 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiMuSE: Lightweight Multi-modal Speaker Extraction
Nov 07, 2021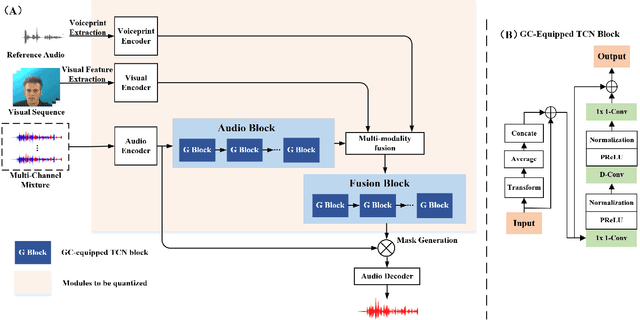


The past several years have witnessed significant progress in modeling the Cocktail Party Problem in terms of speech separation and speaker extraction. In recent years, multi-modal cues, including spatial information, facial expression and voiceprint, are introduced to speaker extraction task to serve as complementary information to each other to achieve better performance. However, the front-end model, for speaker extraction, become large and hard to deploy on a resource-constrained device. In this paper, we address the aforementioned problem with novel model architectures and model compression techniques, and propose a lightweight multi-modal framework for speaker extraction (dubbed LiMuSE), which adopts group communication (GC) to split multi-modal high-dimension features into groups of low-dimension features with smaller width which could be run in parallel, and further uses an ultra-low bit quantization strategy to achieve lower model size. The experiments on the GRID dataset show that incorporating GC into the multi-modal framework achieves on par or better performance with 24.86 times fewer parameters, and applying the quantization strategy to the GC-equipped model further obtains about 9 times compression ratio while maintaining a comparable performance compared with baselines. Our code will be available at https://github.com/aispeech-lab/LiMuSE.
WASE: Learning When to Attend for Speaker Extraction in Cocktail Party Environments
Jun 13, 2021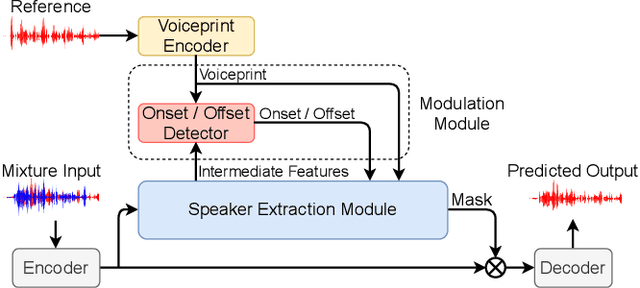
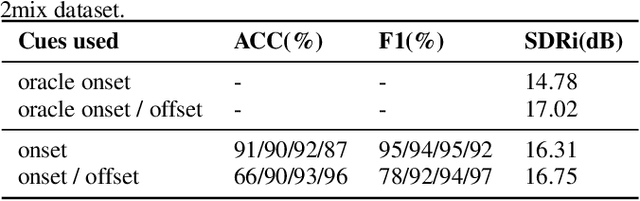
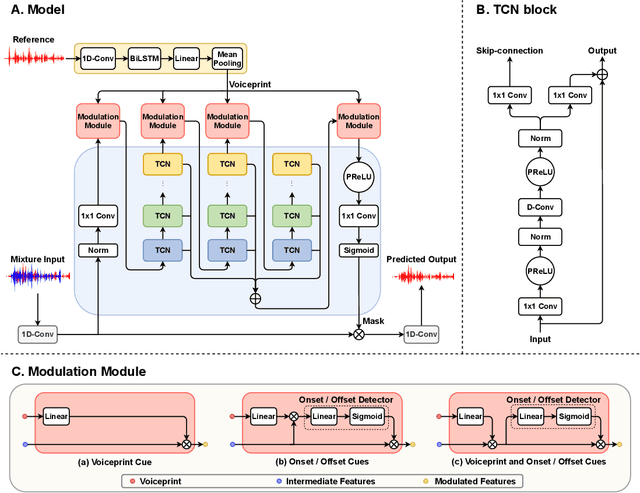
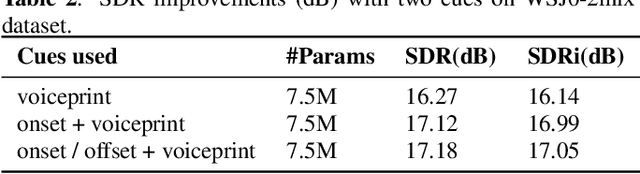
In the speaker extraction problem, it is found that additional information from the target speaker contributes to the tracking and extraction of the target speaker, which includes voiceprint, lip movement, facial expression, and spatial information. However, no one cares for the cue of sound onset, which has been emphasized in the auditory scene analysis and psychology. Inspired by it, we explicitly modeled the onset cue and verified the effectiveness in the speaker extraction task. We further extended to the onset/offset cues and got performance improvement. From the perspective of tasks, our onset/offset-based model completes the composite task, a complementary combination of speaker extraction and speaker-dependent voice activity detection. We also combined voiceprint with onset/offset cues. Voiceprint models voice characteristics of the target while onset/offset models the start/end information of the speech. From the perspective of auditory scene analysis, the combination of two perception cues can promote the integrity of the auditory object. The experiment results are also close to state-of-the-art performance, using nearly half of the parameters. We hope that this work will inspire communities of speech processing and psychology, and contribute to communication between them. Our code will be available in https://github.com/aispeech-lab/wase/.
