 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDC-PIM: Efficient Algorithm/Architecture Co-design for Doubling Data Capacity of SRAM-based Processing-In-Memory
Oct 31, 2023Processing-in-memory (PIM), as a novel computing paradigm, provides significant performance benefits from the aspect of effective data movement reduction. SRAM-based PIM has been demonstrated as one of the most promising candidates due to its endurance and compatibility. However, the integration density of SRAM-based PIM is much lower than other non-volatile memory-based ones, due to its inherent 6T structure for storing a single bit. Within comparable area constraints, SRAM-based PIM exhibits notably lower capacity. Thus, aiming to unleash its capacity potential, we propose DDC-PIM, an efficient algorithm/architecture co-design methodology that effectively doubles the equivalent data capacity. At the algorithmic level, we propose a filter-wise complementary correlation (FCC) algorithm to obtain a bitwise complementary pair. At the architecture level, we exploit the intrinsic cross-coupled structure of 6T SRAM to store the bitwise complementary pair in their complementary states ($Q/\overline{Q}$), thereby maximizing the data capacity of each SRAM cell. The dual-broadcast input structure and reconfigurable unit support both depthwise and pointwise convolution, adhering to the requirements of various neural networks. Evaluation results show that DDC-PIM yields about $2.84\times$ speedup on MobileNetV2 and $2.69\times$ on EfficientNet-B0 with negligible accuracy loss compared with PIM baseline implementation. Compared with state-of-the-art SRAM-based PIM macros, DDC-PIM achieves up to $8.41\times$ and $2.75\times$ improvement in weight density and area efficiency, respectively.
MP-MVS: Multi-Scale Windows PatchMatch and Planar Prior Multi-View Stereo
Sep 23, 2023



Significant strides have been made in enhancing the accuracy of Multi-View Stereo (MVS)-based 3D reconstruction. However, untextured areas with unstable photometric consistency often remain incompletely reconstructed. In this paper, we propose a resilient and effective multi-view stereo approach (MP-MVS). We design a multi-scale windows PatchMatch (mPM) to obtain reliable depth of untextured areas. In contrast with other multi-scale approaches, which is faster and can be easily extended to PatchMatch-based MVS approaches. Subsequently, we improve the existing checkerboard sampling schemes by limiting our sampling to distant regions, which can effectively improve the efficiency of spatial propagation while mitigating outlier generation. Finally, we introduce and improve planar prior assisted PatchMatch of ACMP. Instead of relying on photometric consistency, we utilize geometric consistency information between multi-views to select reliable triangulated vertices. This strategy can obtain a more accurate planar prior model to rectify photometric consistency measurements. Our approach has been tested on the ETH3D High-res multi-view benchmark with several state-of-the-art approaches. The results demonstrate that our approach can reach the state-of-the-art. The associated codes will be accessible at https://github.com/RongxuanTan/MP-MVS.
Efficient Computation Reduction in Bayesian Neural Networks Through Feature Decomposition and Memorization
May 08, 2020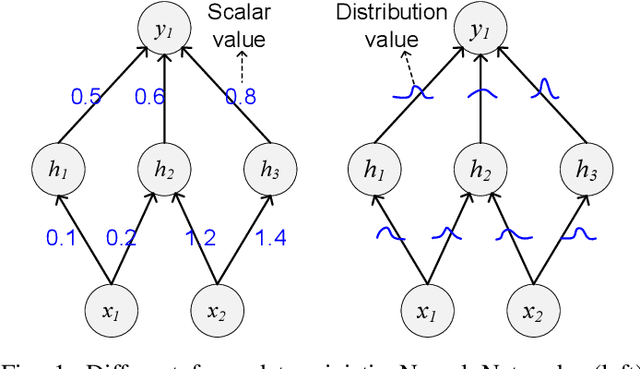
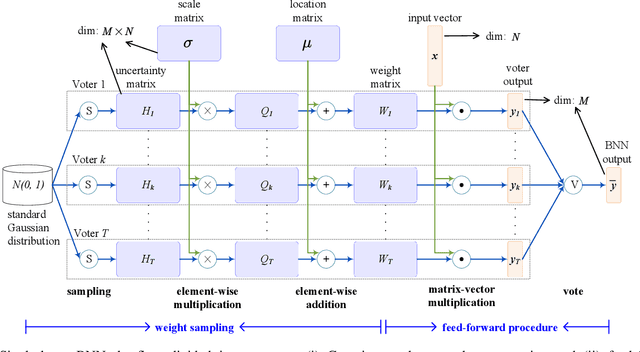
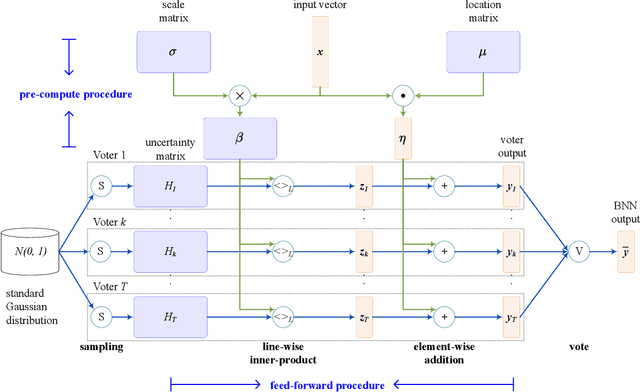
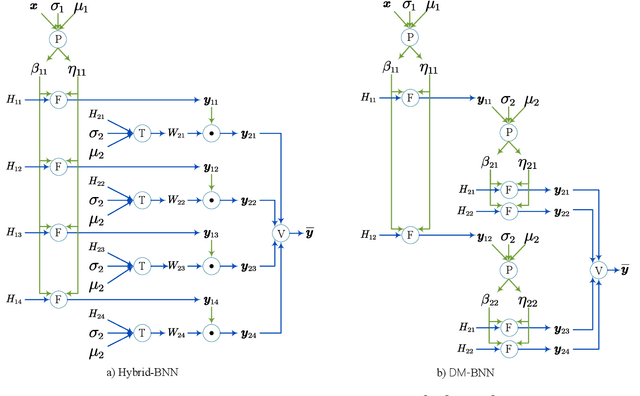
Bayesian method is capable of capturing real world uncertainties/incompleteness and properly addressing the over-fitting issue faced by deep neural networks. In recent years, Bayesian Neural Networks (BNNs) have drawn tremendous attentions of AI researchers and proved to be successful in many applications. However, the required high computation complexity makes BNNs difficult to be deployed in computing systems with limited power budget. In this paper, an efficient BNN inference flow is proposed to reduce the computation cost then is evaluated by means of both software and hardware implementations. A feature decomposition and memorization (\texttt{DM}) strategy is utilized to reform the BNN inference flow in a reduced manner. About half of the computations could be eliminated compared to the traditional approach that has been proved by theoretical analysis and software validations. Subsequently, in order to resolve the hardware resource limitations, a memory-friendly computing framework is further deployed to reduce the memory overhead introduced by \texttt{DM} strategy. Finally, we implement our approach in Verilog and synthesise it with 45 $nm$ FreePDK technology. Hardware simulation results on multi-layer BNNs demonstrate that, when compared with the traditional BNN inference method, it provides an energy consumption reduction of 73\% and a 4$\times$ speedup at the expense of 14\% area overhead.