 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterleaveThinker: Reinforcing Agentic Interleaved Generation
Jun 11, 2026Recent image generators have demonstrated impressive photorealism and instruction-following capabilities in single-image generation and editing. However, constrained by their architectures, they cannot achieve interleaved generation (text-image sequence), which has crucial applications in visual narratives, guidance, and embodied manipulation. Even the latest open-source Unified Multimodal Models (UMMs) exhibit limited performance in this regard. In this paper, we introduce InterleaveThinker, the first multi-agent pipeline designed to endow any existing image generator with interleaved generation capabilities. Specifically, we employ a planner agent to organize the image-text input sequence, instructing the image generator on the required execution at each step. Subsequently, we introduce a critic agent to evaluate the generator's outputs, identify samples that deviate from the planned instructions, and refine the instructions for regeneration. To implement this pipeline, we construct the Interleave-Planner-SFT-80k and Interleave-Critic-SFT-112k to perform a format cold-start. Then we develop Interleave-Critic-RL-13k to reinforce the step-wise instruction correction capability within a generation trajectory using GRPO. Since a single interleaved generation trajectory may involve over 25 generator calls, optimizing the entire trajectory is computationally impractical. Therefore, we propose accuracy reward and step-wise reward, allowing single-step RL to effectively guide the entire generation trajectory. The results show that InterleaveThinker improves performance across various image generators. On interleaved generation benchmarks, it achieves performance comparable to Nano Banana and GPT-5. Surprisingly, it also significantly enhances the base model on reasoning-based benchmarks; for example, on 4-step FLUX.2-klein, we observe substantial gains on WISE and RISE.
Generalized-CVO: Fast and Correspondence-Free Local Point Cloud Registration with Second Order Riemannian Optimization
Jun 08, 2026We propose a fast and correspondence-free local point cloud registration method that leverages geometric surface structure and reproducing kernel Hilbert space (RKHS) embeddings. The method represents point clouds as continuous functions with point-wise anisotropic kernels that encode local geometry. This formulation improves alignment along surface normals while relaxing alignment along tangential directions. To solve the resulting registration problem, we propose a second-order on-manifold optimization scheme with approximate Riemannian Hessians, achieving a speedup of up to 10x over the first-order solvers used in prior correspondence-free RKHS-based methods. We demonstrate improved frame-to-frame LiDAR and RGB-D tracking accuracy across diverse indoor and outdoor datasets. On a LiDAR tracking registration task in the driving domain, we achieve a reduction of $>55\%$ in both translational and rotational drift in challenging feature-sparse environments. On object registration benchmarks, we show improved robustness over ICP-based methods and further gains when refining global initialization, particularly under moderate misalignment.
Vision-Conditioned Variational Bayesian Last Layer Dynamics Models
Jan 16, 2026Agile control of robotic systems often requires anticipating how the environment affects system behavior. For example, a driver must perceive the road ahead to anticipate available friction and plan actions accordingly. Achieving such proactive adaptation within autonomous frameworks remains a challenge, particularly under rapidly changing conditions. Traditional modeling approaches often struggle to capture abrupt variations in system behavior, while adaptive methods are inherently reactive and may adapt too late to ensure safety. We propose a vision-conditioned variational Bayesian last-layer dynamics model that leverages visual context to anticipate changes in the environment. The model first learns nominal vehicle dynamics and is then fine-tuned with feature-wise affine transformations of latent features, enabling context-aware dynamics prediction. The resulting model is integrated into an optimal controller for vehicle racing. We validate our method on a Lexus LC500 racing through water puddles. With vision-conditioning, the system completed all 12 attempted laps under varying conditions. In contrast, all baselines without visual context consistently lost control, demonstrating the importance of proactive dynamics adaptation in high-performance applications.
