 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTK-Guided Implicit Neural Teaching
Nov 19, 2025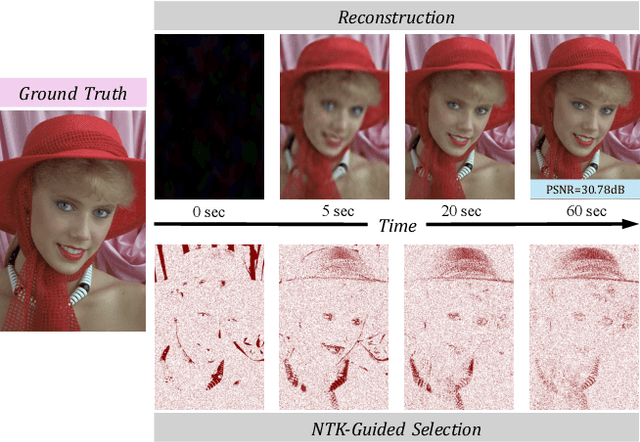
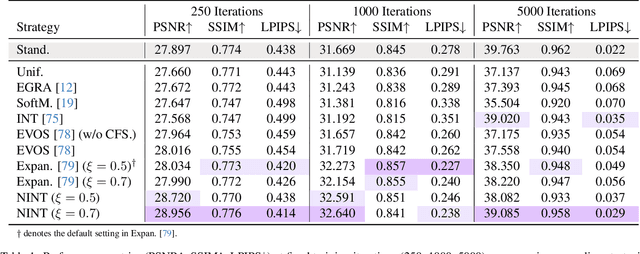
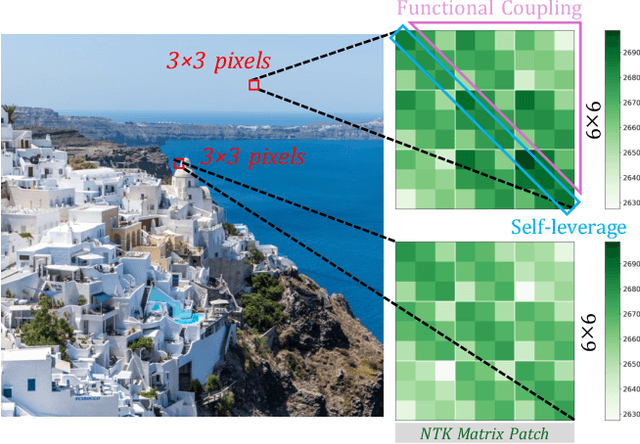
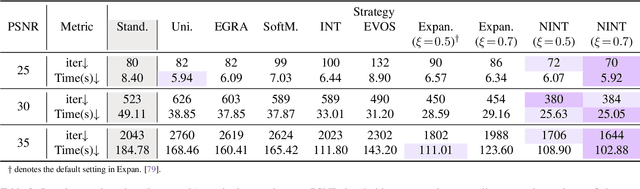
Implicit Neural Representations (INRs) parameterize continuous signals via multilayer perceptrons (MLPs), enabling compact, resolution-independent modeling for tasks like image, audio, and 3D reconstruction. However, fitting high-resolution signals demands optimizing over millions of coordinates, incurring prohibitive computational costs. To address it, we propose NTK-Guided Implicit Neural Teaching (NINT), which accelerates training by dynamically selecting coordinates that maximize global functional updates. Leveraging the Neural Tangent Kernel (NTK), NINT scores examples by the norm of their NTK-augmented loss gradients, capturing both fitting errors and heterogeneous leverage (self-influence and cross-coordinate coupling). This dual consideration enables faster convergence compared to existing methods. Through extensive experiments, we demonstrate that NINT significantly reduces training time by nearly half while maintaining or improving representation quality, establishing state-of-the-art acceleration among recent sampling-based strategies.
FedEMA: Federated Exponential Moving Averaging with Negative Entropy Regularizer in Autonomous Driving
May 01, 2025Street Scene Semantic Understanding (denoted as S3U) is a crucial but complex task for autonomous driving (AD) vehicles. Their inference models typically face poor generalization due to domain-shift. Federated Learning (FL) has emerged as a promising paradigm for enhancing the generalization of AD models through privacy-preserving distributed learning. However, these FL AD models face significant temporal catastrophic forgetting when deployed in dynamically evolving environments, where continuous adaptation causes abrupt erosion of historical knowledge. This paper proposes Federated Exponential Moving Average (FedEMA), a novel framework that addresses this challenge through two integral innovations: (I) Server-side model's historical fitting capability preservation via fusing current FL round's aggregation model and a proposed previous FL round's exponential moving average (EMA) model; (II) Vehicle-side negative entropy regularization to prevent FL models' possible overfitting to EMA-introduced temporal patterns. Above two strategies empower FedEMA a dual-objective optimization that balances model generalization and adaptability. In addition, we conduct theoretical convergence analysis for the proposed FedEMA. Extensive experiments both on Cityscapes dataset and Camvid dataset demonstrate FedEMA's superiority over existing approaches, showing 7.12% higher mean Intersection-over-Union (mIoU).
