 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHPTune: Hierarchical Proactive Tuning for Collision-Free Model Predictive Control
Jan 29, 2026Parameter tuning is a powerful approach to enhance adaptability in model predictive control (MPC) motion planners. However, existing methods typically operate in a myopic fashion that only evaluates executed actions, leading to inefficient parameter updates due to the sparsity of failure events (e.g., obstacle nearness or collision). To cope with this issue, we propose to extend evaluation from executed to non-executed actions, yielding a hierarchical proactive tuning (HPTune) framework that combines both a fast-level tuning and a slow-level tuning. The fast one adopts risk indicators of predictive closing speed and predictive proximity distance, and the slow one leverages an extended evaluation loss for closed-loop backpropagation. Additionally, we integrate HPTune with the Doppler LiDAR that provides obstacle velocities apart from position-only measurements for enhanced motion predictions, thus facilitating the implementation of HPTune. Extensive experiments on high-fidelity simulator demonstrate that HPTune achieves efficient MPC tuning and outperforms various baseline schemes in complex environments. It is found that HPTune enables situation-tailored motion planning by formulating a safe, agile collision avoidance strategy.
VideoThinker: Building Agentic VideoLLMs with LLM-Guided Tool Reasoning
Jan 22, 2026Long-form video understanding remains a fundamental challenge for current Video Large Language Models. Most existing models rely on static reasoning over uniformly sampled frames, which weakens temporal localization and leads to substantial information loss in long videos. Agentic tools such as temporal retrieval, spatial zoom, and temporal zoom offer a natural way to overcome these limitations by enabling adaptive exploration of key moments. However, constructing agentic video understanding data requires models that already possess strong long-form video comprehension, creating a circular dependency. We address this challenge with VideoThinker, an agentic Video Large Language Model trained entirely on synthetic tool interaction trajectories. Our key idea is to convert videos into rich captions and employ a powerful agentic language model to generate multi-step tool use sequences in caption space. These trajectories are subsequently grounded back to video by replacing captions with the corresponding frames, yielding a large-scale interleaved video and tool reasoning dataset without requiring any long-form understanding from the underlying model. Training on this synthetic agentic dataset equips VideoThinker with dynamic reasoning capabilities, adaptive temporal exploration, and multi-step tool use. Remarkably, VideoThinker significantly outperforms both caption-only language model agents and strong video model baselines across long-video benchmarks, demonstrating the effectiveness of tool augmented synthetic data and adaptive retrieval and zoom reasoning for long-form video understanding.
GeoVista: Web-Augmented Agentic Visual Reasoning for Geolocalization
Nov 19, 2025Current research on agentic visual reasoning enables deep multimodal understanding but primarily focuses on image manipulation tools, leaving a gap toward more general-purpose agentic models. In this work, we revisit the geolocalization task, which requires not only nuanced visual grounding but also web search to confirm or refine hypotheses during reasoning. Since existing geolocalization benchmarks fail to meet the need for high-resolution imagery and the localization challenge for deep agentic reasoning, we curate GeoBench, a benchmark that includes photos and panoramas from around the world, along with a subset of satellite images of different cities to rigorously evaluate the geolocalization ability of agentic models. We also propose GeoVista, an agentic model that seamlessly integrates tool invocation within the reasoning loop, including an image-zoom-in tool to magnify regions of interest and a web-search tool to retrieve related web information. We develop a complete training pipeline for it, including a cold-start supervised fine-tuning (SFT) stage to learn reasoning patterns and tool-use priors, followed by a reinforcement learning (RL) stage to further enhance reasoning ability. We adopt a hierarchical reward to leverage multi-level geographical information and improve overall geolocalization performance. Experimental results show that GeoVista surpasses other open-source agentic models on the geolocalization task greatly and achieves performance comparable to closed-source models such as Gemini-2.5-flash and GPT-5 on most metrics.
