 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-DA: Data Augmentation via Large Language Models for Few-Shot Named Entity Recognition
Paper and Code
Feb 22, 2024

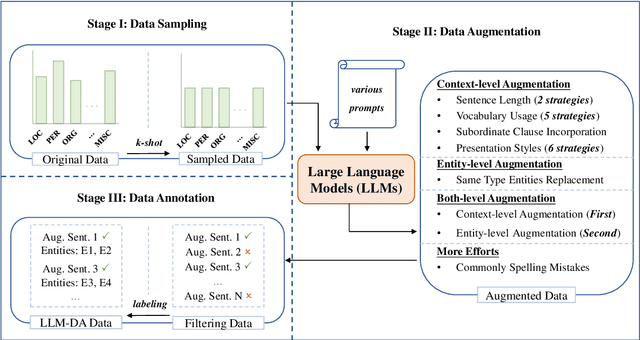

Despite the impressive capabilities of large language models (LLMs), their performance on information extraction tasks is still not entirely satisfactory. However, their remarkable rewriting capabilities and extensive world knowledge offer valuable insights to improve these tasks. In this paper, we propose $LLM-DA$, a novel data augmentation technique based on LLMs for the few-shot NER task. To overcome the limitations of existing data augmentation methods that compromise semantic integrity and address the uncertainty inherent in LLM-generated text, we leverage the distinctive characteristics of the NER task by augmenting the original data at both the contextual and entity levels. Our approach involves employing 14 contextual rewriting strategies, designing entity replacements of the same type, and incorporating noise injection to enhance robustness. Extensive experiments demonstrate the effectiveness of our approach in enhancing NER model performance with limited data. Furthermore, additional analyses provide further evidence supporting the assertion that the quality of the data we generate surpasses that of other existing methods.