iMacSR: Intermediate Multi-Access Supervision and Regularization in Training Autonomous Driving Models
May 01, 2025Deep Learning (DL)-based street scene semantic understanding has become a cornerstone of autonomous driving (AD). DL model performance heavily relies on network depth. Specifically, deeper DL architectures yield better segmentation performance. However, as models grow deeper, traditional one-point supervision at the final layer struggles to optimize intermediate feature representations, leading to subpar training outcomes. To address this, we propose an intermediate Multi-access Supervision and Regularization (iMacSR) strategy. The proposed iMacSR introduces two novel components: (I) mutual information between latent features and ground truth as intermediate supervision loss ensures robust feature alignment at multiple network depths; and (II) negative entropy regularization on hidden features discourages overconfident predictions and mitigates overfitting. These intermediate terms are combined into the original final-layer training loss to form a unified optimization objective, enabling comprehensive optimization across the network hierarchy. The proposed iMacSR provides a robust framework for training deep AD architectures, advancing the performance of perception systems in real-world driving scenarios. In addition, we conduct theoretical convergence analysis for the proposed iMacSR. Extensive experiments on AD benchmarks (i.e., Cityscapes, CamVid, and SynthiaSF datasets) demonstrate that iMacSR outperforms conventional final-layer single-point supervision method up to 9.19% in mean Intersection over Union (mIoU).
Label Anything: An Interpretable, High-Fidelity and Prompt-Free Annotator
Feb 05, 2025



Learning-based street scene semantic understanding in autonomous driving (AD) has advanced significantly recently, but the performance of the AD model is heavily dependent on the quantity and quality of the annotated training data. However, traditional manual labeling involves high cost to annotate the vast amount of required data for training robust model. To mitigate this cost of manual labeling, we propose a Label Anything Model (denoted as LAM), serving as an interpretable, high-fidelity, and prompt-free data annotator. Specifically, we firstly incorporate a pretrained Vision Transformer (ViT) to extract the latent features. On top of ViT, we propose a semantic class adapter (SCA) and an optimization-oriented unrolling algorithm (OptOU), both with a quite small number of trainable parameters. SCA is proposed to fuse ViT-extracted features to consolidate the basis of the subsequent automatic annotation. OptOU consists of multiple cascading layers and each layer contains an optimization formulation to align its output with the ground truth as closely as possible, though which OptOU acts as being interpretable rather than learning-based blackbox nature. In addition, training SCA and OptOU requires only a single pre-annotated RGB seed image, owing to their small volume of learnable parameters. Extensive experiments clearly demonstrate that the proposed LAM can generate high-fidelity annotations (almost 100% in mIoU) for multiple real-world datasets (i.e., Camvid, Cityscapes, and Apolloscapes) and CARLA simulation dataset.
Enhancing Large Vision Model in Street Scene Semantic Understanding through Leveraging Posterior Optimization Trajectory
Jan 03, 2025To improve the generalization of the autonomous driving (AD) perception model, vehicles need to update the model over time based on the continuously collected data. As time progresses, the amount of data fitted by the AD model expands, which helps to improve the AD model generalization substantially. However, such ever-expanding data is a double-edged sword for the AD model. Specifically, as the fitted data volume grows to exceed the the AD model's fitting capacities, the AD model is prone to under-fitting. To address this issue, we propose to use a pretrained Large Vision Models (LVMs) as backbone coupled with downstream perception head to understand AD semantic information. This design can not only surmount the aforementioned under-fitting problem due to LVMs' powerful fitting capabilities, but also enhance the perception generalization thanks to LVMs' vast and diverse training data. On the other hand, to mitigate vehicles' computational burden of training the perception head while running LVM backbone, we introduce a Posterior Optimization Trajectory (POT)-Guided optimization scheme (POTGui) to accelerate the convergence. Concretely, we propose a POT Generator (POTGen) to generate posterior (future) optimization direction in advance to guide the current optimization iteration, through which the model can generally converge within 10 epochs. Extensive experiments demonstrate that the proposed method improves the performance by over 66.48\% and converges faster over 6 times, compared to the existing state-of-the-art approach.