Are We Ready for RL in Text-to-3D Generation? A Progressive Investigation
Dec 11, 2025Reinforcement learning (RL), earlier proven to be effective in large language and multi-modal models, has been successfully extended to enhance 2D image generation recently. However, applying RL to 3D generation remains largely unexplored due to the higher spatial complexity of 3D objects, which require globally consistent geometry and fine-grained local textures. This makes 3D generation significantly sensitive to reward designs and RL algorithms. To address these challenges, we conduct the first systematic study of RL for text-to-3D autoregressive generation across several dimensions. (1) Reward designs: We evaluate reward dimensions and model choices, showing that alignment with human preference is crucial, and that general multi-modal models provide robust signal for 3D attributes. (2) RL algorithms: We study GRPO variants, highlighting the effectiveness of token-level optimization, and further investigate the scaling of training data and iterations. (3) Text-to-3D Benchmarks: Since existing benchmarks fail to measure implicit reasoning abilities in 3D generation models, we introduce MME-3DR. (4) Advanced RL paradigms: Motivated by the natural hierarchy of 3D generation, we propose Hi-GRPO, which optimizes the global-to-local hierarchical 3D generation through dedicated reward ensembles. Based on these insights, we develop AR3D-R1, the first RL-enhanced text-to-3D model, expert from coarse shape to texture refinement. We hope this study provides insights into RL-driven reasoning for 3D generation. Code is released at https://github.com/Ivan-Tang-3D/3DGen-R1.
Semantic Property Maps for Driving Applications
Nov 13, 2025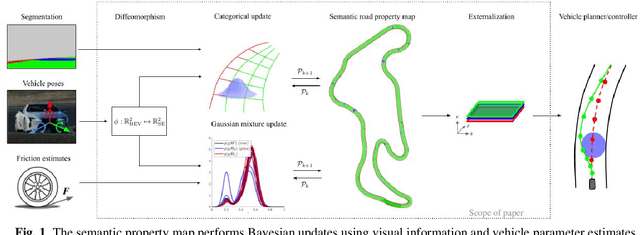


We consider the problem of estimating the parameters of a vehicle dynamics model for predictive control in driving applications. Instead of solely using the instantaneous parameters estimated from the vehicle signals, we combine this with cameras and update a probabilistic map with parameter estimates and semantic information using Bayesian moment matching. Key to this approach is the map representation, which is constructed with conjugate priors to the measurement likelihoods and defined in the same path coordinates as the vehicle controller, such that the map can be externalized to provide a local representation of the parameter likelihoods that vary in space. The result is a spatial map of vehicle parameters adapted online to enhance the driving control system. We provide theoretical guarantees on the smoothness of relevant parameter likelihood statistics as a function of space, which is critical for their use in predictive control.
CrossLMM: Decoupling Long Video Sequences from LMMs via Dual Cross-Attention Mechanisms
May 22, 2025The advent of Large Multimodal Models (LMMs) has significantly enhanced Large Language Models (LLMs) to process and interpret diverse data modalities (e.g., image and video). However, as input complexity increases, particularly with long video sequences, the number of required tokens has grown significantly, leading to quadratically computational costs. This has made the efficient compression of video tokens in LMMs, while maintaining performance integrity, a pressing research challenge. In this paper, we introduce CrossLMM, decoupling long video sequences from LMMs via a dual cross-attention mechanism, which substantially reduces visual token quantity with minimal performance degradation. Specifically, we first implement a significant token reduction from pretrained visual encoders through a pooling methodology. Then, within LLM layers, we employ a visual-to-visual cross-attention mechanism, wherein the pooled visual tokens function as queries against the original visual token set. This module enables more efficient token utilization while retaining fine-grained informational fidelity. In addition, we introduce a text-to-visual cross-attention mechanism, for which the text tokens are enhanced through interaction with the original visual tokens, enriching the visual comprehension of the text tokens. Comprehensive empirical evaluation demonstrates that our approach achieves comparable or superior performance across diverse video-based LMM benchmarks, despite utilizing substantially fewer computational resources.