NTK-Guided Implicit Neural Teaching
Nov 19, 2025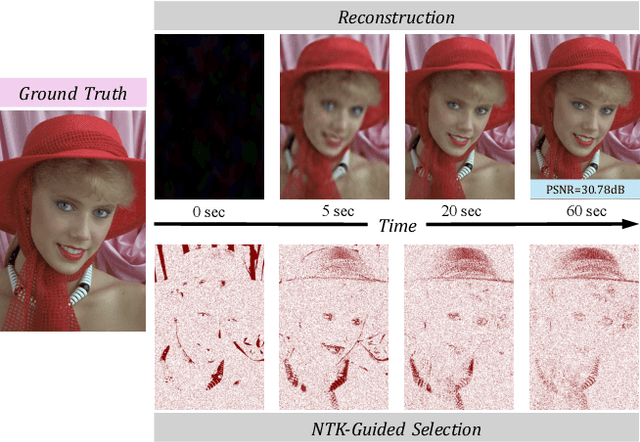
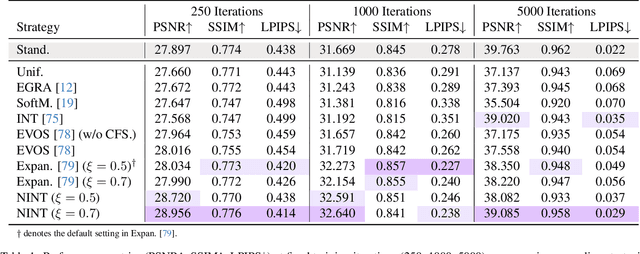
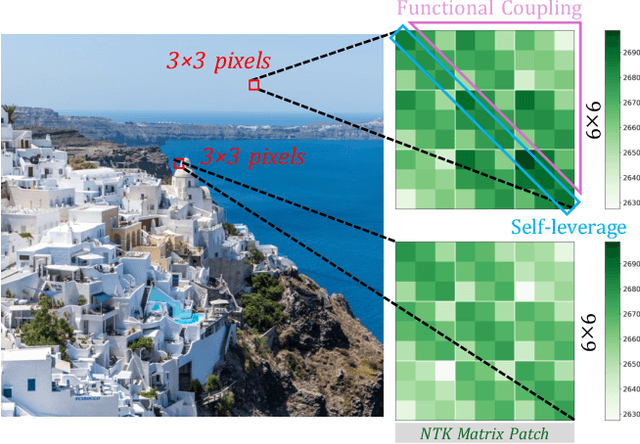
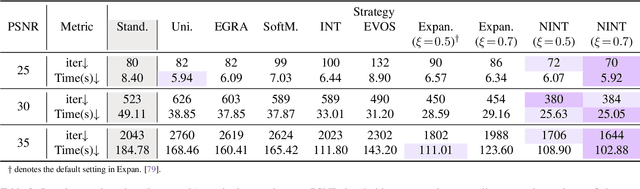
Implicit Neural Representations (INRs) parameterize continuous signals via multilayer perceptrons (MLPs), enabling compact, resolution-independent modeling for tasks like image, audio, and 3D reconstruction. However, fitting high-resolution signals demands optimizing over millions of coordinates, incurring prohibitive computational costs. To address it, we propose NTK-Guided Implicit Neural Teaching (NINT), which accelerates training by dynamically selecting coordinates that maximize global functional updates. Leveraging the Neural Tangent Kernel (NTK), NINT scores examples by the norm of their NTK-augmented loss gradients, capturing both fitting errors and heterogeneous leverage (self-influence and cross-coordinate coupling). This dual consideration enables faster convergence compared to existing methods. Through extensive experiments, we demonstrate that NINT significantly reduces training time by nearly half while maintaining or improving representation quality, establishing state-of-the-art acceleration among recent sampling-based strategies.
EnvX: Agentize Everything with Agentic AI
Sep 09, 2025


The widespread availability of open-source repositories has led to a vast collection of reusable software components, yet their utilization remains manual, error-prone, and disconnected. Developers must navigate documentation, understand APIs, and write integration code, creating significant barriers to efficient software reuse. To address this, we present EnvX, a framework that leverages Agentic AI to agentize GitHub repositories, transforming them into intelligent, autonomous agents capable of natural language interaction and inter-agent collaboration. Unlike existing approaches that treat repositories as static code resources, EnvX reimagines them as active agents through a three-phase process: (1) TODO-guided environment initialization, which sets up the necessary dependencies, data, and validation datasets; (2) human-aligned agentic automation, allowing repository-specific agents to autonomously perform real-world tasks; and (3) Agent-to-Agent (A2A) protocol, enabling multiple agents to collaborate. By combining large language model capabilities with structured tool integration, EnvX automates not just code generation, but the entire process of understanding, initializing, and operationalizing repository functionality. We evaluate EnvX on the GitTaskBench benchmark, using 18 repositories across domains such as image processing, speech recognition, document analysis, and video manipulation. Our results show that EnvX achieves a 74.07% execution completion rate and 51.85% task pass rate, outperforming existing frameworks. Case studies further demonstrate EnvX's ability to enable multi-repository collaboration via the A2A protocol. This work marks a shift from treating repositories as passive code resources to intelligent, interactive agents, fostering greater accessibility and collaboration within the open-source ecosystem.
