 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVUS: Effective and Efficient Accuracy Measures for Time-Series Anomaly Detection
Feb 18, 2025



Anomaly detection (AD) is a fundamental task for time-series analytics with important implications for the downstream performance of many applications. In contrast to other domains where AD mainly focuses on point-based anomalies (i.e., outliers in standalone observations), AD for time series is also concerned with range-based anomalies (i.e., outliers spanning multiple observations). Nevertheless, it is common to use traditional point-based information retrieval measures, such as Precision, Recall, and F-score, to assess the quality of methods by thresholding the anomaly score to mark each point as an anomaly or not. However, mapping discrete labels into continuous data introduces unavoidable shortcomings, complicating the evaluation of range-based anomalies. Notably, the choice of evaluation measure may significantly bias the experimental outcome. Despite over six decades of attention, there has never been a large-scale systematic quantitative and qualitative analysis of time-series AD evaluation measures. This paper extensively evaluates quality measures for time-series AD to assess their robustness under noise, misalignments, and different anomaly cardinality ratios. Our results indicate that measures producing quality values independently of a threshold (i.e., AUC-ROC and AUC-PR) are more suitable for time-series AD. Motivated by this observation, we first extend the AUC-based measures to account for range-based anomalies. Then, we introduce a new family of parameter-free and threshold-independent measures, Volume Under the Surface (VUS), to evaluate methods while varying parameters. We also introduce two optimized implementations for VUS that reduce significantly the execution time of the initial implementation. Our findings demonstrate that our four measures are significantly more robust in assessing the quality of time-series AD methods.
Understanding and Optimizing Packed Neural Network Training for Hyper-Parameter Tuning
Feb 07, 2020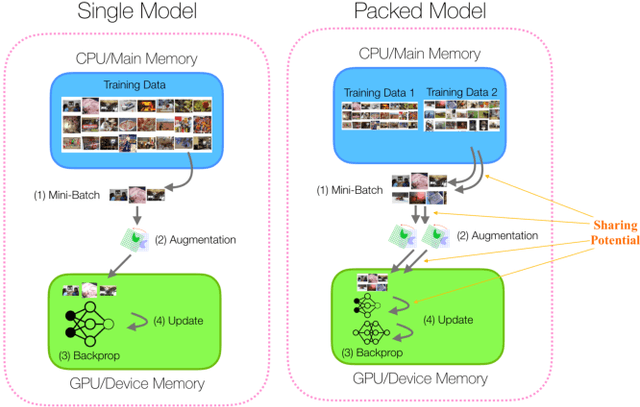
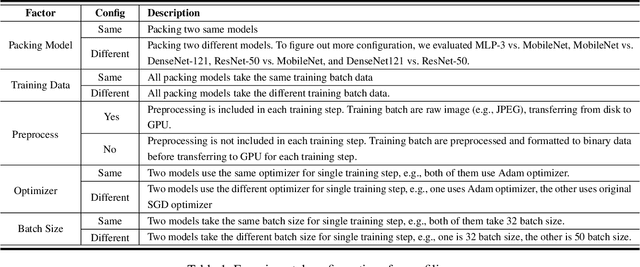
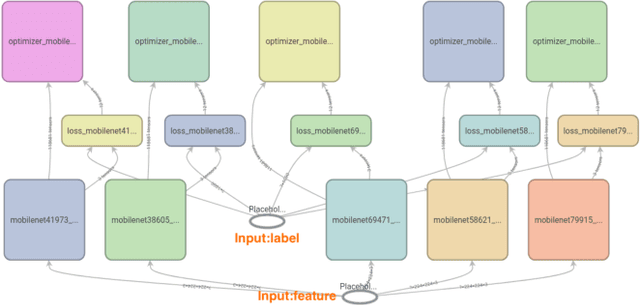
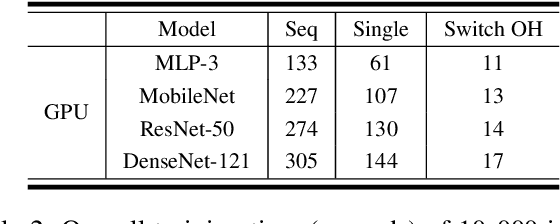
As neural networks are increasingly employed in machine learning practice, organizations will have to determine how to share limited training resources among a diverse set of model training tasks. This paper studies jointly training multiple neural network models on a single GPU. We presents an empirical study of this operation, called pack, and end-to-end experiments that suggest significant improvements for hyperparameter search systems. Our research prototype is in TensorFlow, and we evaluate performance across different models (ResNet, MobileNet, DenseNet, and MLP) and training scenarios. The results suggest: (1) packing two models can bring up to 40% performance improvement over unpacked setups for a single training step and the improvement increases when packing more models; (2) the benefit of a pack primitive largely depends on a number of factors including memory capacity, chip architecture, neural network structure, and batch size; (3) there exists a trade-off between packing and unpacking when training multiple neural network models on limited resources; (4) a pack-based Hyperband is up to 2.7x faster than the original Hyperband training method in our experiment setting, with this improvement growing as memory size increases and subsequently the density of models packed.
