 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
A Systematic Study of Model Extraction Attacks on Graph Foundation Models
Nov 14, 2025Graph machine learning has advanced rapidly in tasks such as link prediction, anomaly detection, and node classification. As models scale up, pretrained graph models have become valuable intellectual assets because they encode extensive computation and domain expertise. Building on these advances, Graph Foundation Models (GFMs) mark a major step forward by jointly pretraining graph and text encoders on massive and diverse data. This unifies structural and semantic understanding, enables zero-shot inference, and supports applications such as fraud detection and biomedical analysis. However, the high pretraining cost and broad cross-domain knowledge in GFMs also make them attractive targets for model extraction attacks (MEAs). Prior work has focused only on small graph neural networks trained on a single graph, leaving the security implications for large-scale and multimodal GFMs largely unexplored. This paper presents the first systematic study of MEAs against GFMs. We formalize a black-box threat model and define six practical attack scenarios covering domain-level and graph-specific extraction goals, architectural mismatch, limited query budgets, partial node access, and training data discrepancies. To instantiate these attacks, we introduce a lightweight extraction method that trains an attacker encoder using supervised regression of graph embeddings. Even without contrastive pretraining data, this method learns an encoder that stays aligned with the victim text encoder and preserves its zero-shot inference ability on unseen graphs. Experiments on seven datasets show that the attacker can approximate the victim model using only a tiny fraction of its original training cost, with almost no loss in accuracy. These findings reveal that GFMs greatly expand the MEA surface and highlight the need for deployment-aware security defenses in large-scale graph learning systems.
Triple-S: A Collaborative Multi-LLM Framework for Solving Long-Horizon Implicative Tasks in Robotics
Aug 10, 2025Leveraging Large Language Models (LLMs) to write policy code for controlling robots has gained significant attention. However, in long-horizon implicative tasks, this approach often results in API parameter, comments and sequencing errors, leading to task failure. To address this problem, we propose a collaborative Triple-S framework that involves multiple LLMs. Through In-Context Learning, different LLMs assume specific roles in a closed-loop Simplification-Solution-Summary process, effectively improving success rates and robustness in long-horizon implicative tasks. Additionally, a novel demonstration library update mechanism which learned from success allows it to generalize to previously failed tasks. We validate the framework in the Long-horizon Desktop Implicative Placement (LDIP) dataset across various baseline models, where Triple-S successfully executes 89% of tasks in both observable and partially observable scenarios. Experiments in both simulation and real-world robot settings further validated the effectiveness of Triple-S. Our code and dataset is available at: https://github.com/Ghbbbbb/Triple-S.
Is Best-of-N the Best of Them? Coverage, Scaling, and Optimality in Inference-Time Alignment
Mar 27, 2025
Inference-time computation provides an important axis for scaling language model performance, but naively scaling compute through techniques like Best-of-$N$ sampling can cause performance to degrade due to reward hacking. Toward a theoretical understanding of how to best leverage additional computation, we focus on inference-time alignment which we formalize as the problem of improving a pre-trained policy's responses for a prompt of interest, given access to an imperfect reward model. We analyze the performance of inference-time alignment algorithms in terms of (i) response quality, and (ii) compute, and provide new results that highlight the importance of the pre-trained policy's coverage over high-quality responses for performance and compute scaling: 1. We show that Best-of-$N$ alignment with an ideal choice for $N$ can achieve optimal performance under stringent notions of coverage, but provably suffers from reward hacking when $N$ is large, and fails to achieve tight guarantees under more realistic coverage conditions. 2. We introduce $\texttt{InferenceTimePessimism}$, a new algorithm which mitigates reward hacking through deliberate use of inference-time compute, implementing the principle of pessimism in the face of uncertainty via rejection sampling; we prove that its performance is optimal and does not degrade with $N$, meaning it is scaling-monotonic. We complement our theoretical results with an experimental evaluation that demonstrate the benefits of $\texttt{InferenceTimePessimism}$ across a variety of tasks and models.
