 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMBQ: Modality-Balanced Quantization for Large Vision-Language Models
Dec 27, 2024



Vision-Language Models (VLMs) have enabled a variety of real-world applications. The large parameter size of VLMs brings large memory and computation overhead which poses significant challenges for deployment. Post-Training Quantization (PTQ) is an effective technique to reduce the memory and computation overhead. Existing PTQ methods mainly focus on large language models (LLMs), without considering the differences across other modalities. In this paper, we discover that there is a significant difference in sensitivity between language and vision tokens in large VLMs. Therefore, treating tokens from different modalities equally, as in existing PTQ methods, may over-emphasize the insensitive modalities, leading to significant accuracy loss. To deal with the above issue, we propose a simple yet effective method, Modality-Balanced Quantization (MBQ), for large VLMs. Specifically, MBQ incorporates the different sensitivities across modalities during the calibration process to minimize the reconstruction loss for better quantization parameters. Extensive experiments show that MBQ can significantly improve task accuracy by up to 4.4% and 11.6% under W3 and W4A8 quantization for 7B to 70B VLMs, compared to SOTA baselines. Additionally, we implement a W3 GPU kernel that fuses the dequantization and GEMV operators, achieving a 1.4x speedup on LLaVA-onevision-7B on the RTX 4090. The code is available at https://github.com/thu-nics/MBQ.
DDC-PIM: Efficient Algorithm/Architecture Co-design for Doubling Data Capacity of SRAM-based Processing-In-Memory
Oct 31, 2023Processing-in-memory (PIM), as a novel computing paradigm, provides significant performance benefits from the aspect of effective data movement reduction. SRAM-based PIM has been demonstrated as one of the most promising candidates due to its endurance and compatibility. However, the integration density of SRAM-based PIM is much lower than other non-volatile memory-based ones, due to its inherent 6T structure for storing a single bit. Within comparable area constraints, SRAM-based PIM exhibits notably lower capacity. Thus, aiming to unleash its capacity potential, we propose DDC-PIM, an efficient algorithm/architecture co-design methodology that effectively doubles the equivalent data capacity. At the algorithmic level, we propose a filter-wise complementary correlation (FCC) algorithm to obtain a bitwise complementary pair. At the architecture level, we exploit the intrinsic cross-coupled structure of 6T SRAM to store the bitwise complementary pair in their complementary states ($Q/\overline{Q}$), thereby maximizing the data capacity of each SRAM cell. The dual-broadcast input structure and reconfigurable unit support both depthwise and pointwise convolution, adhering to the requirements of various neural networks. Evaluation results show that DDC-PIM yields about $2.84\times$ speedup on MobileNetV2 and $2.69\times$ on EfficientNet-B0 with negligible accuracy loss compared with PIM baseline implementation. Compared with state-of-the-art SRAM-based PIM macros, DDC-PIM achieves up to $8.41\times$ and $2.75\times$ improvement in weight density and area efficiency, respectively.