DLHub: Model and Data Serving for Science
Nov 27, 2018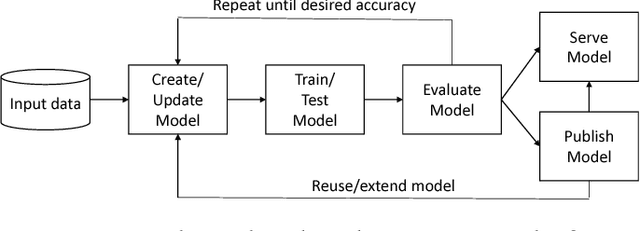
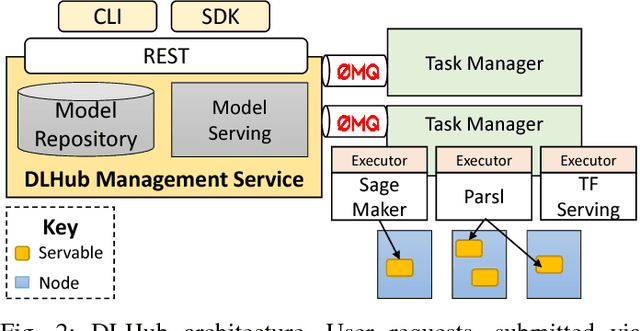
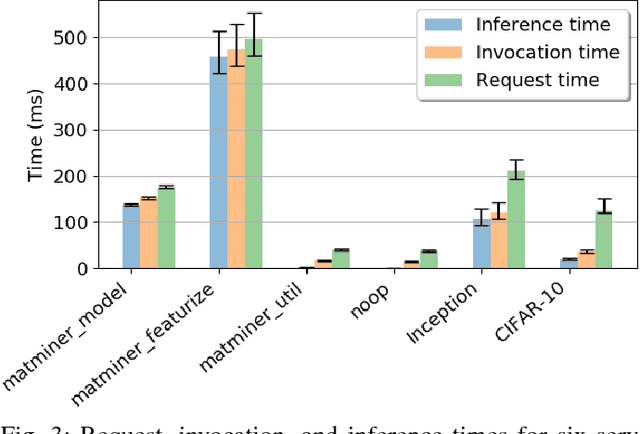
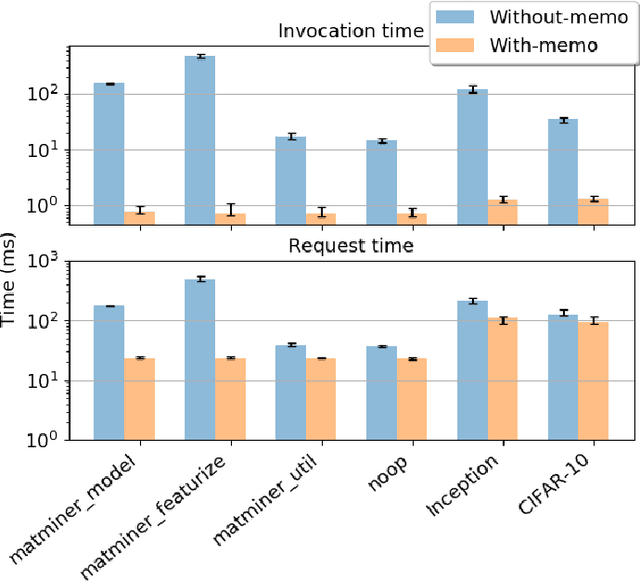
While the Machine Learning (ML) landscape is evolving rapidly, there has been a relative lag in the development of the "learning systems" needed to enable broad adoption. Furthermore, few such systems are designed to support the specialized requirements of scientific ML. Here we present the Data and Learning Hub for science (DLHub), a multi-tenant system that provides both model repository and serving capabilities with a focus on science applications. DLHub addresses two significant shortcomings in current systems. First, its selfservice model repository allows users to share, publish, verify, reproduce, and reuse models, and addresses concerns related to model reproducibility by packaging and distributing models and all constituent components. Second, it implements scalable and low-latency serving capabilities that can leverage parallel and distributed computing resources to democratize access to published models through a simple web interface. Unlike other model serving frameworks, DLHub can store and serve any Python 3-compatible model or processing function, plus multiple-function pipelines. We show that relative to other model serving systems including TensorFlow Serving, SageMaker, and Clipper, DLHub provides greater capabilities, comparable performance without memoization and batching, and significantly better performance when the latter two techniques can be employed. We also describe early uses of DLHub for scientific applications.