VUS: Effective and Efficient Accuracy Measures for Time-Series Anomaly Detection
Feb 18, 2025



Anomaly detection (AD) is a fundamental task for time-series analytics with important implications for the downstream performance of many applications. In contrast to other domains where AD mainly focuses on point-based anomalies (i.e., outliers in standalone observations), AD for time series is also concerned with range-based anomalies (i.e., outliers spanning multiple observations). Nevertheless, it is common to use traditional point-based information retrieval measures, such as Precision, Recall, and F-score, to assess the quality of methods by thresholding the anomaly score to mark each point as an anomaly or not. However, mapping discrete labels into continuous data introduces unavoidable shortcomings, complicating the evaluation of range-based anomalies. Notably, the choice of evaluation measure may significantly bias the experimental outcome. Despite over six decades of attention, there has never been a large-scale systematic quantitative and qualitative analysis of time-series AD evaluation measures. This paper extensively evaluates quality measures for time-series AD to assess their robustness under noise, misalignments, and different anomaly cardinality ratios. Our results indicate that measures producing quality values independently of a threshold (i.e., AUC-ROC and AUC-PR) are more suitable for time-series AD. Motivated by this observation, we first extend the AUC-based measures to account for range-based anomalies. Then, we introduce a new family of parameter-free and threshold-independent measures, Volume Under the Surface (VUS), to evaluate methods while varying parameters. We also introduce two optimized implementations for VUS that reduce significantly the execution time of the initial implementation. Our findings demonstrate that our four measures are significantly more robust in assessing the quality of time-series AD methods.
Dive into Time-Series Anomaly Detection: A Decade Review
Dec 29, 2024Recent advances in data collection technology, accompanied by the ever-rising volume and velocity of streaming data, underscore the vital need for time series analytics. In this regard, time-series anomaly detection has been an important activity, entailing various applications in fields such as cyber security, financial markets, law enforcement, and health care. While traditional literature on anomaly detection is centered on statistical measures, the increasing number of machine learning algorithms in recent years call for a structured, general characterization of the research methods for time-series anomaly detection. This survey groups and summarizes anomaly detection existing solutions under a process-centric taxonomy in the time series context. In addition to giving an original categorization of anomaly detection methods, we also perform a meta-analysis of the literature and outline general trends in time-series anomaly detection research.
Learning to Achieve Goals with Belief State Transformers
Oct 30, 2024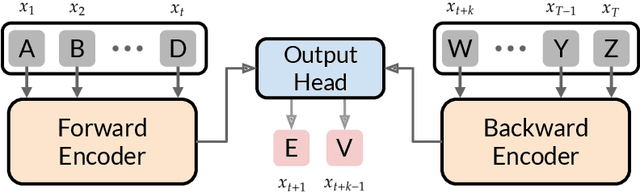
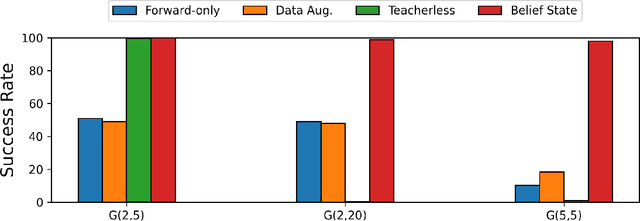
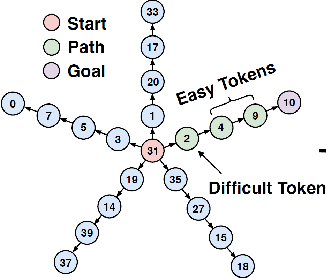
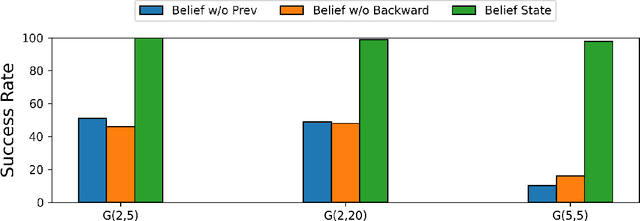
We introduce the "Belief State Transformer", a next-token predictor that takes both a prefix and suffix as inputs, with a novel objective of predicting both the next token for the prefix and the previous token for the suffix. The Belief State Transformer effectively learns to solve challenging problems that conventional forward-only transformers struggle with, in a domain-independent fashion. Key to this success is learning a compact belief state that captures all relevant information necessary for accurate predictions. Empirical ablations show that each component of the model is essential in difficult scenarios where standard Transformers fall short. For the task of story writing with known prefixes and suffixes, our approach outperforms the Fill-in-the-Middle method for reaching known goals and demonstrates improved performance even when the goals are unknown. Altogether, the Belief State Transformer enables more efficient goal-conditioned decoding, better test-time inference, and high-quality text representations on small scale problems.