Fast-Convergent and Communication-Alleviated Heterogeneous Hierarchical Federated Learning in Autonomous Driving
Sep 29, 2024Street Scene Semantic Understanding (denoted as TriSU) is a complex task for autonomous driving (AD). However, inference model trained from data in a particular geographical region faces poor generalization when applied in other regions due to inter-city data domain-shift. Hierarchical Federated Learning (HFL) offers a potential solution for improving TriSU model generalization by collaborative privacy-preserving training over distributed datasets from different cities. Unfortunately, it suffers from slow convergence because data from different cities are with disparate statistical properties. Going beyond existing HFL methods, we propose a Gaussian heterogeneous HFL algorithm (FedGau) to address inter-city data heterogeneity so that convergence can be accelerated. In the proposed FedGau algorithm, both single RGB image and RGB dataset are modelled as Gaussian distributions for aggregation weight design. This approach not only differentiates each RGB image by respective statistical distribution, but also exploits the statistics of dataset from each city in addition to the conventionally considered data volume. With the proposed approach, the convergence is accelerated by 35.5\%-40.6\% compared to existing state-of-the-art (SOTA) HFL methods. On the other hand, to reduce the involved communication resource, we further introduce a novel performance-aware adaptive resource scheduling (AdapRS) policy. Unlike the traditional static resource scheduling policy that exchanges a fixed number of models between two adjacent aggregations, AdapRS adjusts the number of model aggregation at different levels of HFL so that unnecessary communications are minimized. Extensive experiments demonstrate that AdapRS saves 29.65\% communication overhead compared to conventional static resource scheduling policy while maintaining almost the same performance.
Pareto Front Shape-Agnostic Pareto Set Learning in Multi-Objective Optimization
Aug 11, 2024Pareto set learning (PSL) is an emerging approach for acquiring the complete Pareto set of a multi-objective optimization problem. Existing methods primarily rely on the mapping of preference vectors in the objective space to Pareto optimal solutions in the decision space. However, the sampling of preference vectors theoretically requires prior knowledge of the Pareto front shape to ensure high performance of the PSL methods. Designing a sampling strategy of preference vectors is difficult since the Pareto front shape cannot be known in advance. To make Pareto set learning work effectively in any Pareto front shape, we propose a Pareto front shape-agnostic Pareto Set Learning (GPSL) that does not require the prior information about the Pareto front. The fundamental concept