Clipper: A Low-Latency Online Prediction Serving System
Feb 28, 2017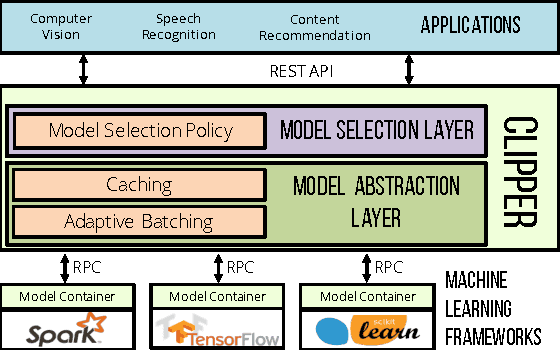
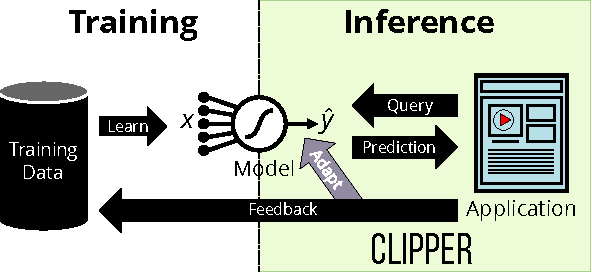

Machine learning is being deployed in a growing number of applications which demand real-time, accurate, and robust predictions under heavy query load. However, most machine learning frameworks and systems only address model training and not deployment. In this paper, we introduce Clipper, a general-purpose low-latency prediction serving system. Interposing between end-user applications and a wide range of machine learning frameworks, Clipper introduces a modular architecture to simplify model deployment across frameworks and applications. Furthermore, by introducing caching, batching, and adaptive model selection techniques, Clipper reduces prediction latency and improves prediction throughput, accuracy, and robustness without modifying the underlying machine learning frameworks. We evaluate Clipper on four common machine learning benchmark datasets and demonstrate its ability to meet the latency, accuracy, and throughput demands of online serving applications. Finally, we compare Clipper to the TensorFlow Serving system and demonstrate that we are able to achieve comparable throughput and latency while enabling model composition and online learning to improve accuracy and render more robust predictions.
KeystoneML: Optimizing Pipelines for Large-Scale Advanced Analytics
Oct 29, 2016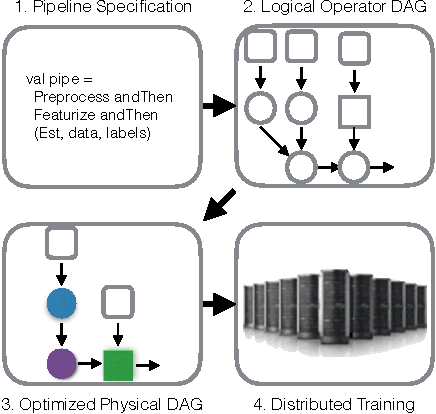


Modern advanced analytics applications make use of machine learning techniques and contain multiple steps of domain-specific and general-purpose processing with high resource requirements. We present KeystoneML, a system that captures and optimizes the end-to-end large-scale machine learning applications for high-throughput training in a distributed environment with a high-level API. This approach offers increased ease of use and higher performance over existing systems for large scale learning. We demonstrate the effectiveness of KeystoneML in achieving high quality statistical accuracy and scalable training using real world datasets in several domains. By optimizing execution KeystoneML achieves up to 15x training throughput over unoptimized execution on a real image classification application.
