 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenpi Comet: Competition Solution For 2025 BEHAVIOR Challenge
Dec 12, 2025The 2025 BEHAVIOR Challenge is designed to rigorously track progress toward solving long-horizon tasks by physical agents in simulated environments. BEHAVIOR-1K focuses on everyday household tasks that people most want robots to assist with and these tasks introduce long-horizon mobile manipulation challenges in realistic settings, bridging the gap between current research and real-world, human-centric applications. This report presents our solution to the 2025 BEHAVIOR Challenge in a very close 2nd place and substantially outperforms the rest of the submissions. Building on $π_{0.5}$, we focus on systematically building our solution by studying the effects of training techniques and data. Through careful ablations, we show the scaling power in pre-training and post-training phases for competitive performance. We summarize our practical lessons and design recommendations that we hope will provide actionable insights for the broader embodied AI community when adapting powerful foundation models to complex embodied scenarios.
Are We Ready for RL in Text-to-3D Generation? A Progressive Investigation
Dec 11, 2025Reinforcement learning (RL), earlier proven to be effective in large language and multi-modal models, has been successfully extended to enhance 2D image generation recently. However, applying RL to 3D generation remains largely unexplored due to the higher spatial complexity of 3D objects, which require globally consistent geometry and fine-grained local textures. This makes 3D generation significantly sensitive to reward designs and RL algorithms. To address these challenges, we conduct the first systematic study of RL for text-to-3D autoregressive generation across several dimensions. (1) Reward designs: We evaluate reward dimensions and model choices, showing that alignment with human preference is crucial, and that general multi-modal models provide robust signal for 3D attributes. (2) RL algorithms: We study GRPO variants, highlighting the effectiveness of token-level optimization, and further investigate the scaling of training data and iterations. (3) Text-to-3D Benchmarks: Since existing benchmarks fail to measure implicit reasoning abilities in 3D generation models, we introduce MME-3DR. (4) Advanced RL paradigms: Motivated by the natural hierarchy of 3D generation, we propose Hi-GRPO, which optimizes the global-to-local hierarchical 3D generation through dedicated reward ensembles. Based on these insights, we develop AR3D-R1, the first RL-enhanced text-to-3D model, expert from coarse shape to texture refinement. We hope this study provides insights into RL-driven reasoning for 3D generation. Code is released at https://github.com/Ivan-Tang-3D/3DGen-R1.
F1: A Vision-Language-Action Model Bridging Understanding and Generation to Actions
Sep 09, 2025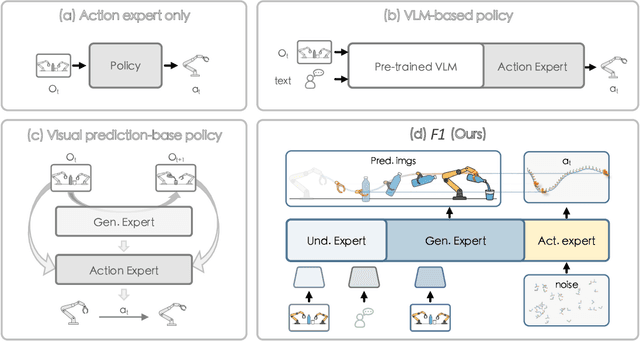