Audio-visual Speech Separation with Adversarially Disentangled Visual Representation
Nov 29, 2020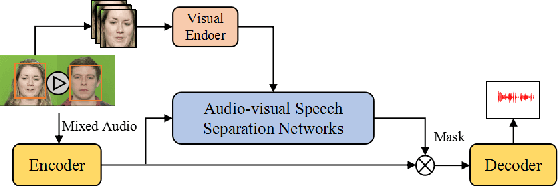
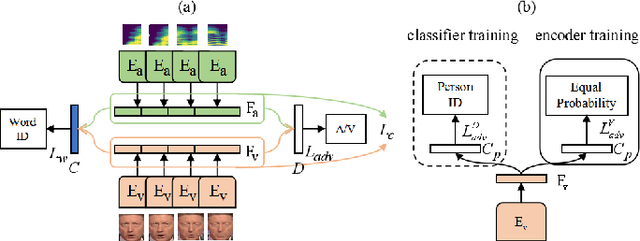
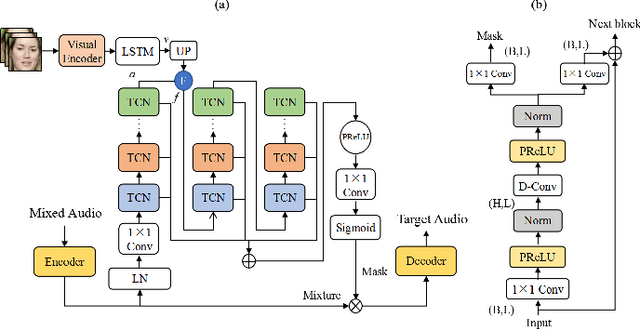
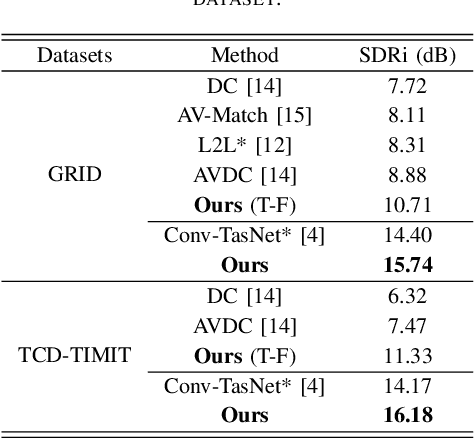
Speech separation aims to separate individual voice from an audio mixture of multiple simultaneous talkers. Although audio-only approaches achieve satisfactory performance, they build on a strategy to handle the predefined conditions, limiting their application in the complex auditory scene. Towards the cocktail party problem, we propose a novel audio-visual speech separation model. In our model, we use the face detector to detect the number of speakers in the scene and use visual information to avoid the permutation problem. To improve our model's generalization ability to unknown speakers, we extract speech-related visual features from visual inputs explicitly by the adversarially disentangled method, and use this feature to assist speech separation. Besides, the time-domain approach is adopted, which could avoid the phase reconstruction problem existing in the time-frequency domain models. To compare our model's performance with other models, we create two benchmark datasets of 2-speaker mixture from GRID and TCDTIMIT audio-visual datasets. Through a series of experiments, our proposed model is shown to outperform the state-of-the-art audio-only model and three audio-visual models.
