 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Markov Multi-Round Conversational Image Generation with History-Conditioned MLLMs
Jan 28, 2026Conversational image generation requires a model to follow user instructions across multiple rounds of interaction, grounded in interleaved text and images that accumulate as chat history. While recent multimodal large language models (MLLMs) can generate and edit images, most existing multi-turn benchmarks and training recipes are effectively Markov: the next output depends primarily on the most recent image, enabling shortcut solutions that ignore long-range history. In this work we formalize and target the more challenging non-Markov setting, where a user may refer back to earlier states, undo changes, or reference entities introduced several rounds ago. We present (i) non-Markov multi-round data construction strategies, including rollback-style editing that forces retrieval of earlier visual states and name-based multi-round personalization that binds names to appearances across rounds; (ii) a history-conditioned training and inference framework with token-level caching to prevent multi-round identity drift; and (iii) enabling improvements for high-fidelity image reconstruction and editable personalization, including a reconstruction-based DiT detokenizer and a multi-stage fine-tuning curriculum. We demonstrate that explicitly training for non-Markov interactions yields substantial improvements in multi-round consistency and instruction compliance, while maintaining strong single-round editing and personalization.
S2DiT: Sandwich Diffusion Transformer for Mobile Streaming Video Generation
Jan 19, 2026Diffusion Transformers (DiTs) have recently improved video generation quality. However, their heavy computational cost makes real-time or on-device generation infeasible. In this work, we introduce S2DiT, a Streaming Sandwich Diffusion Transformer designed for efficient, high-fidelity, and streaming video generation on mobile hardware. S2DiT generates more tokens but maintains efficiency with novel efficient attentions: a mixture of LinConv Hybrid Attention (LCHA) and Stride Self-Attention (SSA). Based on this, we uncover the sandwich design via a budget-aware dynamic programming search, achieving superior quality and efficiency. We further propose a 2-in-1 distillation framework that transfers the capacity of large teacher models (e.g., Wan 2.2-14B) to the compact few-step sandwich model. Together, S2DiT achieves quality on par with state-of-the-art server video models, while streaming at over 10 FPS on an iPhone.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
LayerComposer: Interactive Personalized T2I via Spatially-Aware Layered Canvas
Oct 23, 2025Despite their impressive visual fidelity, existing personalized generative models lack interactive control over spatial composition and scale poorly to multiple subjects. To address these limitations, we present LayerComposer, an interactive framework for personalized, multi-subject text-to-image generation. Our approach introduces two main contributions: (1) a layered canvas, a novel representation in which each subject is placed on a distinct layer, enabling occlusion-free composition; and (2) a locking mechanism that preserves selected layers with high fidelity while allowing the remaining layers to adapt flexibly to the surrounding context. Similar to professional image-editing software, the proposed layered canvas allows users to place, resize, or lock input subjects through intuitive layer manipulation. Our versatile locking mechanism requires no architectural changes, relying instead on inherent positional embeddings combined with a new complementary data sampling strategy. Extensive experiments demonstrate that LayerComposer achieves superior spatial control and identity preservation compared to the state-of-the-art methods in multi-subject personalized image generation.