Scalable Linear Causal Inference for Irregularly Sampled Time Series with Long Range Dependencies
Mar 10, 2016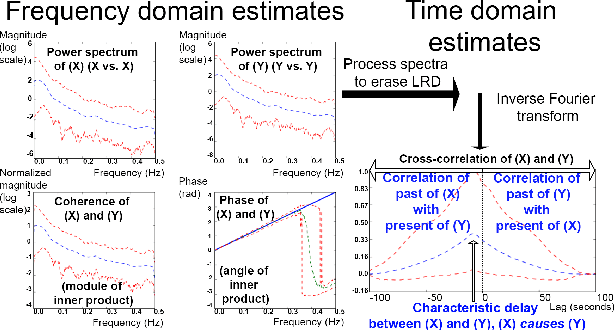
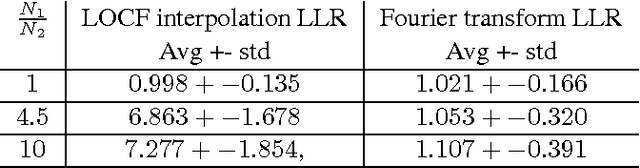
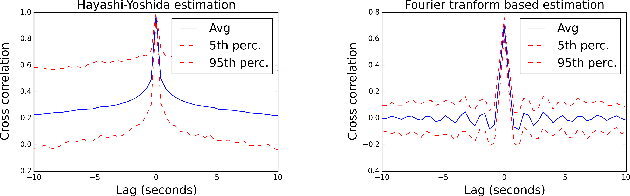
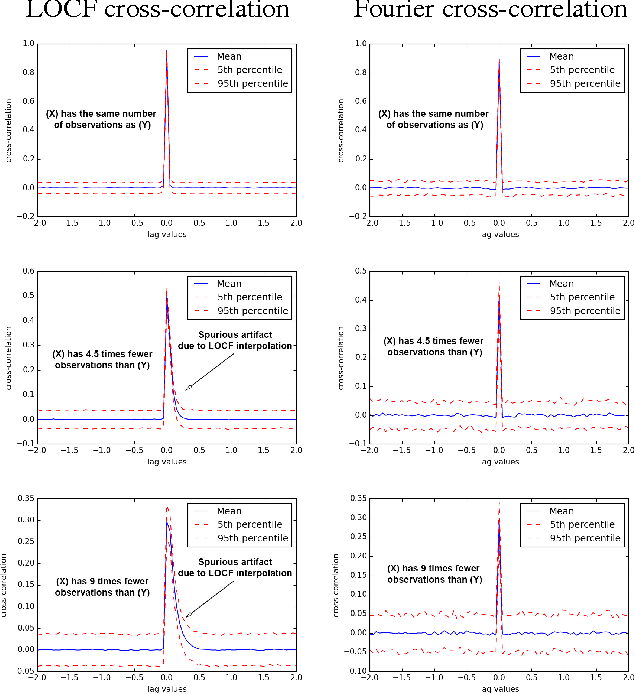
Linear causal analysis is central to a wide range of important application spanning finance, the physical sciences, and engineering. Much of the existing literature in linear causal analysis operates in the time domain. Unfortunately, the direct application of time domain linear causal analysis to many real-world time series presents three critical challenges: irregular temporal sampling, long range dependencies, and scale. Moreover, real-world data is often collected at irregular time intervals across vast arrays of decentralized sensors and with long range dependencies which make naive time domain correlation estimators spurious. In this paper we present a frequency domain based estimation framework which naturally handles irregularly sampled data and long range dependencies while enabled memory and communication efficient distributed processing of time series data. By operating in the frequency domain we eliminate the need to interpolate and help mitigate the effects of long range dependencies. We implement and evaluate our new work-flow in the distributed setting using Apache Spark and demonstrate on both Monte Carlo simulations and high-frequency financial trading that we can accurately recover causal structure at scale.
