 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGGT-Edit: Feed-forward Native 3D Scene Editing with Residual Field Prediction
May 14, 2026High-quality 3D scene reconstruction has recently advanced toward generalizable feed-forward architectures, enabling the generation of complex environments in a single forward pass. However, despite their strong performance in static scene perception, these models remain limited in responding to dynamic human instructions, which restricts their use in interactive applications. Existing editing methods typically rely on a 2D-lifting strategy, where individual views are edited independently and then lifted back into 3D space. This indirect pipeline often leads to blurry textures and inconsistent geometry, as 2D editors lack the spatial awareness required to preserve structure across viewpoints. To address these limitations, we propose VGGT-Edit, a feed-forward framework for text-conditioned native 3D scene editing. VGGT-Edit introduces depth-synchronized text injection to align semantic guidance with the backbone's spatial poses, ensuring stable instruction grounding. This semantic signal is then processed by a residual transformation head, which directly predicts 3D geometric displacements to deform the scene while preserving background stability. To ensure high-fidelity results, we supervise the framework with a multi-term objective function that enforces geometric accuracy and cross-view consistency. We also construct the DeltaScene Dataset, a large-scale dataset generated through an automated pipeline with 3D agreement filtering to ensure ground-truth quality. Experiments show that VGGT-Edit substantially outperforms 2D-lifting baselines, producing sharper object details, stronger multi-view consistency, and near-instant inference speed.
OpenWorldLib: A Unified Codebase and Definition of Advanced World Models
Apr 06, 2026World models have garnered significant attention as a promising research direction in artificial intelligence, yet a clear and unified definition remains lacking. In this paper, we introduce OpenWorldLib, a comprehensive and standardized inference framework for Advanced World Models. Drawing on the evolution of world models, we propose a clear definition: a world model is a model or framework centered on perception, equipped with interaction and long-term memory capabilities, for understanding and predicting the complex world. We further systematically categorize the essential capabilities of world models. Based on this definition, OpenWorldLib integrates models across different tasks within a unified framework, enabling efficient reuse and collaborative inference. Finally, we present additional reflections and analyses on potential future directions for world model research. Code link: https://github.com/OpenDCAI/OpenWorldLib
Research on World Models Is Not Merely Injecting World Knowledge into Specific Tasks
Feb 02, 2026World models have emerged as a critical frontier in AI research, aiming to enhance large models by infusing them with physical dynamics and world knowledge. The core objective is to enable agents to understand, predict, and interact with complex environments. However, current research landscape remains fragmented, with approaches predominantly focused on injecting world knowledge into isolated tasks, such as visual prediction, 3D estimation, or symbol grounding, rather than establishing a unified definition or framework. While these task-specific integrations yield performance gains, they often lack the systematic coherence required for holistic world understanding. In this paper, we analyze the limitations of such fragmented approaches and propose a unified design specification for world models. We suggest that a robust world model should not be a loose collection of capabilities but a normative framework that integrally incorporates interaction, perception, symbolic reasoning, and spatial representation. This work aims to provide a structured perspective to guide future research toward more general, robust, and principled models of the world.
Are We Ready for RL in Text-to-3D Generation? A Progressive Investigation
Dec 11, 2025Reinforcement learning (RL), earlier proven to be effective in large language and multi-modal models, has been successfully extended to enhance 2D image generation recently. However, applying RL to 3D generation remains largely unexplored due to the higher spatial complexity of 3D objects, which require globally consistent geometry and fine-grained local textures. This makes 3D generation significantly sensitive to reward designs and RL algorithms. To address these challenges, we conduct the first systematic study of RL for text-to-3D autoregressive generation across several dimensions. (1) Reward designs: We evaluate reward dimensions and model choices, showing that alignment with human preference is crucial, and that general multi-modal models provide robust signal for 3D attributes. (2) RL algorithms: We study GRPO variants, highlighting the effectiveness of token-level optimization, and further investigate the scaling of training data and iterations. (3) Text-to-3D Benchmarks: Since existing benchmarks fail to measure implicit reasoning abilities in 3D generation models, we introduce MME-3DR. (4) Advanced RL paradigms: Motivated by the natural hierarchy of 3D generation, we propose Hi-GRPO, which optimizes the global-to-local hierarchical 3D generation through dedicated reward ensembles. Based on these insights, we develop AR3D-R1, the first RL-enhanced text-to-3D model, expert from coarse shape to texture refinement. We hope this study provides insights into RL-driven reasoning for 3D generation. Code is released at https://github.com/Ivan-Tang-3D/3DGen-R1.