Efficient Computation Reduction in Bayesian Neural Networks Through Feature Decomposition and Memorization
May 08, 2020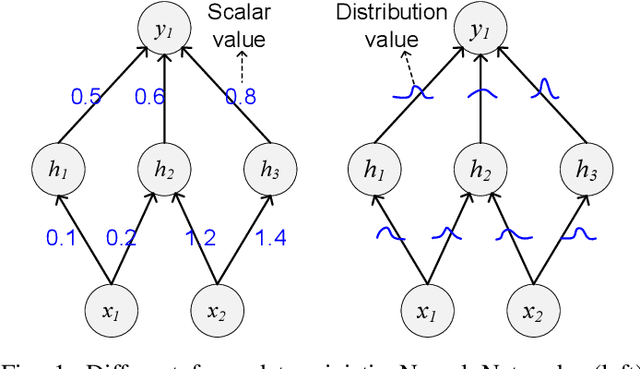
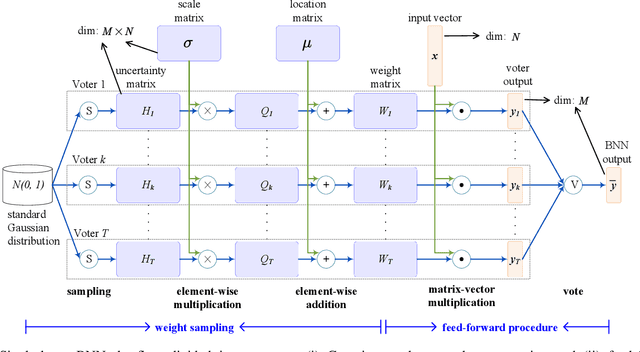
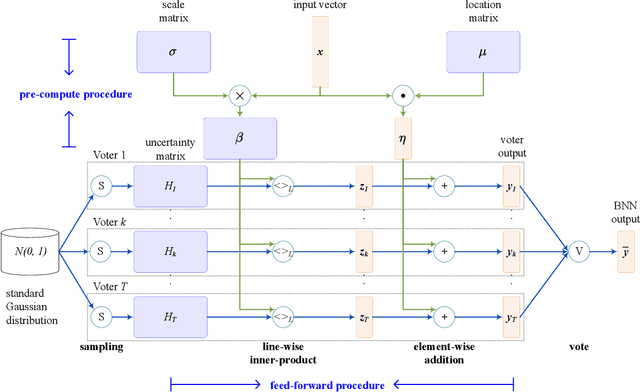
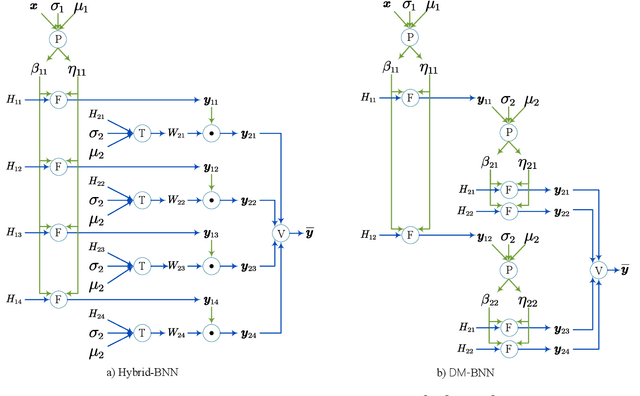
Bayesian method is capable of capturing real world uncertainties/incompleteness and properly addressing the over-fitting issue faced by deep neural networks. In recent years, Bayesian Neural Networks (BNNs) have drawn tremendous attentions of AI researchers and proved to be successful in many applications. However, the required high computation complexity makes BNNs difficult to be deployed in computing systems with limited power budget. In this paper, an efficient BNN inference flow is proposed to reduce the computation cost then is evaluated by means of both software and hardware implementations. A feature decomposition and memorization (\texttt{DM}) strategy is utilized to reform the BNN inference flow in a reduced manner. About half of the computations could be eliminated compared to the traditional approach that has been proved by theoretical analysis and software validations. Subsequently, in order to resolve the hardware resource limitations, a memory-friendly computing framework is further deployed to reduce the memory overhead introduced by \texttt{DM} strategy. Finally, we implement our approach in Verilog and synthesise it with 45 $nm$ FreePDK technology. Hardware simulation results on multi-layer BNNs demonstrate that, when compared with the traditional BNN inference method, it provides an energy consumption reduction of 73\% and a 4$\times$ speedup at the expense of 14\% area overhead.
Spintronics based Stochastic Computing for Efficient Bayesian Inference System
Nov 03, 2017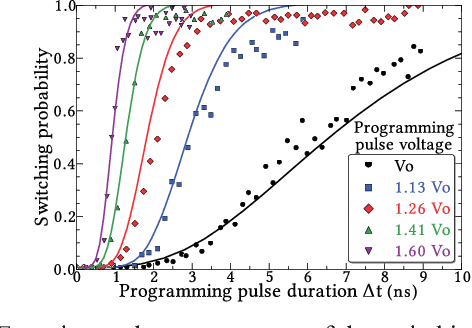
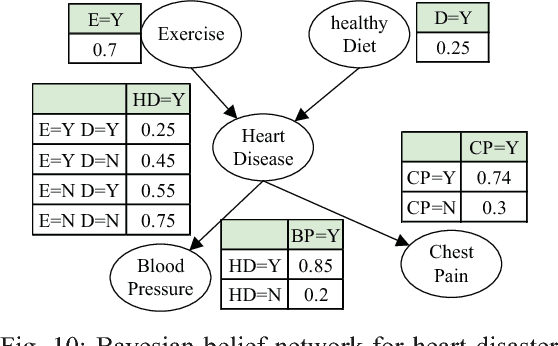
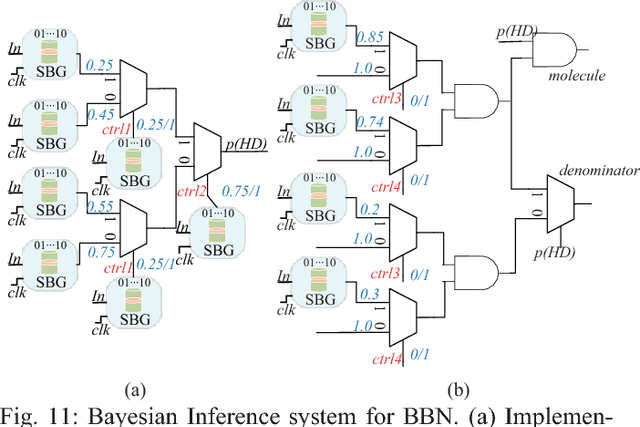
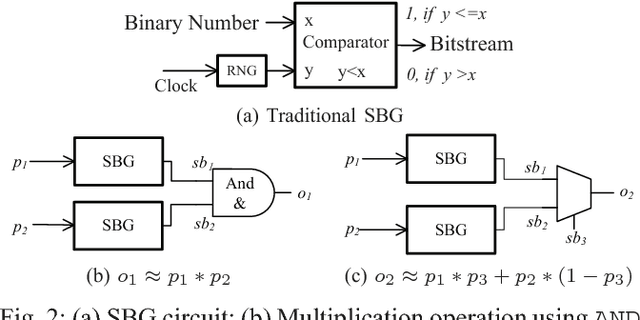
Bayesian inference is an effective approach for solving statistical learning problems especially with uncertainty and incompleteness. However, inference efficiencies are physically limited by the bottlenecks of conventional computing platforms. In this paper, an emerging Bayesian inference system is proposed by exploiting spintronics based stochastic computing. A stochastic bitstream generator is realized as the kernel components by leveraging the inherent randomness of spintronics devices. The proposed system is evaluated by typical applications of data fusion and Bayesian belief networks. Simulation results indicate that the proposed approach could achieve significant improvement on inference efficiencies in terms of power consumption and inference speed.