ActiveClean: Interactive Data Cleaning While Learning Convex Loss Models
Jan 15, 2016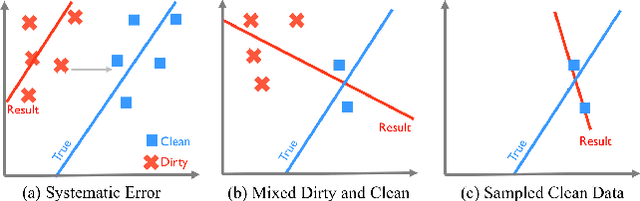
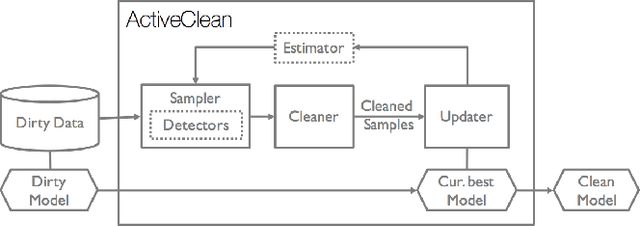
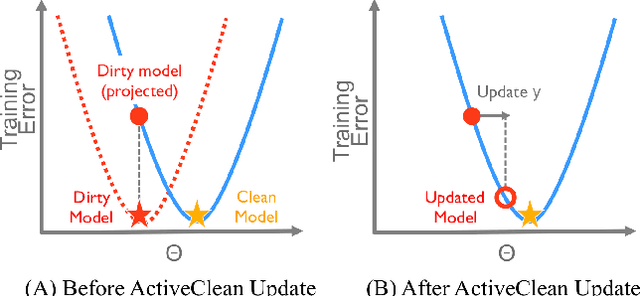
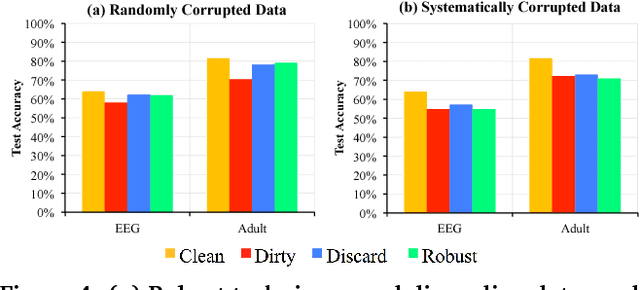
Data cleaning is often an important step to ensure that predictive models, such as regression and classification, are not affected by systematic errors such as inconsistent, out-of-date, or outlier data. Identifying dirty data is often a manual and iterative process, and can be challenging on large datasets. However, many data cleaning workflows can introduce subtle biases into the training processes due to violation of independence assumptions. We propose ActiveClean, a progressive cleaning approach where the model is updated incrementally instead of re-training and can guarantee accuracy on partially cleaned data. ActiveClean supports a popular class of models called convex loss models (e.g., linear regression and SVMs). ActiveClean also leverages the structure of a user's model to prioritize cleaning those records likely to affect the results. We evaluate ActiveClean on five real-world datasets UCI Adult, UCI EEG, MNIST, Dollars For Docs, and WorldBank with both real and synthetic errors. Our results suggest that our proposed optimizations can improve model accuracy by up-to 2.5x for the same amount of data cleaned. Furthermore for a fixed cleaning budget and on all real dirty datasets, ActiveClean returns more accurate models than uniform sampling and Active Learning.
MLlib: Machine Learning in Apache Spark
May 26, 2015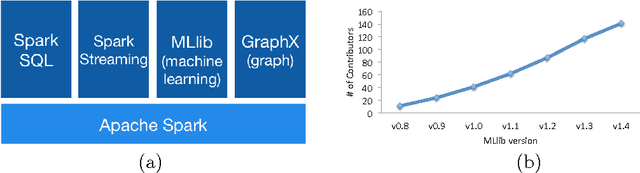
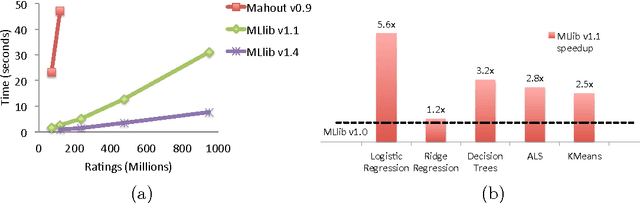
Apache Spark is a popular open-source platform for large-scale data processing that is well-suited for iterative machine learning tasks. In this paper we present MLlib, Spark's open-source distributed machine learning library. MLlib provides efficient functionality for a wide range of learning settings and includes several underlying statistical, optimization, and linear algebra primitives. Shipped with Spark, MLlib supports several languages and provides a high-level API that leverages Spark's rich ecosystem to simplify the development of end-to-end machine learning pipelines. MLlib has experienced a rapid growth due to its vibrant open-source community of over 140 contributors, and includes extensive documentation to support further growth and to let users quickly get up to speed.