SciVerse: Unveiling the Knowledge Comprehension and Visual Reasoning of LMMs on Multi-modal Scientific Problems
Mar 13, 2025The rapid advancement of Large Multi-modal Models (LMMs) has enabled their application in scientific problem-solving, yet their fine-grained capabilities remain under-explored. In this paper, we introduce SciVerse, a multi-modal scientific evaluation benchmark to thoroughly assess LMMs across 5,735 test instances in five distinct versions. We aim to investigate three key dimensions of LMMs: scientific knowledge comprehension, multi-modal content interpretation, and Chain-of-Thought (CoT) reasoning. To unveil whether LMMs possess sufficient scientific expertise, we first transform each problem into three versions containing different levels of knowledge required for solving, i.e., Knowledge-free, -lite, and -rich. Then, to explore how LMMs interpret multi-modal scientific content, we annotate another two versions, i.e., Vision-rich and -only, marking more question information from texts to diagrams. Comparing the results of different versions, SciVerse systematically examines the professional knowledge stock and visual perception skills of LMMs in scientific domains. In addition, to rigorously assess CoT reasoning, we propose a new scientific CoT evaluation strategy, conducting a step-wise assessment on knowledge and logical errors in model outputs. Our extensive evaluation of different LMMs on SciVerse reveals critical limitations in their scientific proficiency and provides new insights into future developments. Project page: https://sciverse-cuhk.github.io
Exploring the Potential of Encoder-free Architectures in 3D LMMs
Feb 13, 2025



Encoder-free architectures have been preliminarily explored in the 2D visual domain, yet it remains an open question whether they can be effectively applied to 3D understanding scenarios. In this paper, we present the first comprehensive investigation into the potential of encoder-free architectures to overcome the challenges of encoder-based 3D Large Multimodal Models (LMMs). These challenges include the failure to adapt to varying point cloud resolutions and the point features from the encoder not meeting the semantic needs of Large Language Models (LLMs). We identify key aspects for 3D LMMs to remove the encoder and enable the LLM to assume the role of the 3D encoder: 1) We propose the LLM-embedded Semantic Encoding strategy in the pre-training stage, exploring the effects of various point cloud self-supervised losses. And we present the Hybrid Semantic Loss to extract high-level semantics. 2) We introduce the Hierarchical Geometry Aggregation strategy in the instruction tuning stage. This incorporates inductive bias into the LLM early layers to focus on the local details of the point clouds. To the end, we present the first Encoder-free 3D LMM, ENEL. Our 7B model rivals the current state-of-the-art model, ShapeLLM-13B, achieving 55.0%, 50.92%, and 42.7% on the classification, captioning, and VQA tasks, respectively. Our results demonstrate that the encoder-free architecture is highly promising for replacing encoder-based architectures in the field of 3D understanding. The code is released at https://github.com/Ivan-Tang-3D/ENEL
SLAM assisted 3D tracking system for laparoscopic surgery
Sep 18, 2024



A major limitation of minimally invasive surgery is the difficulty in accurately locating the internal anatomical structures of the target organ due to the lack of tactile feedback and transparency. Augmented reality (AR) offers a promising solution to overcome this challenge. Numerous studies have shown that combining learning-based and geometric methods can achieve accurate preoperative and intraoperative data registration. This work proposes a real-time monocular 3D tracking algorithm for post-registration tasks. The ORB-SLAM2 framework is adopted and modified for prior-based 3D tracking. The primitive 3D shape is used for fast initialization of the monocular SLAM. A pseudo-segmentation strategy is employed to separate the target organ from the background for tracking purposes, and the geometric prior of the 3D shape is incorporated as an additional constraint in the pose graph. Experiments from in-vivo and ex-vivo tests demonstrate that the proposed 3D tracking system provides robust 3D tracking and effectively handles typical challenges such as fast motion, out-of-field-of-view scenarios, partial visibility, and "organ-background" relative motion.
Correspondence-Free SE(3) Point Cloud Registration in RKHS via Unsupervised Equivariant Learning
Jul 29, 2024This paper introduces a robust unsupervised SE(3) point cloud registration method that operates without requiring point correspondences. The method frames point clouds as functions in a reproducing kernel Hilbert space (RKHS), leveraging SE(3)-equivariant features for direct feature space registration. A novel RKHS distance metric is proposed, offering reliable performance amidst noise, outliers, and asymmetrical data. An unsupervised training approach is introduced to effectively handle limited ground truth data, facilitating adaptation to real datasets. The proposed method outperforms classical and supervised methods in terms of registration accuracy on both synthetic (ModelNet40) and real-world (ETH3D) noisy, outlier-rich datasets. To our best knowledge, this marks the first instance of successful real RGB-D odometry data registration using an equivariant method. The code is available at {https://sites.google.com/view/eccv24-equivalign}