Eventor: An Efficient Event-Based Monocular Multi-View Stereo Accelerator on FPGA Platform
Mar 29, 2022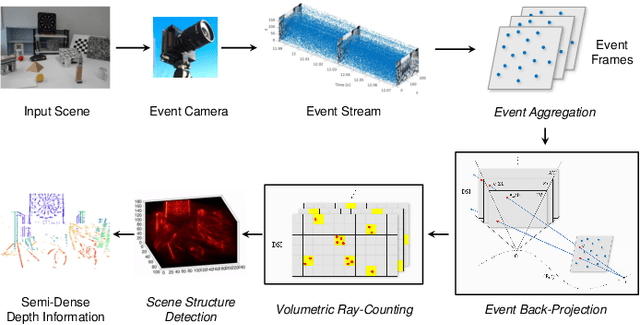
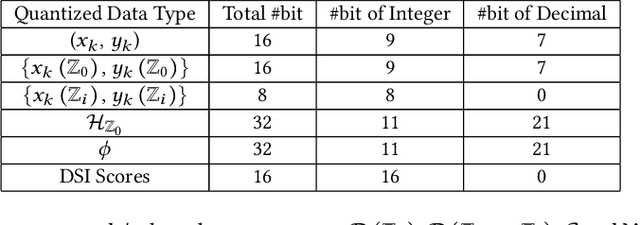
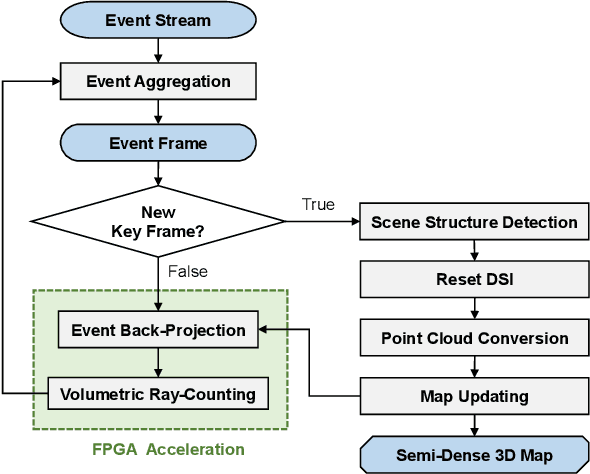
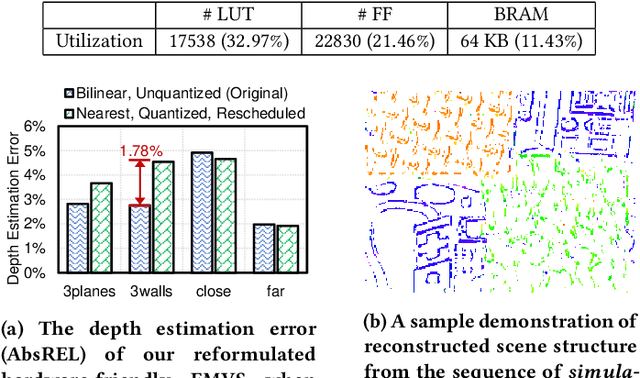
Event cameras are bio-inspired vision sensors that asynchronously represent pixel-level brightness changes as event streams. Event-based monocular multi-view stereo (EMVS) is a technique that exploits the event streams to estimate semi-dense 3D structure with known trajectory. It is a critical task for event-based monocular SLAM. However, the required intensive computation workloads make it challenging for real-time deployment on embedded platforms. In this paper, Eventor is proposed as a fast and efficient EMVS accelerator by realizing the most critical and time-consuming stages including event back-projection and volumetric ray-counting on FPGA. Highly paralleled and fully pipelined processing elements are specially designed via FPGA and integrated with the embedded ARM as a heterogeneous system to improve the throughput and reduce the memory footprint. Meanwhile, the EMVS algorithm is reformulated to a more hardware-friendly manner by rescheduling, approximate computing and hybrid data quantization. Evaluation results on DAVIS dataset show that Eventor achieves up to $24\times$ improvement in energy efficiency compared with Intel i5 CPU platform.
A Hierarchy of Graph Neural Networks Based on Learnable Local Features
Nov 13, 2019
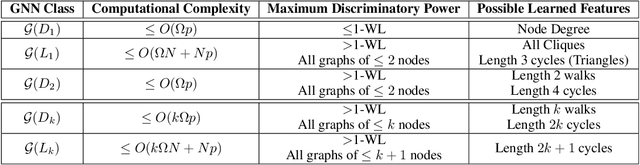

Graph neural networks (GNNs) are a powerful tool to learn representations on graphs by iteratively aggregating features from node neighbourhoods. Many variant models have been proposed, but there is limited understanding on both how to compare different architectures and how to construct GNNs systematically. Here, we propose a hierarchy of GNNs based on their aggregation regions. We derive theoretical results about the discriminative power and feature representation capabilities of each class. Then, we show how this framework can be utilized to systematically construct arbitrarily powerful GNNs. As an example, we construct a simple architecture that exceeds the expressiveness of the Weisfeiler-Lehman graph isomorphism test. We empirically validate our theory on both synthetic and real-world benchmarks, and demonstrate our example's theoretical power translates to strong results on node classification, graph classification, and graph regression tasks.
