 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus-dLLM: Accelerating Long-Context Diffusion LLM Inference via Confidence-Guided Context Focusing
Feb 02, 2026Diffusion Large Language Models (dLLMs) deliver strong long-context processing capability in a non-autoregressive decoding paradigm. However, the considerable computational cost of bidirectional full attention limits the inference efficiency. Although sparse attention is promising, existing methods remain ineffective. This stems from the need to estimate attention importance for tokens yet to be decoded, while the unmasked token positions are unknown during diffusion. In this paper, we present Focus-dLLM, a novel training-free attention sparsification framework tailored for accurate and efficient long-context dLLM inference. Based on the finding that token confidence strongly correlates across adjacent steps, we first design a past confidence-guided indicator to predict unmasked regions. Built upon this, we propose a sink-aware pruning strategy to accurately estimate and remove redundant attention computation, while preserving highly influential attention sinks. To further reduce overhead, this strategy reuses identified sink locations across layers, leveraging the observed cross-layer consistency. Experimental results show that our method offers more than $29\times$ lossless speedup under $32K$ context length. The code is publicly available at: https://github.com/Longxmas/Focus-dLLM
RLinf: Flexible and Efficient Large-scale Reinforcement Learning via Macro-to-Micro Flow Transformation
Sep 19, 2025



Reinforcement learning (RL) has demonstrated immense potential in advancing artificial general intelligence, agentic intelligence, and embodied intelligence. However, the inherent heterogeneity and dynamicity of RL workflows often lead to low hardware utilization and slow training on existing systems. In this paper, we present RLinf, a high-performance RL training system based on our key observation that the major roadblock to efficient RL training lies in system flexibility. To maximize flexibility and efficiency, RLinf is built atop a novel RL system design paradigm called macro-to-micro flow transformation (M2Flow), which automatically breaks down high-level, easy-to-compose RL workflows at both the temporal and spatial dimensions, and recomposes them into optimized execution flows. Supported by RLinf worker's adaptive communication capability, we devise context switching and elastic pipelining to realize M2Flow transformation, and a profiling-guided scheduling policy to generate optimal execution plans. Extensive evaluations on both reasoning RL and embodied RL tasks demonstrate that RLinf consistently outperforms state-of-the-art systems, achieving 1.1x-2.13x speedup in end-to-end training throughput.
SlimInfer: Accelerating Long-Context LLM Inference via Dynamic Token Pruning
Aug 08, 2025Long-context inference for Large Language Models (LLMs) is heavily limited by high computational demands. While several existing methods optimize attention computation, they still process the full set of hidden states at each layer, limiting overall efficiency. In this work, we propose SlimInfer, an innovative framework that aims to accelerate inference by directly pruning less critical prompt tokens during the forward pass. Our key insight is an information diffusion phenomenon: As information from critical tokens propagates through layers, it becomes distributed across the entire sequence. This diffusion process suggests that LLMs can maintain their semantic integrity when excessive tokens, even including these critical ones, are pruned in hidden states. Motivated by this, SlimInfer introduces a dynamic fine-grained pruning mechanism that accurately removes redundant tokens of hidden state at intermediate layers. This layer-wise pruning naturally enables an asynchronous KV cache manager that prefetches required token blocks without complex predictors, reducing both memory usage and I/O costs. Extensive experiments show that SlimInfer can achieve up to $\mathbf{2.53\times}$ time-to-first-token (TTFT) speedup and $\mathbf{1.88\times}$ end-to-end latency reduction for LLaMA3.1-8B-Instruct on a single RTX 4090, without sacrificing performance on LongBench. Our code will be released upon acceptance.
CIMFlow: An Integrated Framework for Systematic Design and Evaluation of Digital CIM Architectures
May 02, 2025Digital Compute-in-Memory (CIM) architectures have shown great promise in Deep Neural Network (DNN) acceleration by effectively addressing the "memory wall" bottleneck. However, the development and optimization of digital CIM accelerators are hindered by the lack of comprehensive tools that encompass both software and hardware design spaces. Moreover, existing design and evaluation frameworks often lack support for the capacity constraints inherent in digital CIM architectures. In this paper, we present CIMFlow, an integrated framework that provides an out-of-the-box workflow for implementing and evaluating DNN workloads on digital CIM architectures. CIMFlow bridges the compilation and simulation infrastructures with a flexible instruction set architecture (ISA) design, and addresses the constraints of digital CIM through advanced partitioning and parallelism strategies in the compilation flow. Our evaluation demonstrates that CIMFlow enables systematic prototyping and optimization of digital CIM architectures across diverse configurations, providing researchers and designers with an accessible platform for extensive design space exploration.
HGNAS: Hardware-Aware Graph Neural Architecture Search for Edge Devices
Aug 23, 2024



