 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto Front Shape-Agnostic Pareto Set Learning in Multi-Objective Optimization
Aug 11, 2024Pareto set learning (PSL) is an emerging approach for acquiring the complete Pareto set of a multi-objective optimization problem. Existing methods primarily rely on the mapping of preference vectors in the objective space to Pareto optimal solutions in the decision space. However, the sampling of preference vectors theoretically requires prior knowledge of the Pareto front shape to ensure high performance of the PSL methods. Designing a sampling strategy of preference vectors is difficult since the Pareto front shape cannot be known in advance. To make Pareto set learning work effectively in any Pareto front shape, we propose a Pareto front shape-agnostic Pareto Set Learning (GPSL) that does not require the prior information about the Pareto front. The fundamental concept behind GPSL is to treat the learning of the Pareto set as a distribution transformation problem. Specifically, GPSL can transform an arbitrary distribution into the Pareto set distribution. We demonstrate that training a neural network by maximizing hypervolume enables the process of distribution transformation. Our proposed method can handle any shape of the Pareto front and learn the Pareto set without requiring prior knowledge. Experimental results show the high performance of our proposed method on diverse test problems compared with recent Pareto set learning algorithms.
* 7 pages
Evolutionary Preference Sampling for Pareto Set Learning
Apr 12, 2024Recently, Pareto Set Learning (PSL) has been proposed for learning the entire Pareto set using a neural network. PSL employs preference vectors to scalarize multiple objectives, facilitating the learning of mappings from preference vectors to specific Pareto optimal solutions. Previous PSL methods have shown their effectiveness in solving artificial multi-objective optimization problems (MOPs) with uniform preference vector sampling. The quality of the learned Pareto set is influenced by the sampling strategy of the preference vector, and the sampling of the preference vector needs to be decided based on the Pareto front shape. However, a fixed preference sampling strategy cannot simultaneously adapt the Pareto front of multiple MOPs. To address this limitation, this paper proposes an Evolutionary Preference Sampling (EPS) strategy to efficiently sample preference vectors. Inspired by evolutionary algorithms, we consider preference sampling as an evolutionary process to generate preference vectors for neural network training. We integrate the EPS strategy into five advanced PSL methods. Extensive experiments demonstrate that our proposed method has a faster convergence speed than baseline algorithms on 7 testing problems. Our implementation is available at https://github.com/rG223/EPS.
Data-Driven Preference Sampling for Pareto Front Learning
Apr 12, 2024Pareto front learning is a technique that introduces preference vectors in a neural network to approximate the Pareto front. Previous Pareto front learning methods have demonstrated high performance in approximating simple Pareto fronts. These methods often sample preference vectors from a fixed Dirichlet distribution. However, no fixed sampling distribution can be adapted to diverse Pareto fronts. Efficiently sampling preference vectors and accurately estimating the Pareto front is a challenge. To address this challenge, we propose a data-driven preference vector sampling framework for Pareto front learning. We utilize the posterior information of the objective functions to adjust the parameters of the sampling distribution flexibly. In this manner, the proposed method can sample preference vectors from the location of the Pareto front with a high probability. Moreover, we design the distribution of the preference vector as a mixture of Dirichlet distributions to improve the performance of the model in disconnected Pareto fronts. Extensive experiments validate the superiority of the proposed method compared with state-of-the-art algorithms.