A Biologically Plausible Supervised Learning Method for Spiking Neural Networks Using the Symmetric STDP Rule
Dec 17, 2018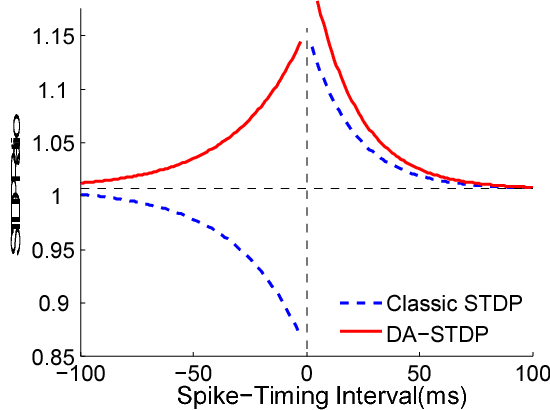

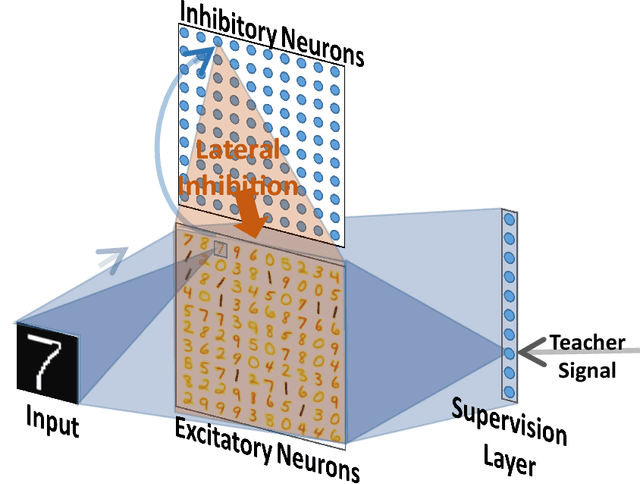
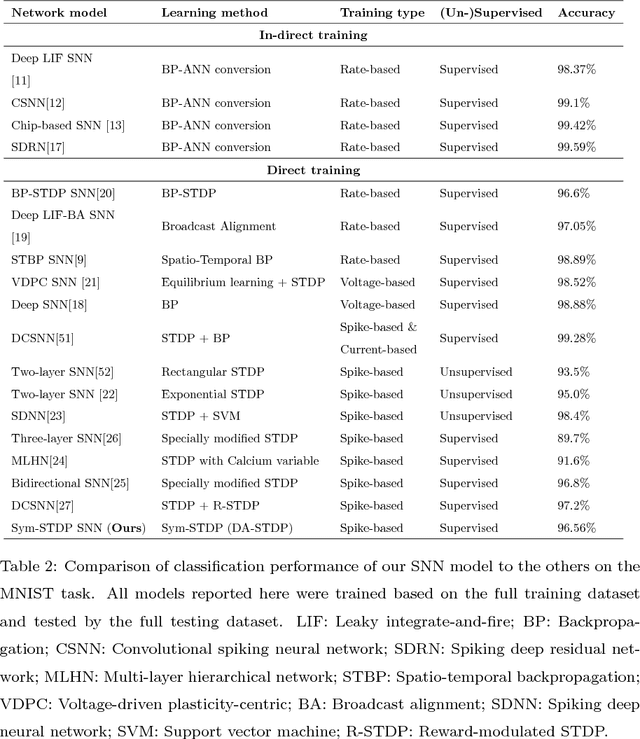
Spiking neural networks (SNNs) possess energy-efficient potential due to event-based computation. However, supervised training of SNNs remains a challenge as spike activities are non-differentiable. Previous SNNs training methods can basically be categorized into two classes, backpropagation-like training methods and plasticity-based learning methods. The former methods are dependent on energy-inefficient real-valued computation and non-local transmission, as also required in artificial neural networks (ANNs), while the latter either be considered biologically implausible or exhibit poor performance. Hence, biologically plausible (bio-plausible) high-performance supervised learning (SL) methods for SNNs remain deficient. In this paper, we proposed a novel bio-plausible SNN model for SL based on the symmetric spike-timing dependent plasticity (sym-STDP) rule found in neuroscience. By combining the sym-STDP rule with bio-plausible synaptic scaling and intrinsic plasticity of the dynamic threshold, our SNN model implemented SL well and achieved good performance in the benchmark recognition task (MNIST). To reveal the underlying mechanism of our SL model, we visualized both layer-based activities and synaptic weights using the t-distributed stochastic neighbor embedding (t-SNE) method after training and found that they were well clustered, thereby demonstrating excellent classification ability. As the learning rules were bio-plausible and based purely on local spike events, our model could be easily applied to neuromorphic hardware for online training and may be helpful for understanding SL information processing at the synaptic level in biological neural systems.