Graph Neural Networks (GNNs) are becoming increasingly popular for graph-based learning tasks such as point cloud processing due to their state-of-the-art (SOTA) performance. Nevertheless, the research community has primarily focused on improving model expressiveness, lacking consideration of how to design efficient GNN models for edge scenarios with real-time requirements and limited resources. Examining existing GNN models reveals varied execution across platforms and frequent Out-Of-Memory (OOM) problems, highlighting the need for hardware-aware GNN design. To address this challenge, this work proposes a novel hardware-aware graph neural architecture search framework tailored for resource constraint edge devices, namely HGNAS. To achieve hardware awareness, HGNAS integrates an efficient GNN hardware performance predictor that evaluates the latency and peak memory usage of GNNs in milliseconds. Meanwhile, we study GNN memory usage during inference and offer a peak memory estimation method, enhancing the robustness of architecture evaluations when combined with predictor outcomes. Furthermore, HGNAS constructs a fine-grained design space to enable the exploration of extreme performance architectures by decoupling the GNN paradigm. In addition, the multi-stage hierarchical search strategy is leveraged to facilitate the navigation of huge candidates, which can reduce the single search time to a few GPU hours. To the best of our knowledge, HGNAS is the first automated GNN design framework for edge devices, and also the first work to achieve hardware awareness of GNNs across different platforms. Extensive experiments across various applications and edge devices have proven the superiority of HGNAS. It can achieve up to a 10.6x speedup and an 82.5% peak memory reduction with negligible accuracy loss compared to DGCNN on ModelNet40.
GNNavigator: Towards Adaptive Training of Graph Neural Networks via Automatic Guideline Exploration
Apr 15, 2024Graph Neural Networks (GNNs) succeed significantly in many applications recently. However, balancing GNNs training runtime cost, memory consumption, and attainable accuracy for various applications is non-trivial. Previous training methodologies suffer from inferior adaptability and lack a unified training optimization solution. To address the problem, this work proposes GNNavigator, an adaptive GNN training configuration optimization framework. GNNavigator meets diverse GNN application requirements due to our unified software-hardware co-abstraction, proposed GNNs training performance model, and practical design space exploration solution. Experimental results show that GNNavigator can achieve up to 3.1x speedup and 44.9% peak memory reduction with comparable accuracy to state-of-the-art approaches.
Graph Neural Networks Automated Design and Deployment on Device-Edge Co-Inference Systems
Apr 08, 2024



The key to device-edge co-inference paradigm is to partition models into computation-friendly and computation-intensive parts across the device and the edge, respectively. However, for Graph Neural Networks (GNNs), we find that simply partitioning without altering their structures can hardly achieve the full potential of the co-inference paradigm due to various computational-communication overheads of GNN operations over heterogeneous devices. We present GCoDE, the first automatic framework for GNN that innovatively Co-designs the architecture search and the mapping of each operation on Device-Edge hierarchies. GCoDE abstracts the device communication process into an explicit operation and fuses the search of architecture and the operations mapping in a unified space for joint-optimization. Also, the performance-awareness approach, utilized in the constraint-based search process of GCoDE, enables effective evaluation of architecture efficiency in diverse heterogeneous systems. We implement the co-inference engine and runtime dispatcher in GCoDE to enhance the deployment efficiency. Experimental results show that GCoDE can achieve up to $44.9\times$ speedup and $98.2\%$ energy reduction compared to existing approaches across various applications and system configurations.
TinyFormer: Efficient Transformer Design and Deployment on Tiny Devices
Nov 03, 2023