RKHS-BA: A Semantic Correspondence-Free Multi-View Registration Framework with Global Tracking
Mar 02, 2024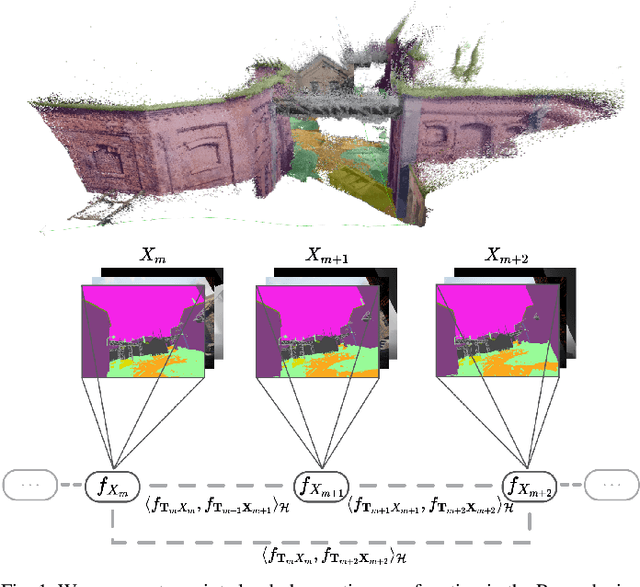
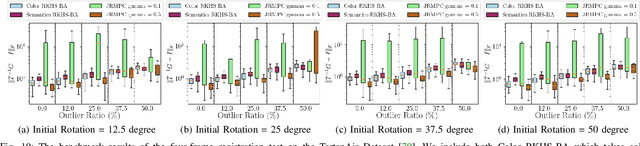
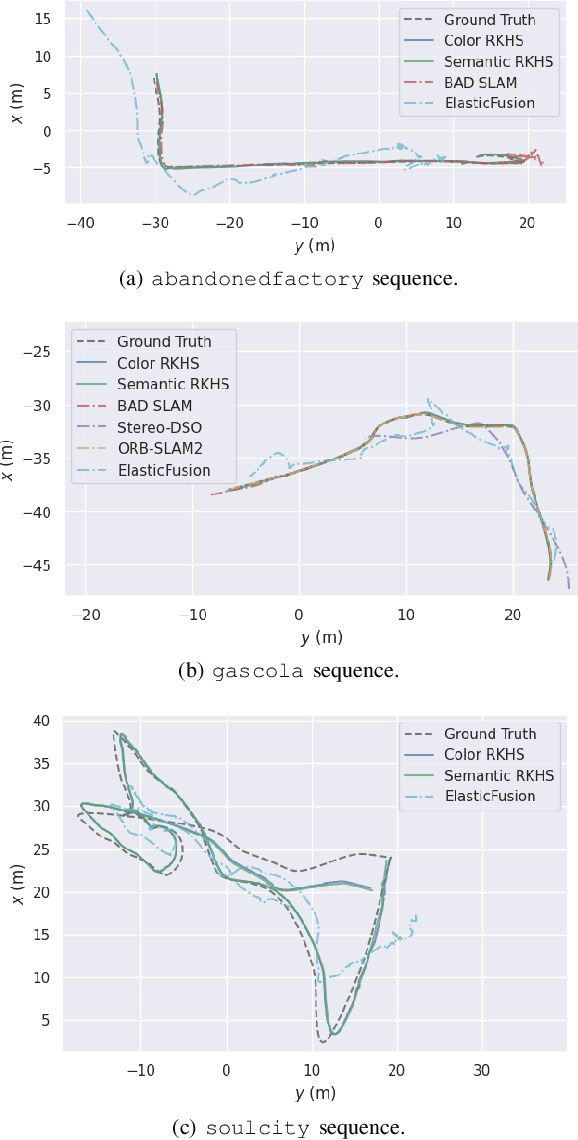

This work reports a novel Bundle Adjustment (BA) formulation using a Reproducing Kernel Hilbert Space (RKHS) representation called RKHS-BA. The proposed formulation is correspondence-free, enables the BA to use RGB-D/LiDAR and semantic labels in the optimization directly, and provides a generalization for the photometric loss function commonly used in direct methods. RKHS-BA can incorporate appearance and semantic labels within a continuous spatial-semantic functional representation that does not require optimization via image pyramids. We demonstrate its applications in sliding-window odometry and global LiDAR mapping, which show highly robust performance in extremely challenging scenes and the best trade-off of generalization and accuracy.
A Stronger Stitching Algorithm for Fisheye Images based on Deblurring and Registration
Jul 22, 2023Fisheye lens, which is suitable for panoramic imaging, has the prominent advantage of a large field of view and low cost. However, the fisheye image has a severe geometric distortion which may interfere with the stage of image registration and stitching. Aiming to resolve this drawback, we devise a stronger stitching algorithm for fisheye images by combining the traditional image processing method with deep learning. In the stage of fisheye image correction, we propose the Attention-based Nonlinear Activation Free Network (ANAFNet) to deblur fisheye images corrected by Zhang calibration method. Specifically, ANAFNet adopts the classical single-stage U-shaped architecture based on convolutional neural networks with soft-attention technique and it can restore a sharp image from a blurred image effectively. In the part of image registration, we propose the ORB-FREAK-GMS (OFG), a comprehensive image matching algorithm, to improve the accuracy of image registration. Experimental results demonstrate that panoramic images of superior quality stitching by fisheye images can be obtained through our method.
Detecting Adversarial Faces Using Only Real Face Self-Perturbations
May 04, 2023



Adversarial attacks aim to disturb the functionality of a target system by adding specific noise to the input samples, bringing potential threats to security and robustness when applied to facial recognition systems. Although existing defense techniques achieve high accuracy in detecting some specific adversarial faces (adv-faces), new attack methods especially GAN-based attacks with completely different noise patterns circumvent them and reach a higher attack success rate. Even worse, existing techniques require attack data before implementing the defense, making it impractical to defend newly emerging attacks that are unseen to defenders. In this paper, we investigate the intrinsic generality of adv-faces and propose to generate pseudo adv-faces by perturbing real faces with three heuristically designed noise patterns. We are the first to train an adv-face detector using only real faces and their self-perturbations, agnostic to victim facial recognition systems, and agnostic to unseen attacks. By regarding adv-faces as out-of-distribution data, we then naturally introduce a novel cascaded system for adv-face detection, which consists of training data self-perturbations, decision boundary regularization, and a max-pooling-based binary classifier focusing on abnormal local color aberrations. Experiments conducted on LFW and CelebA-HQ datasets with eight gradient-based and two GAN-based attacks validate that our method generalizes to a variety of unseen adversarial attacks.