REVISION:Reflective Intent Mining and Online Reasoning Auxiliary for E-commerce Visual Search System Optimization
Oct 26, 2025In Taobao e-commerce visual search, user behavior analysis reveals a large proportion of no-click requests, suggesting diverse and implicit user intents. These intents are expressed in various forms and are difficult to mine and discover, thereby leading to the limited adaptability and lag in platform strategies. This greatly restricts users' ability to express diverse intents and hinders the scalability of the visual search system. This mismatch between user implicit intent expression and system response defines the User-SearchSys Intent Discrepancy. To alleviate the issue, we propose a novel framework REVISION. This framework integrates offline reasoning mining with online decision-making and execution, enabling adaptive strategies to solve implicit user demands. In the offline stage, we construct a periodic pipeline to mine discrepancies from historical no-click requests. Leveraging large models, we analyze implicit intent factors and infer optimal suggestions by jointly reasoning over query and product metadata. These inferred suggestions serve as actionable insights for refining platform strategies. In the online stage, REVISION-R1-3B, trained on the curated offline data, performs holistic analysis over query images and associated historical products to generate optimization plans and adaptively schedule strategies across the search pipeline. Our framework offers a streamlined paradigm for integrating large models with traditional search systems, enabling end-to-end intelligent optimization across information aggregation and user interaction. Experimental results demonstrate that our approach improves the efficiency of implicit intent mining from large-scale search logs and significantly reduces the no-click rate.
Hume: Introducing System-2 Thinking in Visual-Language-Action Model
May 29, 2025


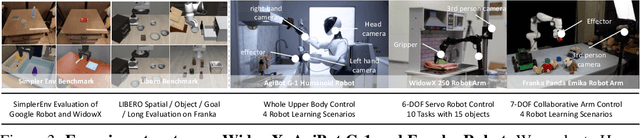
Humans practice slow thinking before performing actual actions when handling complex tasks in the physical world. This thinking paradigm, recently, has achieved remarkable advancement in boosting Large Language Models (LLMs) to solve complex tasks in digital domains. However, the potential of slow thinking remains largely unexplored for robotic foundation models interacting with the physical world. In this work, we propose Hume: a dual-system Vision-Language-Action (VLA) model with value-guided System-2 thinking and cascaded action denoising, exploring human-like thinking capabilities of Vision-Language-Action models for dexterous robot control. System 2 of Hume implements value-Guided thinking by extending a Vision-Language-Action Model backbone with a novel value-query head to estimate the state-action value of predicted actions. The value-guided thinking is conducted by repeat sampling multiple action candidates and selecting one according to state-action value. System 1 of Hume is a lightweight reactive visuomotor policy that takes System 2 selected action and performs cascaded action denoising for dexterous robot control. At deployment time, System 2 performs value-guided thinking at a low frequency while System 1 asynchronously receives the System 2 selected action candidate and predicts fluid actions in real time. We show that Hume outperforms the existing state-of-the-art Vision-Language-Action models across multiple simulation benchmark and real-robot deployments.
EvoMoE: Expert Evolution in Mixture of Experts for Multimodal Large Language Models
May 28, 2025Recent advancements have shown that the Mixture of Experts (MoE) approach significantly enhances the capacity of large language models (LLMs) and improves performance on downstream tasks. Building on these promising results, multi-modal large language models (MLLMs) have increasingly adopted MoE techniques. However, existing multi-modal MoE tuning methods typically face two key challenges: expert uniformity and router rigidity. Expert uniformity occurs because MoE experts are often initialized by simply replicating the FFN parameters from LLMs, leading to homogenized expert functions and weakening the intended diversification of the MoE architecture. Meanwhile, router rigidity stems from the prevalent use of static linear routers for expert selection, which fail to distinguish between visual and textual tokens, resulting in similar expert distributions for image and text. To address these limitations, we propose EvoMoE, an innovative MoE tuning framework. EvoMoE introduces a meticulously designed expert initialization strategy that progressively evolves multiple robust experts from a single trainable expert, a process termed expert evolution that specifically targets severe expert homogenization. Furthermore, we introduce the Dynamic Token-aware Router (DTR), a novel routing mechanism that allocates input tokens to appropriate experts based on their modality and intrinsic token values. This dynamic routing is facilitated by hypernetworks, which dynamically generate routing weights tailored for each individual token. Extensive experiments demonstrate that EvoMoE significantly outperforms other sparse MLLMs across a variety of multi-modal benchmarks, including MME, MMBench, TextVQA, and POPE. Our results highlight the effectiveness of EvoMoE in enhancing the performance of MLLMs by addressing the critical issues of expert uniformity and router rigidity.