behind GPSL is to treat the learning of the Pareto set as a distribution transformation problem. Specifically, GPSL can transform an arbitrary distribution into the Pareto set distribution. We demonstrate that training a neural network by maximizing hypervolume enables the process of distribution transformation. Our proposed method can handle any shape of the Pareto front and learn the Pareto set without requiring prior knowledge. Experimental results show the high performance of our proposed method on diverse test problems compared with recent Pareto set learning algorithms.
* 7 pages
FedRC: A Rapid-Converged Hierarchical Federated Learning Framework in Street Scene Semantic Understanding
Jul 01, 2024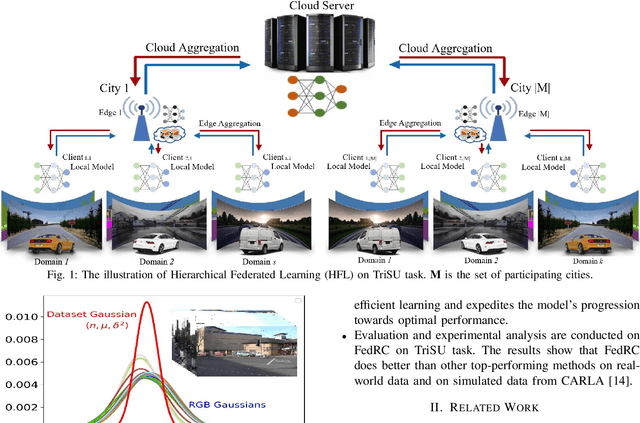
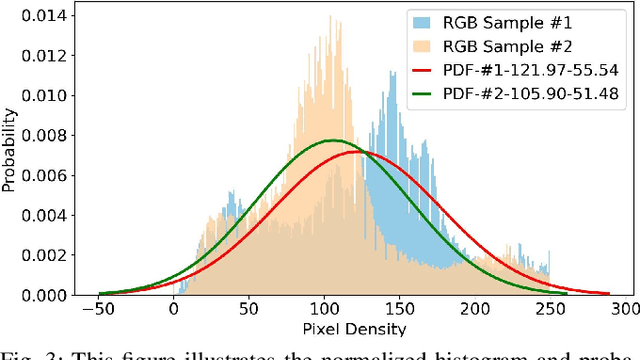
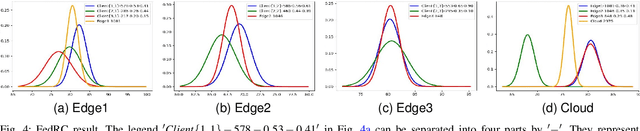

Street Scene Semantic Understanding (denoted as TriSU) is a crucial but complex task for world-wide distributed autonomous driving (AD) vehicles (e.g., Tesla). Its inference model faces poor generalization issue due to inter-city domain-shift. Hierarchical Federated Learning (HFL) offers a potential solution for improving TriSU model generalization, but suffers from slow convergence rate because of vehicles' surrounding heterogeneity across cities. Going beyond existing HFL works that have deficient capabilities in complex tasks, we propose a rapid-converged heterogeneous HFL framework (FedRC) to address the inter-city data heterogeneity and accelerate HFL model convergence rate. In our proposed FedRC framework, both single RGB image and RGB dataset are modelled as Gaussian distributions in HFL aggregation weight design. This approach not only differentiates each RGB sample instead of typically equalizing them, but also considers both data volume and statistical properties rather than simply taking data quantity into consideration. Extensive experiments on the TriSU task using across-city datasets demonstrate that FedRC converges faster than the state-of-the-art benchmark by 38.7%, 37.5%, 35.5%, and 40.6% in terms of mIoU, mPrecision, mRecall, and mF1, respectively. Furthermore, qualitative evaluations in the CARLA simulation environment confirm that the proposed FedRC framework delivers top-tier performance.
pFedLVM: A Large Vision Model -Driven and Latent Feature-Based Personalized Federated Learning Framework in Autonomous Driving
May 07, 2024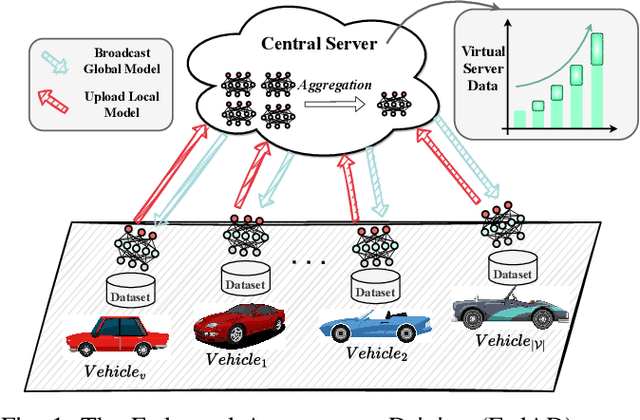
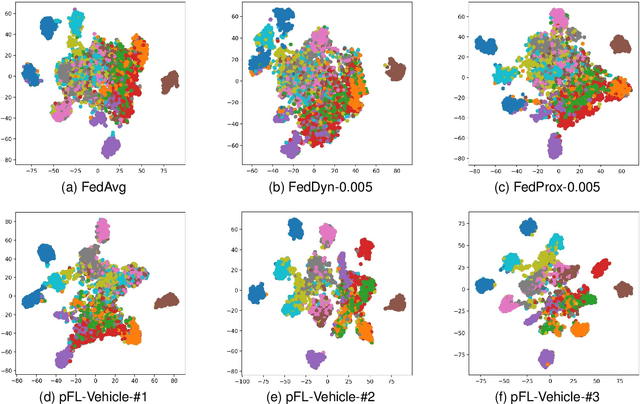
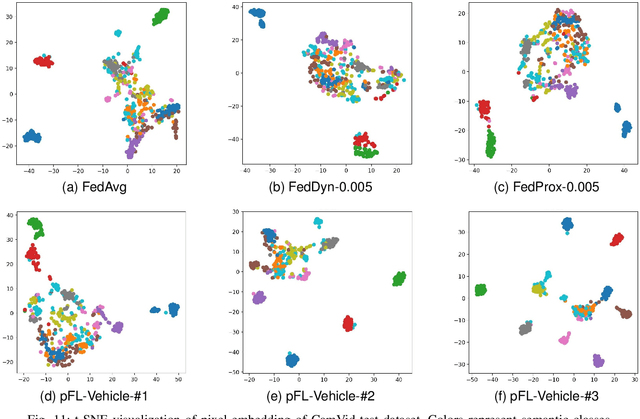
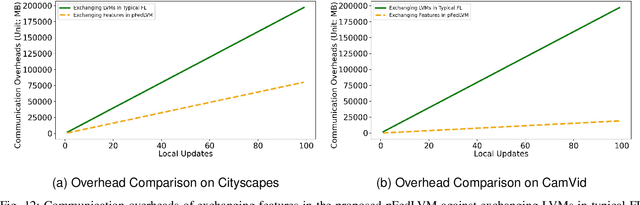