Enabling surrogate-assisted evolutionary reinforcement learning via policy embedding
Jan 31, 2023



Evolutionary Reinforcement Learning (ERL) that applying Evolutionary Algorithms (EAs) to optimize the weight parameters of Deep Neural Network (DNN) based policies has been widely regarded as an alternative to traditional reinforcement learning methods. However, the evaluation of the iteratively generated population usually requires a large amount of computational time and can be prohibitively expensive, which may potentially restrict the applicability of ERL. Surrogate is often used to reduce the computational burden of evaluation in EAs. Unfortunately, in ERL, each individual of policy usually represents millions of weights parameters of DNN. This high-dimensional representation of policy has introduced a great challenge to the application of surrogates into ERL to speed up training. This paper proposes a PE-SAERL Framework to at the first time enable surrogate-assisted evolutionary reinforcement learning via policy embedding (PE). Empirical results on 5 Atari games show that the proposed method can perform more efficiently than the four state-of-the-art algorithms. The training process is accelerated up to 7x on tested games, comparing to its counterpart without the surrogate and PE.
Preselection via Classification: A Case Study on Evolutionary Multiobjective Optimization
Aug 03, 2017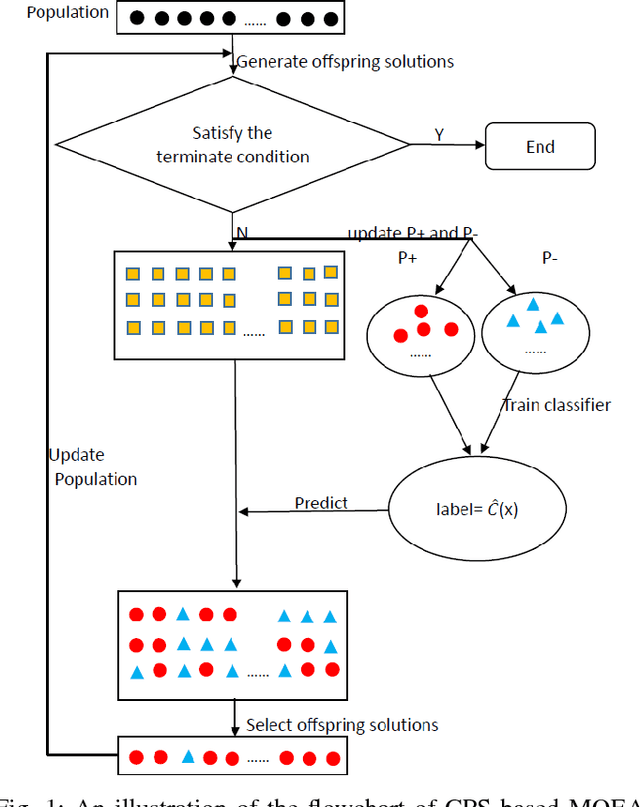
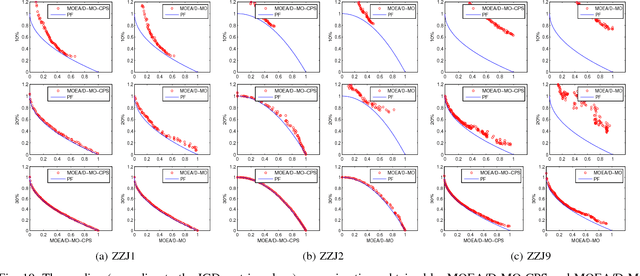

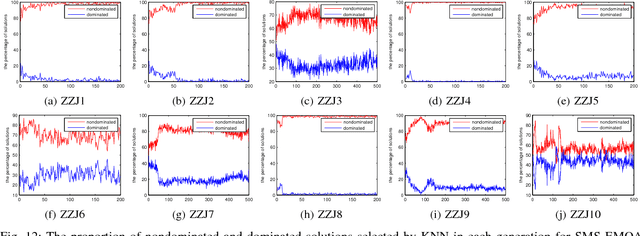
In evolutionary algorithms, a preselection operator aims to select the promising offspring solutions from a candidate offspring set. It is usually based on the estimated or real objective values of the candidate offspring solutions. In a sense, the preselection can be treated as a classification procedure, which classifies the candidate offspring solutions into promising ones and unpromising ones. Following this idea, we propose a classification based preselection (CPS) strategy for evolutionary multiobjective optimization. When applying classification based preselection, an evolutionary algorithm maintains two external populations (training data set) that consist of some selected good and bad solutions found so far; then it trains a classifier based on the training data set in each generation. Finally it uses the classifier to filter the unpromising candidate offspring solutions and choose a promising one from the generated candidate offspring set for each parent solution. In such cases, it is not necessary to estimate or evaluate the objective values of the candidate offspring solutions. The classification based preselection is applied to three state-of-the-art multiobjective evolutionary algorithms (MOEAs) and is empirically studied on two sets of test instances. The experimental results suggest that classification based preselection can successfully improve the performance of these MOEAs.