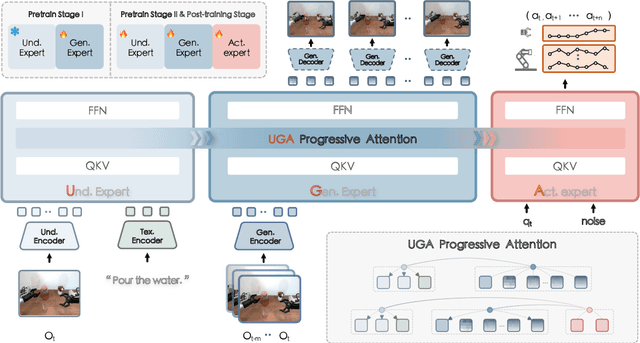

Executing language-conditioned tasks in dynamic visual environments remains a central challenge in embodied AI. Existing Vision-Language-Action (VLA) models predominantly adopt reactive state-to-action mappings, often leading to short-sighted behaviors and poor robustness in dynamic scenes. In this paper, we introduce F1, a pretrained VLA framework which integrates the visual foresight generation into decision-making pipeline. F1 adopts a Mixture-of-Transformer architecture with dedicated modules for perception, foresight generation, and control, thereby bridging understanding, generation, and actions. At its core, F1 employs a next-scale prediction mechanism to synthesize goal-conditioned visual foresight as explicit planning targets. By forecasting plausible future visual states, F1 reformulates action generation as a foresight-guided inverse dynamics problem, enabling actions that implicitly achieve visual goals. To endow F1 with robust and generalizable capabilities, we propose a three-stage training recipe on an extensive dataset comprising over 330k trajectories across 136 diverse tasks. This training scheme enhances modular reasoning and equips the model with transferable visual foresight, which is critical for complex and dynamic environments. Extensive evaluations on real-world tasks and simulation benchmarks demonstrate F1 consistently outperforms existing approaches, achieving substantial gains in both task success rate and generalization ability.
EmbodiedOneVision: Interleaved Vision-Text-Action Pretraining for General Robot Control
Aug 28, 2025The human ability to seamlessly perform multimodal reasoning and physical interaction in the open world is a core goal for general-purpose embodied intelligent systems. Recent vision-language-action (VLA) models, which are co-trained on large-scale robot and visual-text data, have demonstrated notable progress in general robot control. However, they still fail to achieve human-level flexibility in interleaved reasoning and interaction. In this work, introduce EO-Robotics, consists of EO-1 model and EO-Data1.5M dataset. EO-1 is a unified embodied foundation model that achieves superior performance in multimodal embodied reasoning and robot control through interleaved vision-text-action pre-training. The development of EO-1 is based on two key pillars: (i) a unified architecture that processes multimodal inputs indiscriminately (image, text, video, and action), and (ii) a massive, high-quality multimodal embodied reasoning dataset, EO-Data1.5M, which contains over 1.5 million samples with emphasis on interleaved vision-text-action comprehension. EO-1 is trained through synergies between auto-regressive decoding and flow matching denoising on EO-Data1.5M, enabling seamless robot action generation and multimodal embodied reasoning. Extensive experiments demonstrate the effectiveness of interleaved vision-text-action learning for open-world understanding and generalization, validated through a variety of long-horizon, dexterous manipulation tasks across multiple embodiments. This paper details the architecture of EO-1, the data construction strategy of EO-Data1.5M, and the training methodology, offering valuable insights for developing advanced embodied foundation models.
Hume: Introducing System-2 Thinking in Visual-Language-Action Model
May 29, 2025


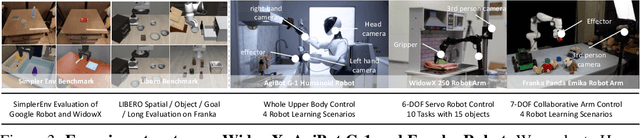
Humans practice slow thinking before performing actual actions when handling complex tasks in the physical world. This thinking paradigm, recently, has achieved remarkable advancement in boosting Large Language Models (LLMs) to solve complex tasks in digital domains. However, the potential of slow thinking remains largely unexplored for robotic foundation models interacting with the physical world. In this work, we propose Hume: a dual-system Vision-Language-Action (VLA) model with value-guided System-2 thinking and cascaded action denoising, exploring human-like thinking capabilities of Vision-Language-Action models for dexterous robot control. System 2 of Hume implements value-Guided thinking by extending a Vision-Language-Action Model backbone with a novel value-query head to estimate the state-action value of predicted actions. The value-guided thinking is conducted by repeat sampling multiple action candidates and selecting one according to state-action value. System 1 of Hume is a lightweight reactive visuomotor policy that takes System 2 selected action and performs cascaded action denoising for dexterous robot control. At deployment time, System 2 performs value-guided thinking at a low frequency while System 1 asynchronously receives the System 2 selected action candidate and predicts fluid actions in real time. We show that Hume outperforms the existing state-of-the-art Vision-Language-Action models across multiple simulation benchmark and real-robot deployments.
Revisiting Multi-Agent World Modeling from a Diffusion-Inspired Perspective
May 27, 2025