Autoregressive Semantic Visual Reconstruction Helps VLMs Understand Better
Jun 10, 2025
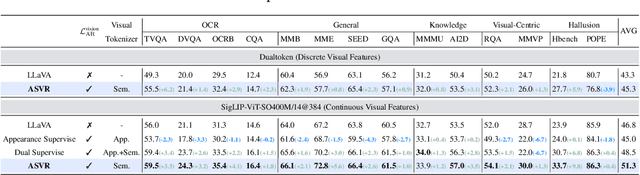
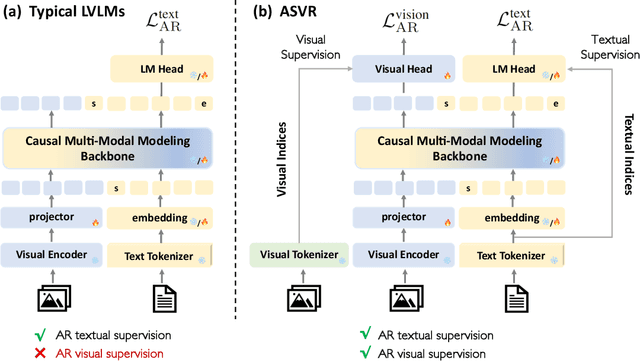
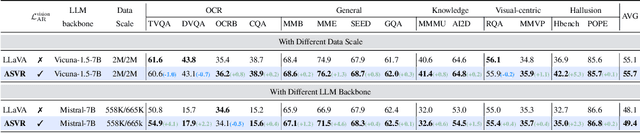
Typical large vision-language models (LVLMs) apply autoregressive supervision solely to textual sequences, without fully incorporating the visual modality into the learning process. This results in three key limitations: (1) an inability to utilize images without accompanying captions, (2) the risk that captions omit critical visual details, and (3) the challenge that certain vision-centric content cannot be adequately conveyed through text. As a result, current LVLMs often prioritize vision-to-language alignment while potentially overlooking fine-grained visual information. While some prior works have explored autoregressive image generation, effectively leveraging autoregressive visual supervision to enhance image understanding remains an open challenge. In this paper, we introduce Autoregressive Semantic Visual Reconstruction (ASVR), which enables joint learning of visual and textual modalities within a unified autoregressive framework. We show that autoregressively reconstructing the raw visual appearance of images does not enhance and may even impair multimodal understanding. In contrast, autoregressively reconstructing the semantic representation of images consistently improves comprehension. Notably, we find that even when models are given continuous image features as input, they can effectively reconstruct discrete semantic tokens, resulting in stable and consistent improvements across a wide range of multimodal understanding benchmarks. Our approach delivers significant performance gains across varying data scales (556k-2M) and types of LLM bacbones. Specifically, ASVR improves LLaVA-1.5 by 5% in average scores across 14 multimodal benchmarks. The code is available at https://github.com/AlenjandroWang/ASVR.
GeometryZero: Improving Geometry Solving for LLM with Group Contrastive Policy Optimization
Jun 08, 2025Recent advances in large language models (LLMs) have demonstrated remarkable capabilities across diverse domains, particularly in mathematical reasoning, amid which geometry problem solving remains a challenging area where auxiliary construction plays a enssential role. Existing approaches either achieve suboptimal performance or rely on massive LLMs (e.g., GPT-4o), incurring massive computational costs. We posit that reinforcement learning with verifiable reward (e.g., GRPO) offers a promising direction for training smaller models that effectively combine auxiliary construction with robust geometric reasoning. However, directly applying GRPO to geometric reasoning presents fundamental limitations due to its dependence on unconditional rewards, which leads to indiscriminate and counterproductive auxiliary constructions. To address these challenges, we propose Group Contrastive Policy Optimization (GCPO), a novel reinforcement learning framework featuring two key innovations: (1) Group Contrastive Masking, which adaptively provides positive or negative reward signals for auxiliary construction based on contextual utility, and a (2) length reward that promotes longer reasoning chains. Building on GCPO, we develop GeometryZero, a family of affordable-size geometric reasoning models that judiciously determine when to employ auxiliary construction. Our extensive empirical evaluation across popular geometric benchmarks (Geometry3K, MathVista) demonstrates that GeometryZero models consistently outperform baselines (e.g. GRPO), achieving an average improvement of 4.29% across all benchmarks.