A Biologically Plausible Supervised Learning Method for Spiking Neural Networks Using the Symmetric STDP Rule
Dec 17, 2018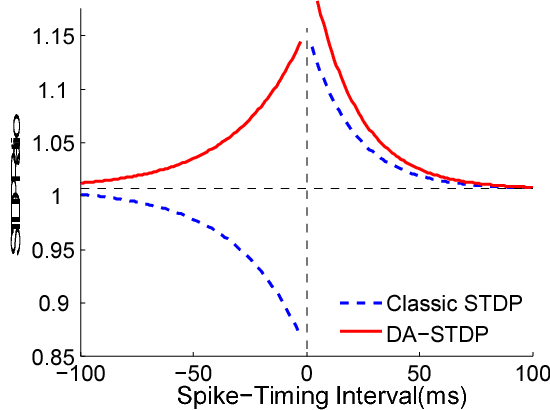

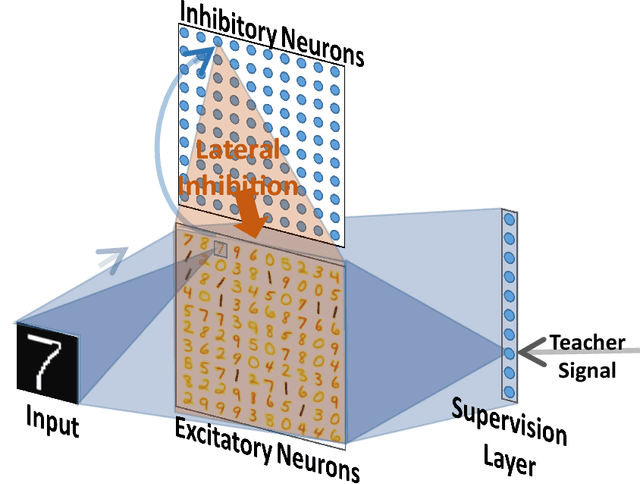
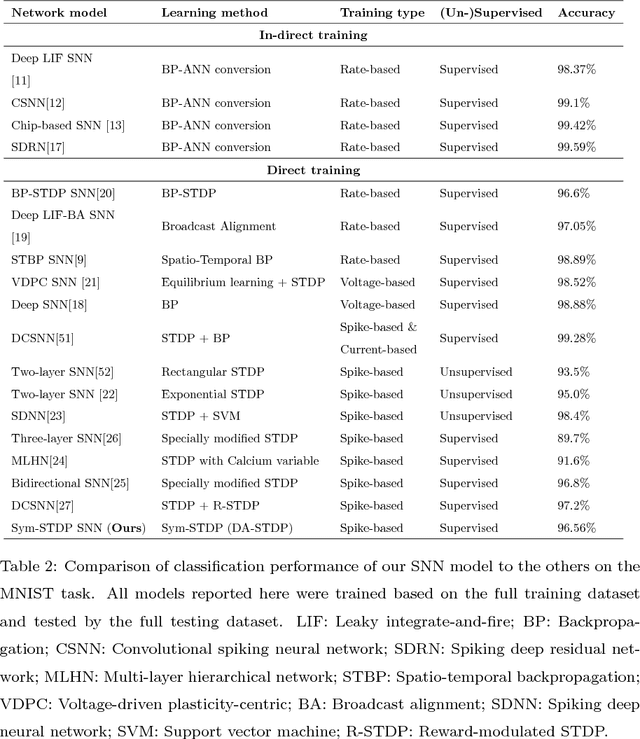
Spiking neural networks (SNNs) possess energy-efficient potential due to event-based computation. However, supervised training of SNNs remains a challenge as spike activities are non-differentiable. Previous SNNs training methods can basically be categorized into two classes, backpropagation-like training methods and plasticity-based learning methods. The former methods are dependent on energy-inefficient real-valued computation and non-local transmission, as also required in artificial neural networks (ANNs), while the latter either be considered biologically implausible or exhibit poor performance. Hence, biologically plausible (bio-plausible) high-performance supervised learning (SL) methods for SNNs remain deficient. In this paper, we proposed a novel bio-plausible SNN model for SL based on the symmetric spike-timing dependent plasticity (sym-STDP) rule found in neuroscience. By combining the sym-STDP rule with bio-plausible synaptic scaling and intrinsic plasticity of the dynamic threshold, our SNN model implemented SL well and achieved good performance in the benchmark recognition task (MNIST). To reveal the underlying mechanism of our SL model, we visualized both layer-based activities and synaptic weights using the t-distributed stochastic neighbor embedding (t-SNE) method after training and found that they were well clustered, thereby demonstrating excellent classification ability. As the learning rules were bio-plausible and based purely on local spike events, our model could be easily applied to neuromorphic hardware for online training and may be helpful for understanding SL information processing at the synaptic level in biological neural systems.