 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentionLego: An Open-Source Building Block For Spatially-Scalable Large Language Model Accelerator With Processing-In-Memory Technology
Jan 21, 2024Large language models (LLMs) with Transformer architectures have become phenomenal in natural language processing, multimodal generative artificial intelligence, and agent-oriented artificial intelligence. The self-attention module is the most dominating sub-structure inside Transformer-based LLMs. Computation using general-purpose graphics processing units (GPUs) inflicts reckless demand for I/O bandwidth for transferring intermediate calculation results between memories and processing units. To tackle this challenge, this work develops a fully customized vanilla self-attention accelerator, AttentionLego, as the basic building block for constructing spatially expandable LLM processors. AttentionLego provides basic implementation with fully-customized digital logic incorporating Processing-In-Memory (PIM) technology. It is based on PIM-based matrix-vector multiplication and look-up table-based Softmax design. The open-source code is available online: https://bonany.cc/attentionleg.
DDC-PIM: Efficient Algorithm/Architecture Co-design for Doubling Data Capacity of SRAM-based Processing-In-Memory
Oct 31, 2023Processing-in-memory (PIM), as a novel computing paradigm, provides significant performance benefits from the aspect of effective data movement reduction. SRAM-based PIM has been demonstrated as one of the most promising candidates due to its endurance and compatibility. However, the integration density of SRAM-based PIM is much lower than other non-volatile memory-based ones, due to its inherent 6T structure for storing a single bit. Within comparable area constraints, SRAM-based PIM exhibits notably lower capacity. Thus, aiming to unleash its capacity potential, we propose DDC-PIM, an efficient algorithm/architecture co-design methodology that effectively doubles the equivalent data capacity. At the algorithmic level, we propose a filter-wise complementary correlation (FCC) algorithm to obtain a bitwise complementary pair. At the architecture level, we exploit the intrinsic cross-coupled structure of 6T SRAM to store the bitwise complementary pair in their complementary states ($Q/\overline{Q}$), thereby maximizing the data capacity of each SRAM cell. The dual-broadcast input structure and reconfigurable unit support both depthwise and pointwise convolution, adhering to the requirements of various neural networks. Evaluation results show that DDC-PIM yields about $2.84\times$ speedup on MobileNetV2 and $2.69\times$ on EfficientNet-B0 with negligible accuracy loss compared with PIM baseline implementation. Compared with state-of-the-art SRAM-based PIM macros, DDC-PIM achieves up to $8.41\times$ and $2.75\times$ improvement in weight density and area efficiency, respectively.
An Overview of In-memory Processing with Emerging Non-volatile Memory for Data-intensive Applications
Jun 15, 2019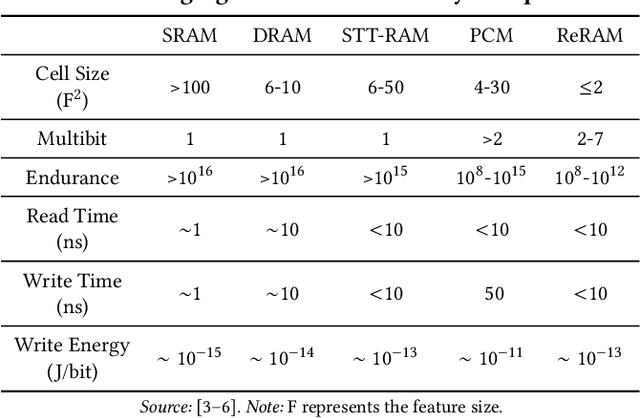
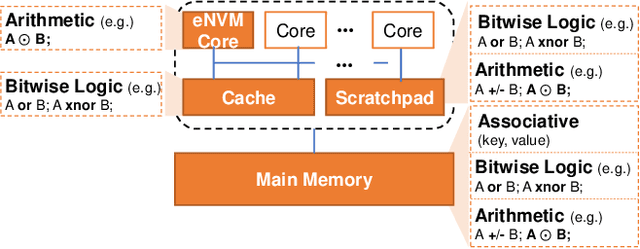
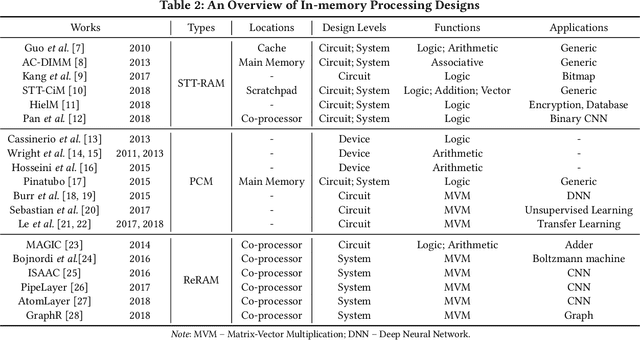
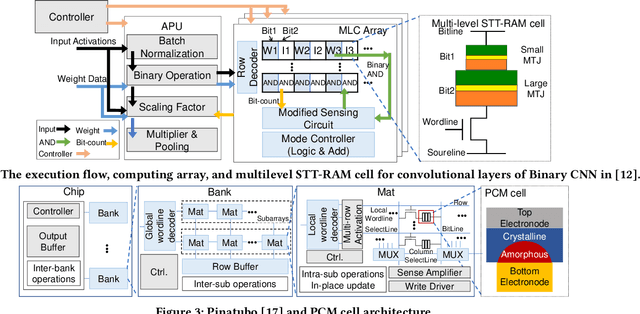
The conventional von Neumann architecture has been revealed as a major performance and energy bottleneck for rising data-intensive applications. %, due to the intensive data movements. The decade-old idea of leveraging in-memory processing to eliminate substantial data movements has returned and led extensive research activities. The effectiveness of in-memory processing heavily relies on memory scalability, which cannot be satisfied by traditional memory technologies. Emerging non-volatile memories (eNVMs) that pose appealing qualities such as excellent scaling and low energy consumption, on the other hand, have been heavily investigated and explored for realizing in-memory processing architecture. In this paper, we summarize the recent research progress in eNVM-based in-memory processing from various aspects, including the adopted memory technologies, locations of the in-memory processing in the system, supported arithmetics, as well as applied applications.