World models have recently attracted growing interest in Multi-Agent Reinforcement Learning (MARL) due to their ability to improve sample efficiency for policy learning. However, accurately modeling environments in MARL is challenging due to the exponentially large joint action space and highly uncertain dynamics inherent in multi-agent systems. To address this, we reduce modeling complexity by shifting from jointly modeling the entire state-action transition dynamics to focusing on the state space alone at each timestep through sequential agent modeling. Specifically, our approach enables the model to progressively resolve uncertainty while capturing the structured dependencies among agents, providing a more accurate representation of how agents influence the state. Interestingly, this sequential revelation of agents' actions in a multi-agent system aligns with the reverse process in diffusion models--a class of powerful generative models known for their expressiveness and training stability compared to autoregressive or latent variable models. Leveraging this insight, we develop a flexible and robust world model for MARL using diffusion models. Our method, Diffusion-Inspired Multi-Agent world model (DIMA), achieves state-of-the-art performance across multiple multi-agent control benchmarks, significantly outperforming prior world models in terms of final return and sample efficiency, including MAMuJoCo and Bi-DexHands. DIMA establishes a new paradigm for constructing multi-agent world models, advancing the frontier of MARL research.
Think Small, Act Big: Primitive Prompt Learning for Lifelong Robot Manipulation
Apr 01, 2025Building a lifelong robot that can effectively leverage prior knowledge for continuous skill acquisition remains significantly challenging. Despite the success of experience replay and parameter-efficient methods in alleviating catastrophic forgetting problem, naively applying these methods causes a failure to leverage the shared primitives between skills. To tackle these issues, we propose Primitive Prompt Learning (PPL), to achieve lifelong robot manipulation via reusable and extensible primitives. Within our two stage learning scheme, we first learn a set of primitive prompts to represent shared primitives through multi-skills pre-training stage, where motion-aware prompts are learned to capture semantic and motion shared primitives across different skills. Secondly, when acquiring new skills in lifelong span, new prompts are appended and optimized with frozen pretrained prompts, boosting the learning via knowledge transfer from old skills to new ones. For evaluation, we construct a large-scale skill dataset and conduct extensive experiments in both simulation and real-world tasks, demonstrating PPL's superior performance over state-of-the-art methods.
Uni$\textbf{F}^2$ace: Fine-grained Face Understanding and Generation with Unified Multimodal Models
Mar 11, 2025