CIMFlow: An Integrated Framework for Systematic Design and Evaluation of Digital CIM Architectures
May 02, 2025Digital Compute-in-Memory (CIM) architectures have shown great promise in Deep Neural Network (DNN) acceleration by effectively addressing the "memory wall" bottleneck. However, the development and optimization of digital CIM accelerators are hindered by the lack of comprehensive tools that encompass both software and hardware design spaces. Moreover, existing design and evaluation frameworks often lack support for the capacity constraints inherent in digital CIM architectures. In this paper, we present CIMFlow, an integrated framework that provides an out-of-the-box workflow for implementing and evaluating DNN workloads on digital CIM architectures. CIMFlow bridges the compilation and simulation infrastructures with a flexible instruction set architecture (ISA) design, and addresses the constraints of digital CIM through advanced partitioning and parallelism strategies in the compilation flow. Our evaluation demonstrates that CIMFlow enables systematic prototyping and optimization of digital CIM architectures across diverse configurations, providing researchers and designers with an accessible platform for extensive design space exploration.
VisuoThink: Empowering LVLM Reasoning with Multimodal Tree Search
Apr 12, 2025Recent advancements in Large Vision-Language Models have showcased remarkable capabilities. However, they often falter when confronted with complex reasoning tasks that humans typically address through visual aids and deliberate, step-by-step thinking. While existing methods have explored text-based slow thinking or rudimentary visual assistance, they fall short of capturing the intricate, interleaved nature of human visual-verbal reasoning processes. To overcome these limitations and inspired by the mechanisms of slow thinking in human cognition, we introduce VisuoThink, a novel framework that seamlessly integrates visuospatial and linguistic domains. VisuoThink facilitates multimodal slow thinking by enabling progressive visual-textual reasoning and incorporates test-time scaling through look-ahead tree search. Extensive experiments demonstrate that VisuoThink significantly enhances reasoning capabilities via inference-time scaling, even without fine-tuning, achieving state-of-the-art performance in tasks involving geometry and spatial reasoning.
Uncertainty Aware Learning for Language Model Alignment
Jun 07, 2024

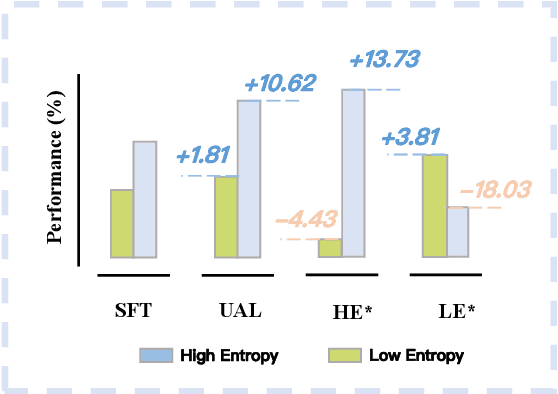

As instruction-tuned large language models (LLMs) evolve, aligning pretrained foundation models presents increasing challenges. Existing alignment strategies, which typically leverage diverse and high-quality data sources, often overlook the intrinsic uncertainty of tasks, learning all data samples equally. This may lead to suboptimal data efficiency and model performance. In response, we propose uncertainty-aware learning (UAL) to improve the model alignment of different task scenarios, by introducing the sample uncertainty (elicited from more capable LLMs). We implement UAL in a simple fashion -- adaptively setting the label smoothing value of training according to the uncertainty of individual samples. Analysis shows that our UAL indeed facilitates better token clustering in the feature space, validating our hypothesis. Extensive experiments on widely used benchmarks demonstrate that our UAL significantly and consistently outperforms standard supervised fine-tuning. Notably, LLMs aligned in a mixed scenario have achieved an average improvement of 10.62\% on high-entropy tasks (i.e., AlpacaEval leaderboard), and 1.81\% on complex low-entropy tasks (i.e., MetaMath and GSM8K).