TuPAQ: An Efficient Planner for Large-scale Predictive Analytic Queries
Mar 08, 2015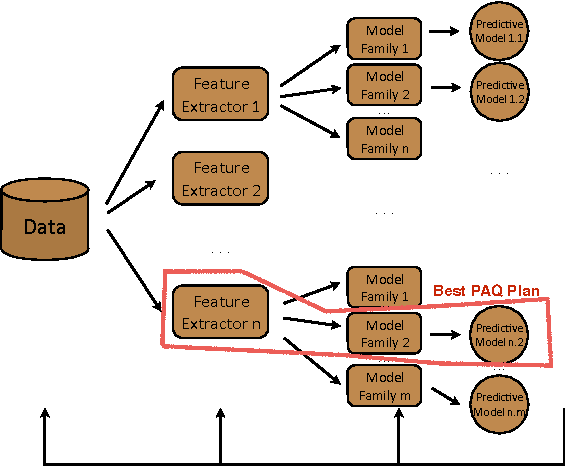
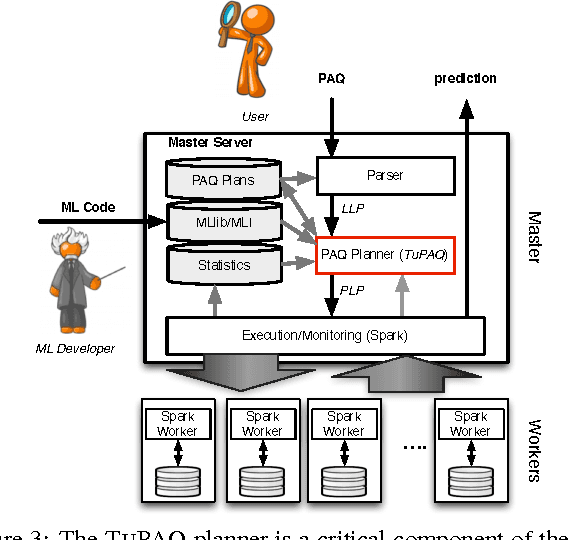
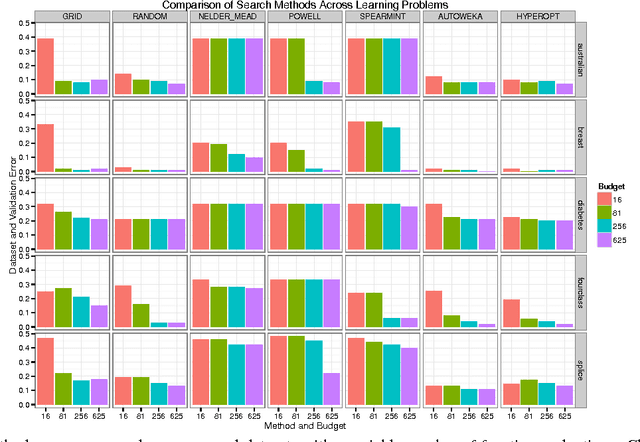
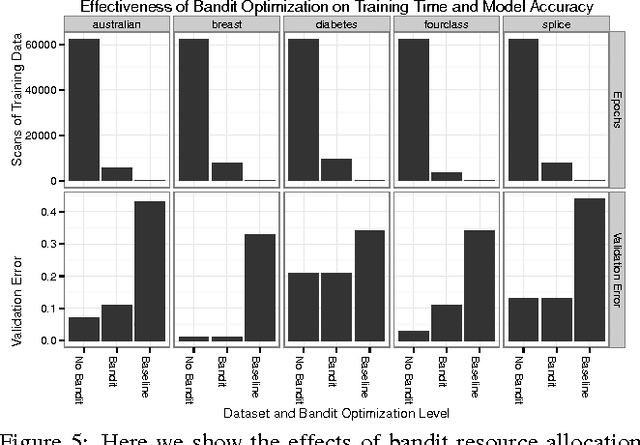
The proliferation of massive datasets combined with the development of sophisticated analytical techniques have enabled a wide variety of novel applications such as improved product recommendations, automatic image tagging, and improved speech-driven interfaces. These and many other applications can be supported by Predictive Analytic Queries (PAQs). A major obstacle to supporting PAQs is the challenging and expensive process of identifying and training an appropriate predictive model. Recent efforts aiming to automate this process have focused on single node implementations and have assumed that model training itself is a black box, thus limiting the effectiveness of such approaches on large-scale problems. In this work, we build upon these recent efforts and propose an integrated PAQ planning architecture that combines advanced model search techniques, bandit resource allocation via runtime algorithm introspection, and physical optimization via batching. The result is TuPAQ, a component of the MLbase system, which solves the PAQ planning problem with comparable quality to exhaustive strategies but an order of magnitude more efficiently than the standard baseline approach, and can scale to models trained on terabytes of data across hundreds of machines.