AutoMat: Enabling Automated Crystal Structure Reconstruction from Microscopy via Agentic Tool Use
May 19, 2025



Machine learning-based interatomic potentials and force fields depend critically on accurate atomic structures, yet such data are scarce due to the limited availability of experimentally resolved crystals. Although atomic-resolution electron microscopy offers a potential source of structural data, converting these images into simulation-ready formats remains labor-intensive and error-prone, creating a bottleneck for model training and validation. We introduce AutoMat, an end-to-end, agent-assisted pipeline that automatically transforms scanning transmission electron microscopy (STEM) images into atomic crystal structures and predicts their physical properties. AutoMat combines pattern-adaptive denoising, physics-guided template retrieval, symmetry-aware atomic reconstruction, fast relaxation and property prediction via MatterSim, and coordinated orchestration across all stages. We propose the first dedicated STEM2Mat-Bench for this task and evaluate performance using lattice RMSD, formation energy MAE, and structure-matching success rate. By orchestrating external tool calls, AutoMat enables a text-only LLM to outperform vision-language models in this domain, achieving closed-loop reasoning throughout the pipeline. In large-scale experiments over 450 structure samples, AutoMat substantially outperforms existing multimodal large language models and tools. These results validate both AutoMat and STEM2Mat-Bench, marking a key step toward bridging microscopy and atomistic simulation in materials science.The code and dataset are publicly available at https://github.com/yyt-2378/AutoMat and https://huggingface.co/datasets/yaotianvector/STEM2Mat.
AerialVG: A Challenging Benchmark for Aerial Visual Grounding by Exploring Positional Relations
Apr 10, 2025Visual grounding (VG) aims to localize target objects in an image based on natural language descriptions. In this paper, we propose AerialVG, a new task focusing on visual grounding from aerial views. Compared to traditional VG, AerialVG poses new challenges, \emph{e.g.}, appearance-based grounding is insufficient to distinguish among multiple visually similar objects, and positional relations should be emphasized. Besides, existing VG models struggle when applied to aerial imagery, where high-resolution images cause significant difficulties. To address these challenges, we introduce the first AerialVG dataset, consisting of 5K real-world aerial images, 50K manually annotated descriptions, and 103K objects. Particularly, each annotation in AerialVG dataset contains multiple target objects annotated with relative spatial relations, requiring models to perform comprehensive spatial reasoning. Furthermore, we propose an innovative model especially for the AerialVG task, where a Hierarchical Cross-Attention is devised to focus on target regions, and a Relation-Aware Grounding module is designed to infer positional relations. Experimental results validate the effectiveness of our dataset and method, highlighting the importance of spatial reasoning in aerial visual grounding. The code and dataset will be released.
OpenFly: A Versatile Toolchain and Large-scale Benchmark for Aerial Vision-Language Navigation
Feb 25, 2025Vision-Language Navigation (VLN) aims to guide agents through an environment by leveraging both language instructions and visual cues, playing a pivotal role in embodied AI. Indoor VLN has been extensively studied, whereas outdoor aerial VLN remains underexplored. The potential reason is that outdoor aerial view encompasses vast areas, making data collection more challenging, which results in a lack of benchmarks. To address this problem, we propose OpenFly, a platform comprising a versatile toolchain and large-scale benchmark for aerial VLN. Firstly, we develop a highly automated toolchain for data collection, enabling automatic point cloud acquisition, scene semantic segmentation, flight trajectory creation, and instruction generation. Secondly, based on the toolchain, we construct a large-scale aerial VLN dataset with 100k trajectories, covering diverse heights and lengths across 18 scenes. The corresponding visual data are generated using various rendering engines and advanced techniques, including Unreal Engine, GTA V, Google Earth, and 3D Gaussian Splatting (3D GS). All data exhibit high visual quality. Particularly, 3D GS supports real-to-sim rendering, further enhancing the realism of the dataset. Thirdly, we propose OpenFly-Agent, a keyframe-aware VLN model, which takes language instructions, current observations, and historical keyframes as input, and outputs flight actions directly. Extensive analyses and experiments are conducted, showcasing the superiority of our OpenFly platform and OpenFly-Agent. The toolchain, dataset, and codes will be open-sourced.