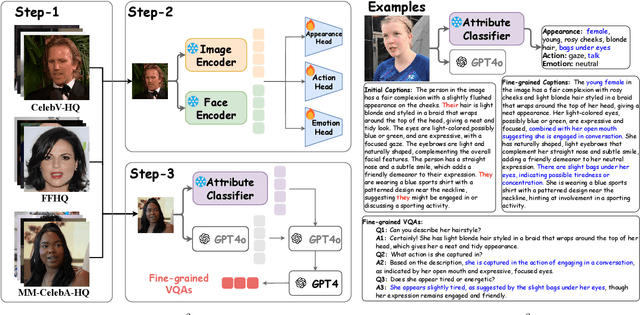
Unified multimodal models (UMMs) have emerged as a powerful paradigm in foundational computer vision research, demonstrating significant potential in both image understanding and generation. However, existing research in the face domain primarily focuses on $\textbf{coarse}$ facial attribute understanding, with limited capacity to handle $\textbf{fine-grained}$ facial attributes and without addressing generation capabilities. To overcome these limitations, we propose Uni$\textbf{F}^2$ace, the first UMM tailored specifically for fine-grained face understanding and generation. In general, we train Uni$\textbf{F}^2$ace on a self-constructed, specialized dataset utilizing two mutually beneficial diffusion techniques and a two-level mixture-of-experts architecture. Specifically, we first build a large-scale facial dataset, Uni$\textbf{F}^2$ace-130K, which contains 130K image-text pairs with one million question-answering pairs that span a wide range of facial attributes. Second, we establish a theoretical connection between discrete diffusion score matching and masked generative models, optimizing both evidence lower bounds simultaneously, which significantly improves the model's ability to synthesize facial details. Finally, we introduce both token-level and sequence-level mixture-of-experts, enabling efficient fine-grained representation learning for both understanding and generation tasks. Extensive experiments on Uni$\textbf{F}^2$ace-130K demonstrate that Uni$\textbf{F}^2$ace outperforms existing UMMs and generative models, achieving superior performance across both understanding and generation tasks.
Exploring the Potential of Encoder-free Architectures in 3D LMMs
Feb 13, 2025



Encoder-free architectures have been preliminarily explored in the 2D visual domain, yet it remains an open question whether they can be effectively applied to 3D understanding scenarios. In this paper, we present the first comprehensive investigation into the potential of encoder-free architectures to overcome the challenges of encoder-based 3D Large Multimodal Models (LMMs). These challenges include the failure to adapt to varying point cloud resolutions and the point features from the encoder not meeting the semantic needs of Large Language Models (LLMs). We identify key aspects for 3D LMMs to remove the encoder and enable the LLM to assume the role of the 3D encoder: 1) We propose the LLM-embedded Semantic Encoding strategy in the pre-training stage, exploring the effects of various point cloud self-supervised losses. And we present the Hybrid Semantic Loss to extract high-level semantics. 2) We introduce the Hierarchical Geometry Aggregation strategy in the instruction tuning stage. This incorporates inductive bias into the LLM early layers to focus on the local details of the point clouds. To the end, we present the first Encoder-free 3D LMM, ENEL. Our 7B model rivals the current state-of-the-art model, ShapeLLM-13B, achieving 55.0%, 50.92%, and 42.7% on the classification, captioning, and VQA tasks, respectively. Our results demonstrate that the encoder-free architecture is highly promising for replacing encoder-based architectures in the field of 3D understanding. The code is released at https://github.com/Ivan-Tang-3D/ENEL
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Jan 27, 2025



In this paper, we claim that spatial understanding is the keypoint in robot manipulation, and propose SpatialVLA to explore effective spatial representations for the robot foundation model. Specifically, we introduce Ego3D Position Encoding to inject 3D information into the input observations of the visual-language-action model, and propose Adaptive Action Grids to represent spatial robot movement actions with adaptive discretized action grids, facilitating learning generalizable and transferrable spatial action knowledge for cross-robot control. SpatialVLA is first pre-trained on top of a vision-language model with 1.1 Million real-world robot episodes, to learn a generalist manipulation policy across multiple robot environments and tasks. After pre-training, SpatialVLA is directly applied to perform numerous tasks in a zero-shot manner. The superior results in both simulation and real-world robots demonstrate its advantage of inferring complex robot motion trajectories and its strong in-domain multi-task generalization ability. We further show the proposed Adaptive Action Grids offer a new and effective way to fine-tune the pre-trained SpatialVLA model for new simulation and real-world setups, where the pre-learned action grids are re-discretized to capture robot-specific spatial action movements of new setups. The superior results from extensive evaluations demonstrate the exceptional in-distribution generalization and out-of-distribution adaptation capability, highlighting the crucial benefit of the proposed spatial-aware representations for generalist robot policy learning. All the details and codes will be open-sourced.