On Limitation of Transformer for Learning HMMs
Jun 06, 2024Despite the remarkable success of Transformer-based architectures in various sequential modeling tasks, such as natural language processing, computer vision, and robotics, their ability to learn basic sequential models, like Hidden Markov Models (HMMs), is still unclear. This paper investigates the performance of Transformers in learning HMMs and their variants through extensive experimentation and compares them to Recurrent Neural Networks (RNNs). We show that Transformers consistently underperform RNNs in both training speed and testing accuracy across all tested HMM models. There are even challenging HMM instances where Transformers struggle to learn, while RNNs can successfully do so. Our experiments further reveal the relation between the depth of Transformers and the longest sequence length it can effectively learn, based on the types and the complexity of HMMs. To address the limitation of transformers in modeling HMMs, we demonstrate that a variant of the Chain-of-Thought (CoT), called $\textit{block CoT}$ in the training phase, can help transformers to reduce the evaluation error and to learn longer sequences at a cost of increasing the training time. Finally, we complement our empirical findings by theoretical results proving the expressiveness of transformers in approximating HMMs with logarithmic depth.
PIAVE: A Pose-Invariant Audio-Visual Speaker Extraction Network
Sep 13, 2023It is common in everyday spoken communication that we look at the turning head of a talker to listen to his/her voice. Humans see the talker to listen better, so do machines. However, previous studies on audio-visual speaker extraction have not effectively handled the varying talking face. This paper studies how to take full advantage of the varying talking face. We propose a Pose-Invariant Audio-Visual Speaker Extraction Network (PIAVE) that incorporates an additional pose-invariant view to improve audio-visual speaker extraction. Specifically, we generate the pose-invariant view from each original pose orientation, which enables the model to receive a consistent frontal view of the talker regardless of his/her head pose, therefore, forming a multi-view visual input for the speaker. Experiments on the multi-view MEAD and in-the-wild LRS3 dataset demonstrate that PIAVE outperforms the state-of-the-art and is more robust to pose variations.
* Interspeech 2023
Is RLHF More Difficult than Standard RL?
Jun 25, 2023
Reinforcement learning from Human Feedback (RLHF) learns from preference signals, while standard Reinforcement Learning (RL) directly learns from reward signals. Preferences arguably contain less information than rewards, which makes preference-based RL seemingly more difficult. This paper theoretically proves that, for a wide range of preference models, we can solve preference-based RL directly using existing algorithms and techniques for reward-based RL, with small or no extra costs. Specifically, (1) for preferences that are drawn from reward-based probabilistic models, we reduce the problem to robust reward-based RL that can tolerate small errors in rewards; (2) for general arbitrary preferences where the objective is to find the von Neumann winner, we reduce the problem to multiagent reward-based RL which finds Nash equilibria for factored Markov games under a restricted set of policies. The latter case can be further reduce to adversarial MDP when preferences only depend on the final state. We instantiate all reward-based RL subroutines by concrete provable algorithms, and apply our theory to a large class of models including tabular MDPs and MDPs with generic function approximation. We further provide guarantees when K-wise comparisons are available.