Developing deep learning models on tiny devices (e.g. Microcontroller units, MCUs) has attracted much attention in various embedded IoT applications. However, it is challenging to efficiently design and deploy recent advanced models (e.g. transformers) on tiny devices due to their severe hardware resource constraints. In this work, we propose TinyFormer, a framework specifically designed to develop and deploy resource-efficient transformers on MCUs. TinyFormer mainly consists of SuperNAS, SparseNAS and SparseEngine. Separately, SuperNAS aims to search for an appropriate supernet from a vast search space. SparseNAS evaluates the best sparse single-path model including transformer architecture from the identified supernet. Finally, SparseEngine efficiently deploys the searched sparse models onto MCUs. To the best of our knowledge, SparseEngine is the first deployment framework capable of performing inference of sparse models with transformer on MCUs. Evaluation results on the CIFAR-10 dataset demonstrate that TinyFormer can develop efficient transformers with an accuracy of $96.1\%$ while adhering to hardware constraints of $1$MB storage and $320$KB memory. Additionally, TinyFormer achieves significant speedups in sparse inference, up to $12.2\times$, when compared to the CMSIS-NN library. TinyFormer is believed to bring powerful transformers into TinyML scenarios and greatly expand the scope of deep learning applications.
DDC-PIM: Efficient Algorithm/Architecture Co-design for Doubling Data Capacity of SRAM-based Processing-In-Memory
Oct 31, 2023Processing-in-memory (PIM), as a novel computing paradigm, provides significant performance benefits from the aspect of effective data movement reduction. SRAM-based PIM has been demonstrated as one of the most promising candidates due to its endurance and compatibility. However, the integration density of SRAM-based PIM is much lower than other non-volatile memory-based ones, due to its inherent 6T structure for storing a single bit. Within comparable area constraints, SRAM-based PIM exhibits notably lower capacity. Thus, aiming to unleash its capacity potential, we propose DDC-PIM, an efficient algorithm/architecture co-design methodology that effectively doubles the equivalent data capacity. At the algorithmic level, we propose a filter-wise complementary correlation (FCC) algorithm to obtain a bitwise complementary pair. At the architecture level, we exploit the intrinsic cross-coupled structure of 6T SRAM to store the bitwise complementary pair in their complementary states ($Q/\overline{Q}$), thereby maximizing the data capacity of each SRAM cell. The dual-broadcast input structure and reconfigurable unit support both depthwise and pointwise convolution, adhering to the requirements of various neural networks. Evaluation results show that DDC-PIM yields about $2.84\times$ speedup on MobileNetV2 and $2.69\times$ on EfficientNet-B0 with negligible accuracy loss compared with PIM baseline implementation. Compared with state-of-the-art SRAM-based PIM macros, DDC-PIM achieves up to $8.41\times$ and $2.75\times$ improvement in weight density and area efficiency, respectively.
Architectural Implications of GNN Aggregation Programming Abstractions
Oct 21, 2023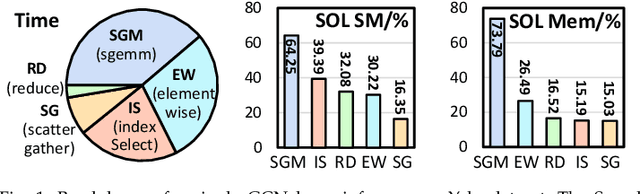

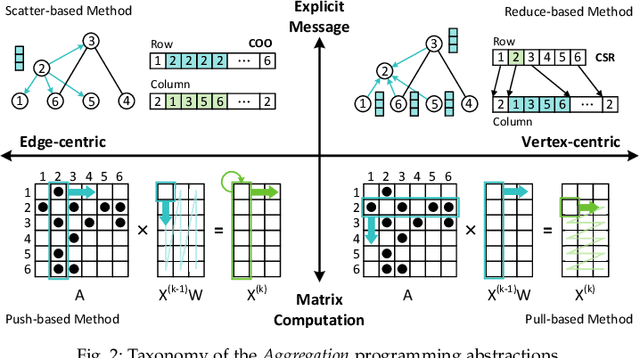
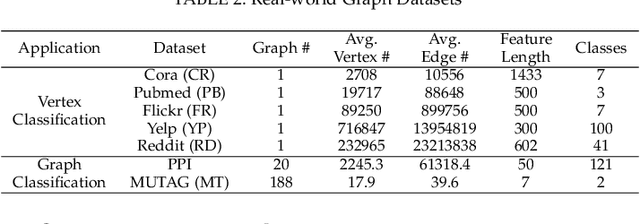
Graph neural networks (GNNs) have gained significant popularity due to the powerful capability to extract useful representations from graph data. As the need for efficient GNN computation intensifies, a variety of programming abstractions designed for optimizing GNN Aggregation have emerged to facilitate acceleration. However, there is no comprehensive evaluation and analysis upon existing abstractions, thus no clear consensus on which approach is better. In this letter, we classify existing programming abstractions for GNN Aggregation by the dimension of data organization and propagation method. By constructing these abstractions on a state-of-the-art GNN library, we perform a thorough and detailed characterization study to compare their performance and efficiency, and provide several insights on future GNN acceleration based on our analysis.