Deep learning-based Autonomous Driving (AD) models often exhibit poor generalization due to data heterogeneity in an ever domain-shifting environment. While Federated Learning (FL) could improve the generalization of an AD model (known as FedAD system), conventional models often struggle with under-fitting as the amount of accumulated training data progressively increases. To address this issue, instead of conventional small models, employing Large Vision Models (LVMs) in FedAD is a viable option for better learning of representations from a vast volume of data. However, implementing LVMs in FedAD introduces three challenges: (I) the extremely high communication overheads associated with transmitting LVMs between participating vehicles and a central server; (II) lack of computing resource to deploy LVMs on each vehicle; (III) the performance drop due to LVM focusing on shared features but overlooking local vehicle characteristics. To overcome these challenges, we propose pFedLVM, a LVM-Driven, Latent Feature-Based Personalized Federated Learning framework. In this approach, the LVM is deployed only on central server, which effectively alleviates the computational burden on individual vehicles. Furthermore, the exchange between central server and vehicles are the learned features rather than the LVM parameters, which significantly reduces communication overhead. In addition, we utilize both shared features from all participating vehicles and individual characteristics from each vehicle to establish a personalized learning mechanism. This enables each vehicle's model to learn features from others while preserving its personalized characteristics, thereby outperforming globally shared models trained in general FL. Extensive experiments demonstrate that pFedLVM outperforms the existing state-of-the-art approaches.
Communication Resources Constrained Hierarchical Federated Learning for End-to-End Autonomous Driving
Jun 28, 2023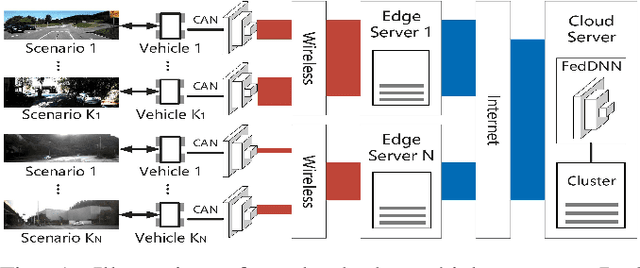
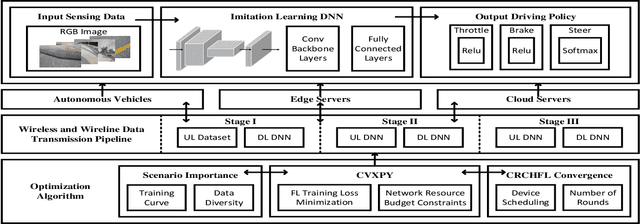
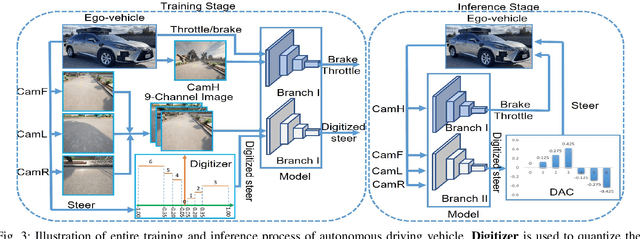

While federated learning (FL) improves the generalization of end-to-end autonomous driving by model aggregation, the conventional single-hop FL (SFL) suffers from slow convergence rate due to long-range communications among vehicles and cloud server. Hierarchical federated learning (HFL) overcomes such drawbacks via introduction of mid-point edge servers. However, the orchestration between constrained communication resources and HFL performance becomes an urgent problem. This paper proposes an optimization-based Communication Resource Constrained Hierarchical Federated Learning (CRCHFL) framework to minimize the generalization error of the autonomous driving model using hybrid data and model aggregation. The effectiveness of the proposed CRCHFL is evaluated in the Car Learning to Act (CARLA) simulation platform. Results show that the proposed CRCHFL both accelerates the convergence rate and enhances the generalization of federated learning autonomous driving model. Moreover, under the same communication resource budget, it outperforms the HFL by 10.33% and the SFL by 12.44%.