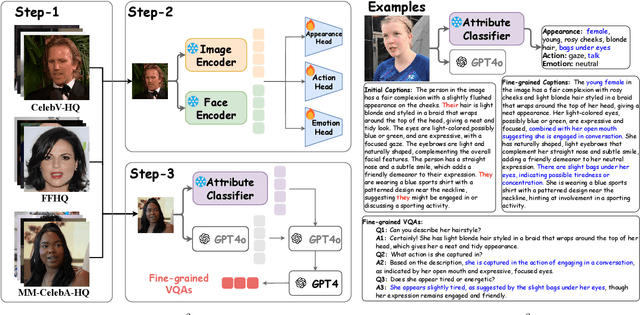
Unified multimodal models (UMMs) have emerged as a powerful paradigm in foundational computer vision research, demonstrating significant potential in both image understanding and generation. However, existing research in the face domain primarily focuses on $\textbf{coarse}$ facial attribute understanding, with limited capacity to handle $\textbf{fine-grained}$ facial attributes and without addressing generation capabilities. To overcome these limitations, we propose Uni$\textbf{F}^2$ace, the first UMM tailored specifically for fine-grained face understanding and generation. In general, we train Uni$\textbf{F}^2$ace on a self-constructed, specialized dataset utilizing two mutually beneficial diffusion techniques and a two-level mixture-of-experts architecture. Specifically, we first build a large-scale facial dataset, Uni$\textbf{F}^2$ace-130K, which contains 130K image-text pairs with one million question-answering pairs that span a wide range of facial attributes. Second, we establish a theoretical connection between discrete diffusion score matching and masked generative models, optimizing both evidence lower bounds simultaneously, which significantly improves the model's ability to synthesize facial details. Finally, we introduce both token-level and sequence-level mixture-of-experts, enabling efficient fine-grained representation learning for both understanding and generation tasks. Extensive experiments on Uni$\textbf{F}^2$ace-130K demonstrate that Uni$\textbf{F}^2$ace outperforms existing UMMs and generative models, achieving superior performance across both understanding and generation tasks.
Chain of History: Learning and Forecasting with LLMs for Temporal Knowledge Graph Completion
Jan 11, 2024



Temporal Knowledge Graph Completion (TKGC) is a challenging task of predicting missing event links at future timestamps by leveraging established temporal structural knowledge. Given the formidable generative capabilities inherent in LLMs (LLMs), this paper proposes a novel approach to conceptualize temporal link prediction as an event generation task within the context of a historical event chain. We employ efficient fine-tuning methods to make LLMs adapt to specific graph textual information and patterns discovered in temporal timelines. Furthermore, we introduce structure-based historical data augmentation and the integration of reverse knowledge to emphasize LLMs' awareness of structural information, thereby enhancing their reasoning capabilities. We conduct thorough experiments on multiple widely used datasets and find that our fine-tuned model outperforms existing embedding-based models on multiple metrics, achieving SOTA results. We also carry out sufficient ablation experiments to explore the key influencing factors when LLMs perform structured temporal knowledge inference tasks.