Active Learning for Crowd-Sourced Databases
Dec 20, 2014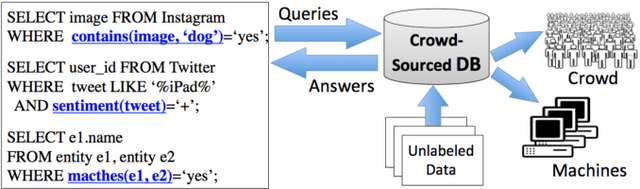

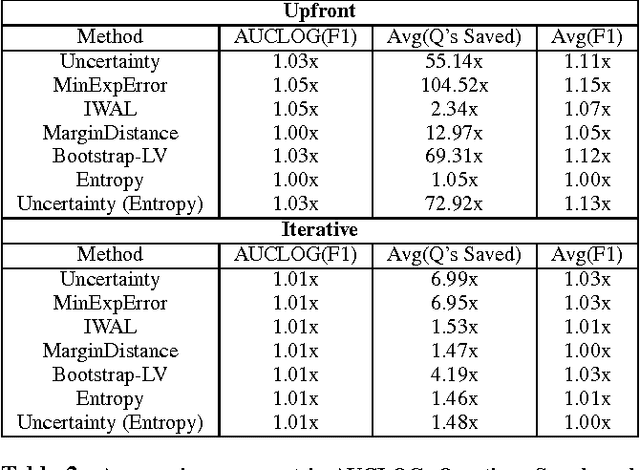
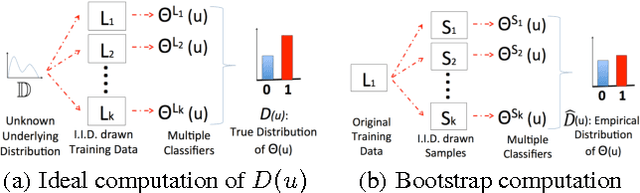
Crowd-sourcing has become a popular means of acquiring labeled data for a wide variety of tasks where humans are more accurate than computers, e.g., labeling images, matching objects, or analyzing sentiment. However, relying solely on the crowd is often impractical even for data sets with thousands of items, due to time and cost constraints of acquiring human input (which cost pennies and minutes per label). In this paper, we propose algorithms for integrating machine learning into crowd-sourced databases, with the goal of allowing crowd-sourcing applications to scale, i.e., to handle larger datasets at lower costs. The key observation is that, in many of the above tasks, humans and machine learning algorithms can be complementary, as humans are often more accurate but slow and expensive, while algorithms are usually less accurate, but faster and cheaper. Based on this observation, we present two new active learning algorithms to combine humans and algorithms together in a crowd-sourced database. Our algorithms are based on the theory of non-parametric bootstrap, which makes our results applicable to a broad class of machine learning models. Our results, on three real-life datasets collected with Amazon's Mechanical Turk, and on 15 well-known UCI data sets, show that our methods on average ask humans to label one to two orders of magnitude fewer items to achieve the same accuracy as a baseline that labels random images, and two to eight times fewer questions than previous active learning schemes.